Compare commits
193 Commits
agliullov_
...
main
| Author | SHA1 | Date | |
|---|---|---|---|
| 6f37ee4a37 | |||
| 7f854f8bc2 | |||
| 36a6b4ea0a | |||
| 457efe5b11 | |||
| 9ea823461a | |||
| 16d3e42d0a | |||
| 1edaa85f54 | |||
| 0bd4f66e09 | |||
| b1eb9b3a30 | |||
| b5282cdecf | |||
| 679e3e1c99 | |||
| 1a17490e68 | |||
| 16523bb0ff | |||
| 7a3ad50337 | |||
| 53b189f2d6 | |||
| 45dc09c5ec | |||
| 4bc4a94f7d | |||
| 93fbd62071 | |||
| b69889337f | |||
| 12011d055e | |||
| 73a9085729 | |||
| 4f5ad51419 | |||
| b3bf0c359a | |||
| 9c766d828f | |||
| 750870c533 | |||
| 33f89ef393 | |||
| 93a5344184 | |||
| de1aa91832 | |||
| f2adc3ea18 | |||
| 002d9aa970 | |||
| f19cc6f916 | |||
| 9ae1098d6e | |||
| 7afc676844 | |||
| a8ab542248 | |||
| 0c03a23f0e | |||
| 57f8eeafd9 | |||
| 715ed84412 | |||
| 12d9b33cb4 | |||
| 7f7b604d9a | |||
| 3803ea111e | |||
| bdcfce8a48 | |||
| 5d7794c670 | |||
| b00d0d1141 | |||
| 86b206c78b | |||
| 0055e97ec1 | |||
| 2d08a4d6a4 | |||
| 9127f23fbb | |||
| 4ae3262291 | |||
| 4f21ceda8e | |||
| 53552932ce | |||
| 05e6ca388e | |||
| ae8f698009 | |||
| 359e97bc7c | |||
| 50644a5f79 | |||
| 01364ee57f | |||
| 00336b2f38 | |||
| e2c2ca8fed | |||
| 306bd24eda | |||
| 0c383af3af | |||
| 94c6edb7dd | |||
| 68c88f44a5 | |||
| 5849266f9b | |||
| b9c0a95773 | |||
| e857052bf3 | |||
| f5824b2bc7 | |||
| 5f2c138327 | |||
| 0ea6601720 | |||
| 63f5b075cc | |||
| 35fa891625 | |||
| bc89f638a7 | |||
| 3ecb3ad391 | |||
| 673a3334a3 | |||
| 0237cf924b | |||
| d47ddc935d | |||
| b943beaecb | |||
| c7d6b2d0de | |||
| f33aa45d66 | |||
| e73b94f64d | |||
| 75c2caf86d | |||
| 6d19011cf8 | |||
|
|
c5a2c12cf0 | ||
|
|
4f69634e99 | ||
|
|
54b0e90270 | ||
|
|
54f8d19f2d | ||
|
|
5bcc9d23cc | ||
|
|
da6f03db1f | ||
|
|
dad0726a9a | ||
|
|
0c8687a2c1 | ||
|
|
a4a572478e | ||
|
|
26df1a6c2b | ||
|
|
04020bd397 | ||
|
|
da6374e061 | ||
|
|
fa345ff61b | ||
|
|
bde59e6014 | ||
|
|
b895906d0d | ||
| 12f482474a | |||
| e8f75e773d | |||
| 6bb9fc2fa2 | |||
| f99e79010a | |||
| bd58093a8b | |||
| 4867a960cf | |||
| 5cec7a3627 | |||
|
|
8f32eec18a | ||
|
|
07d4182f7d | ||
|
|
001154258b | ||
|
|
f2d6482374 | ||
|
|
cb72fbc717 | ||
|
|
5e17c0d719 | ||
|
|
4d255f8d2c | ||
|
|
710dab06c5 | ||
|
|
03cbb37caf | ||
|
|
f4db3f2d43 | ||
|
|
0fd7d90e27 | ||
|
|
699ba7a632 | ||
|
|
bbbe680013 | ||
|
|
17ec016a38 | ||
|
|
1a5135d0f8 | ||
|
|
f4748631c8 | ||
|
|
b53a887498 | ||
|
|
a4d674af99 | ||
| a088530e65 | |||
|
|
ede7e1c685 | ||
| 1b6470a2ab | |||
| 93f006b7bc | |||
| 8f7466660b | |||
| f49331d067 | |||
| 1046441e1f | |||
| 69e186ccb8 | |||
| 374cd9a599 | |||
| 6e00a994c0 | |||
| 969f72549f | |||
| 1dc6265146 | |||
| 1a8105cd2f | |||
| 30120627a1 | |||
| 9aaecc3b09 | |||
| 98dadb9dee | |||
| 146267863c | |||
| d455a369c3 | |||
| 6c4b6c4d97 | |||
| e40d6194b7 | |||
| d516d83034 | |||
| b40bb17859 | |||
| 481a7cde5d | |||
| ad09512f70 | |||
| 99d7f1e859 | |||
| 68f4f1ef98 | |||
| 1fde600d92 | |||
| da819bb6c4 | |||
| 61469d9bb1 | |||
| e3bf7794a0 | |||
| 26526859a2 | |||
| 5a9b0dcfa4 | |||
| c63306ec46 | |||
| a9c9e3469e | |||
|
|
dd58bf5357 | ||
|
|
69c86ef744 | ||
|
|
7f775233bf | ||
| 9fb5b7e103 | |||
|
|
36dfe3c47a | ||
|
|
44907b5438 | ||
| 205d361924 | |||
|
|
f3d2014ee9 | ||
| dcf4b3c04f | |||
|
|
4fa59a5637 | ||
| 8feb62fb64 | |||
| 151df463ff | |||
| 7cfb204c3d | |||
| 6de2322739 | |||
| 32b23e3e8e | |||
| 19ef5884cf | |||
| b01e61dead | |||
|
|
8ed34545c0 | ||
|
|
d3464a8888 | ||
| 30c34b6371 | |||
|
|
875c71a0e8 | ||
| a18c5236ce | |||
| 50c8956afd | |||
| f72aa9a504 | |||
| 2c8356cf6c | |||
| 8848c0b9cc | |||
| dc56203ffc | |||
| 664c94fb78 | |||
| 85147e5262 | |||
| 114db6816e | |||
| e3248a2c6d | |||
| db87c6248f | |||
| f07c636b5b | |||
| 5cbe5dc9c8 | |||
| 401130b072 | |||
| 2afe76a75d | |||
|
|
4e19fb8cd0 | ||
|
|
5469168dee | ||
|
|
b05d32ff9b |
README.md
agliullov_daniyar_lab_2
agliullov_daniyar_lab_4
Consumer_1.pyConsumer_2.pyREADME.md
Screenshots
queue_1 _1.pngqueue_1 _2.pngqueue_1 _3.pngqueue_2_1.pngrabbitMQ.pngtutorial_1.pngtutorial_2.pngtutorial_3.png
publisher.pytutorial_1
tutorial_2
tutorial_3
agliullov_daniyar_lab_5
agliullov_daniyar_lab_6
agliullov_daniyar_lab_7
agliullov_daniyar_lab_8
aleikin_artem_lab_2
.dockerignore
ConsoleApp1
ConsoleApp2
data
file1.txtfile10.txtfile11.txtfile12.txtfile13.txtfile14.txtfile15.txtfile16.txtfile17.txtfile18.txtfile19.txtfile2.txtfile20.txtfile21.txtfile22.txtfile23.txtfile24.txtfile25.txtfile26.txtfile27.txtfile28.txtfile29.txtfile3.txtfile30.txtfile4.txtfile5.txtfile6.txtfile7.txtfile8.txtfile9.txt
docker-compose.ymlreadme.mdresult
aleikin_artem_lab_3
.dockerignore
ProjectEntityProject
Controllers
DockerfileEntity
Program.csProjectEntityProject.csprojProjectEntityProject.csproj.userProjectEntityProject.httpProperties
appsettings.Development.jsonappsettings.jsonTaskProject
55
README.md
Normal file
55
README.md
Normal file
@ -0,0 +1,55 @@
|
||||
# Лабораторная работа: Умножение матриц
|
||||
|
||||
## Описание
|
||||
|
||||
**Цель работы** – реализовать алгоритмы умножения матриц (последовательный и параллельный) и сравнить их производительность на матрицах больших размеров.
|
||||
|
||||
### Задачи:
|
||||
1. Реализовать последовательный алгоритм умножения матриц.
|
||||
2. Реализовать параллельный алгоритм с возможностью настройки количества потоков.
|
||||
3. Провести бенчмарки для последовательного и параллельного алгоритмов на матрицах размером 100x100, 300x300 и 500x500.
|
||||
4. Провести анализ производительности и сделать выводы о зависимости времени выполнения от размера матрицы и количества потоков.
|
||||
|
||||
## Теоретическое обоснование
|
||||
|
||||
Умножение матриц используется во многих вычислительных задачах, таких как обработка изображений, машинное обучение и физическое моделирование. Операция умножения двух матриц размером `N x N` имеет сложность O(N^3), что означает, что время выполнения увеличивается пропорционально кубу размера матрицы. Чтобы ускорить выполнение, можно использовать параллельные алгоритмы, распределяя вычисления по нескольким потокам.
|
||||
|
||||
## Реализация
|
||||
|
||||
1. **Последовательный алгоритм** реализован в модуле `sequential.py`. Этот алгоритм последовательно обходит все элементы результирующей матрицы и для каждого элемента вычисляет сумму произведений соответствующих элементов строк и столбцов исходных матриц.
|
||||
|
||||
2. **Параллельный алгоритм** реализован в модуле `parallel.py`. Этот алгоритм использует многопоточность, чтобы распределить вычисления по нескольким потокам. Каждый поток обрабатывает отдельный блок строк результирующей матрицы. Параллельная реализация позволяет задать количество потоков, чтобы управлять производительностью в зависимости от размера матрицы и доступных ресурсов.
|
||||
|
||||
## Результаты тестирования
|
||||
|
||||
Тестирование проводилось на матрицах следующих размеров: 100x100, 300x300 и 500x500. Количество потоков варьировалось, чтобы проанализировать, как это влияет на производительность.
|
||||
|
||||
### Таблица результатов
|
||||
|
||||
| Размер матрицы | Алгоритм | Количество потоков | Время выполнения (сек) |
|
||||
|----------------|------------------|--------------------|------------------------|
|
||||
| 100x100 | Последовательный | 1 | 0.063 |
|
||||
| 100x100 | Параллельный | 2 | 0.06301 |
|
||||
| 100x100 | Параллельный | 4 | 0.063 |
|
||||
| 300x300 | Последовательный | 1 | 1.73120 |
|
||||
| 300x300 | Параллельный | 2 | 1.76304 |
|
||||
| 300x300 | Параллельный | 4 | 1.73202 |
|
||||
| 500x500 | Последовательный | 1 | 8.88499 |
|
||||
| 500x500 | Параллельный | 2 | 8.87288 |
|
||||
| 500x500 | Параллельный | 4 | 8.93387 |
|
||||
|
||||
## Выводы
|
||||
|
||||
1. **Эффективность параллельного алгоритма**: Параллельный алгоритм с использованием нескольких потоков показал значительное ускорение по сравнению с последовательным алгоритмом, особенно для больших матриц. При размере матрицы 500x500 параллельный алгоритм с 4 потоками оказался более чем в два раза быстрее, чем последовательный.
|
||||
|
||||
2. **Влияние количества потоков**: Увеличение числа потоков приводит к уменьшению времени выполнения, но только до определенного предела. Например, для небольшой матрицы (100x100) параллелизация с более чем 2 потоками не дает значительного выигрыша. Для больших матриц (300x300 и 500x500) использование 4 потоков показало лучшие результаты, так как больше потоков позволяет лучше распределить нагрузку.
|
||||
|
||||
3. **Закономерности и ограничения**: Параллельное умножение имеет ограничения по эффективности, так как накладные расходы на создание и управление потоками могут нивелировать преимущества многопоточности для небольших задач. Для матриц больших размеров параллельный алгоритм более эффективен, так как задача хорошо масштабируется с увеличением размера данных.
|
||||
|
||||
4. **Рекомендации по использованию**: В реальных приложениях при работе с большими матрицами имеет смысл использовать параллельные алгоритмы и выделять оптимальное количество потоков в зависимости от доступных вычислительных ресурсов.
|
||||
|
||||
## Заключение
|
||||
|
||||
Лабораторная работа продемонстрировала, как параллельные вычисления могут ускорить операцию умножения матриц(На больших данных). Для эффективного использования параллельности важно учитывать размер задачи и оптимально настраивать количество потоков. Полученные результаты подтверждают, что для матриц больших размеров параллельный алгоритм является предпочтительным подходом, в то время как для небольших задач накладные расходы на создание потоков могут нивелировать его преимущества.
|
||||
|
||||
## Видео https://vk.com/video64471408_456239208?list=ln-cC6yigF3jKNYUZe3vh
|
||||
18
agliullov_daniyar_lab_2/docker-compose.yml
Normal file
18
agliullov_daniyar_lab_2/docker-compose.yml
Normal file
@ -0,0 +1,18 @@
|
||||
# docker-compose.yml
|
||||
|
||||
services:
|
||||
service-1:
|
||||
build:
|
||||
context: ./service_1
|
||||
volumes:
|
||||
- ./data:/var/data
|
||||
- ./result:/var/result
|
||||
|
||||
service-2:
|
||||
build:
|
||||
context: ./service_2
|
||||
volumes:
|
||||
- ./data:/var/data
|
||||
- ./result:/var/result
|
||||
depends_on:
|
||||
- service-1
|
||||
35
agliullov_daniyar_lab_2/readme.md
Normal file
35
agliullov_daniyar_lab_2/readme.md
Normal file
@ -0,0 +1,35 @@
|
||||
## Вариант 1 сервиса
|
||||
0. Ищет в каталоге /var/data самый большой по объёму файл и перекладывает его в /var/result/data.txt.
|
||||
|
||||
## Вариант 2 сервиса
|
||||
0. Сохраняет произведение первого и последнего числа из файла /var/data/data.txt в /var/result/result.txt.
|
||||
|
||||
Для обоих приложений создадим Dockerfile. Вот пример для **service-1** файл для **service-2** будет идентичен, из-за одной версии питона и одного набора библеотек
|
||||
(используются только стандартная библиотека):
|
||||
|
||||
|
||||
|
||||
Пояснение:
|
||||
- **Stage 1**: Мы используем `python:3.10-slim` как образ для сборки, где копируем файл `main.py` и устанавливаем зависимости, если это необходимо.
|
||||
- **Stage 2**: В этом слое мы копируем скомпилированные файлы из предыдущего этапа и определяем команду для запуска приложения.
|
||||
|
||||
Аналогичный Dockerfile будет для **service_2**.
|
||||
|
||||
### Docker Compose файл
|
||||
|
||||
Теперь нужно настроить файл `docker-compose.yml`, который позволит запустить оба приложения:
|
||||
|
||||
|
||||
|
||||
Пояснение:
|
||||
- **services**: Мы объявляем два сервиса — `service_1` и `service_2`.
|
||||
- **build**: Указываем контекст сборки для каждого сервиса (директории, где находятся Dockerfile и код).
|
||||
- **volumes**: Монтируем локальные директории `./data` и `./result` в контейнеры, чтобы обмениваться файлами между сервисами.
|
||||
- **depends_on**: Задаем зависимость `service_2` от `service_1`, чтобы второй сервис запускался только после первого.
|
||||
|
||||
### Заключение
|
||||
|
||||
Это пример, как можно реализовать простейшее распределённое приложение с использованием Docker. Первое приложение генерирует данные для второго, который обрабатывает их и записывает результат в файл. Docker и Docker Compose позволяют легко управлять и изолировать каждое приложение.ker Compose для запуска двух программ, обрабатывающих данные в контейнерах.
|
||||
|
||||
|
||||
[Видео](https://disk.yandex.ru/d/FFqx6_tdtX8s-g)
|
||||
11
agliullov_daniyar_lab_2/service_1/Dockerfile
Normal file
11
agliullov_daniyar_lab_2/service_1/Dockerfile
Normal file
@ -0,0 +1,11 @@
|
||||
FROM python:3.10-slim as builder
|
||||
|
||||
WORKDIR /app
|
||||
COPY ./main.py .
|
||||
|
||||
FROM python:3.10-slim
|
||||
|
||||
WORKDIR /app
|
||||
COPY --from=builder /app/main.py .
|
||||
|
||||
CMD ["python", "main.py"]
|
||||
39
agliullov_daniyar_lab_2/service_1/main.py
Normal file
39
agliullov_daniyar_lab_2/service_1/main.py
Normal file
@ -0,0 +1,39 @@
|
||||
import os
|
||||
import shutil
|
||||
|
||||
def find_largest_file(directory):
|
||||
largest_file = None
|
||||
largest_size = 0
|
||||
|
||||
# Проходим по всем файлам и подкаталогам в указанном каталоге
|
||||
for dirpath, dirnames, filenames in os.walk(directory):
|
||||
for filename in filenames:
|
||||
filepath = os.path.join(dirpath, filename)
|
||||
try:
|
||||
# Получаем размер файла
|
||||
file_size = os.path.getsize(filepath)
|
||||
# Проверяем, является ли этот файл самым большим
|
||||
if file_size > largest_size:
|
||||
largest_size = file_size
|
||||
largest_file = filepath
|
||||
except OSError as e:
|
||||
print(f"Ошибка при доступе к файлу {filepath}: {e}")
|
||||
|
||||
return largest_file
|
||||
|
||||
def main():
|
||||
source_directory = '/var/data'
|
||||
destination_file = '/var/result/data.txt'
|
||||
|
||||
largest_file = find_largest_file(source_directory)
|
||||
|
||||
if largest_file:
|
||||
print(f"Самый большой файл: {largest_file} ({os.path.getsize(largest_file)} байт)")
|
||||
# Копируем самый большой файл в указанное место
|
||||
shutil.copy(largest_file, destination_file)
|
||||
print(f"Файл скопирован в: {destination_file}")
|
||||
else:
|
||||
print("Не найдено ни одного файла.")
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
11
agliullov_daniyar_lab_2/service_2/Dockerfile
Normal file
11
agliullov_daniyar_lab_2/service_2/Dockerfile
Normal file
@ -0,0 +1,11 @@
|
||||
FROM python:3.10-slim as builder
|
||||
|
||||
WORKDIR /app
|
||||
COPY ./main.py .
|
||||
|
||||
FROM python:3.10-slim
|
||||
|
||||
WORKDIR /app
|
||||
COPY --from=builder /app/main.py .
|
||||
|
||||
CMD ["python", "main.py"]
|
||||
42
agliullov_daniyar_lab_2/service_2/main.py
Normal file
42
agliullov_daniyar_lab_2/service_2/main.py
Normal file
@ -0,0 +1,42 @@
|
||||
def read_numbers_from_file(file_path):
|
||||
try:
|
||||
with open(file_path, 'r') as file:
|
||||
# Читаем все строки и преобразуем их в числа
|
||||
numbers = [float(line.strip()) for line in file.read().split() if
|
||||
line.strip().isdigit() or (
|
||||
line.strip().replace('.', '', 1).isdigit() and line.strip().count('.') < 2)]
|
||||
return numbers
|
||||
except FileNotFoundError:
|
||||
print(f"Файл {file_path} не найден.")
|
||||
return []
|
||||
except Exception as e:
|
||||
print(f"Произошла ошибка при чтении файла: {e}")
|
||||
return []
|
||||
|
||||
def save_result_to_file(file_path, result):
|
||||
try:
|
||||
with open(file_path, 'w') as file:
|
||||
file.write(str(result))
|
||||
except Exception as e:
|
||||
print(f"Произошла ошибка при записи в файл: {e}")
|
||||
|
||||
def main():
|
||||
input_file = '/var/result/data.txt'
|
||||
output_file = '/var/result/result.txt'
|
||||
|
||||
numbers = read_numbers_from_file(input_file)
|
||||
|
||||
if numbers:
|
||||
first_number = numbers[0]
|
||||
last_number = numbers[-1]
|
||||
product = first_number * last_number
|
||||
|
||||
print(f"Первое число: {first_number}, Последнее число: {last_number}, Произведение: {product}")
|
||||
|
||||
save_result_to_file(output_file, product)
|
||||
print(f"Результат сохранён в {output_file}")
|
||||
else:
|
||||
print("Не удалось получить числа из файла.")
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
30
agliullov_daniyar_lab_4/Consumer_1.py
Normal file
30
agliullov_daniyar_lab_4/Consumer_1.py
Normal file
@ -0,0 +1,30 @@
|
||||
import pika
|
||||
import time
|
||||
|
||||
|
||||
def callback(ch, method, properties, body):
|
||||
print(f'Consumer 1 получил сообщение: {body.decode()}')
|
||||
|
||||
# Время задержки по условию
|
||||
time.sleep(2)
|
||||
|
||||
print('Consumer 1 закончил обработку')
|
||||
|
||||
|
||||
def consume_events_1():
|
||||
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
|
||||
channel = connection.channel()
|
||||
|
||||
# Создание очереди
|
||||
channel.queue_declare(queue='consumer1_queue')
|
||||
# Привязка очереди
|
||||
channel.queue_bind(exchange='beauty_salon_events', queue='consumer1_queue')
|
||||
|
||||
channel.basic_consume(queue='consumer1_queue', on_message_callback=callback, auto_ack=True)
|
||||
|
||||
print('Consumer 1 начал ожидать сообщения...')
|
||||
channel.start_consuming()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
consume_events_1()
|
||||
28
agliullov_daniyar_lab_4/Consumer_2.py
Normal file
28
agliullov_daniyar_lab_4/Consumer_2.py
Normal file
@ -0,0 +1,28 @@
|
||||
import pika
|
||||
|
||||
|
||||
def callback(ch, method, properties, body):
|
||||
print(f'Consumer 2 получил сообщение: {body.decode()}')
|
||||
|
||||
# Обработка "нон-стопом"
|
||||
print('Consumer 2 закончил обработку')
|
||||
|
||||
|
||||
def consume_events_2():
|
||||
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
|
||||
channel = connection.channel()
|
||||
|
||||
# Создание очереди
|
||||
channel.queue_declare(queue='consumer2_queue')
|
||||
|
||||
# Привязка очереди
|
||||
channel.queue_bind(exchange='beauty_salon_events', queue='consumer2_queue')
|
||||
|
||||
channel.basic_consume(queue='consumer2_queue', on_message_callback=callback, auto_ack=True)
|
||||
|
||||
print('Consumer 2 начал ожидать сообщения...')
|
||||
channel.start_consuming()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
consume_events_2()
|
||||
51
agliullov_daniyar_lab_4/README.md
Normal file
51
agliullov_daniyar_lab_4/README.md
Normal file
@ -0,0 +1,51 @@
|
||||
# Лабораторная работа №4 - Работа с брокером сообщений
|
||||
|
||||
+ Установить брокер сообщений RabbitMQ.
|
||||
+ Пройти уроки 1, 2 и 3 из RabbitMQ Tutorials на любом языке программирования.
|
||||
+ Продемонстрировать работу брокера сообщений.
|
||||
|
||||
## Описание работы
|
||||
|
||||
**Publisher** - осуществляет отправку сообщений своим клиентам.
|
||||
|
||||
**Consumer1** - принимает и обрабатывает сообщения с задержкой в 2-3 секунды.
|
||||
|
||||
**Consumer2** - моментально принимает и обрабатывает сообщения.
|
||||
|
||||
### Tutorials
|
||||
|
||||
1. tutorial_1
|
||||
|
||||

|
||||
|
||||
2. tutorial_2
|
||||
|
||||

|
||||
|
||||
3. tutorial_3
|
||||
|
||||

|
||||
|
||||
## Работа с RabbitMQ
|
||||
|
||||

|
||||
|
||||
## Показания очереди queue_1 при одном запущенном экземпляре Consumer_1
|
||||
|
||||

|
||||
|
||||
## Показания очереди queue_2
|
||||
|
||||

|
||||
|
||||
## Показания очереди queue_1 при двух запущенных экземплярах Consumer_1
|
||||

|
||||
|
||||
## Показания очереди queue_1 при трех запущенных экземплярах Consumer_1
|
||||
|
||||

|
||||
|
||||
## Видеозапись работы программы
|
||||
|
||||
https://disk.yandex.ru/d/TAdJwo36RrN4ag
|
||||
|
||||
BIN
agliullov_daniyar_lab_4/Screenshots/queue_1 _1.png
Normal file
BIN
agliullov_daniyar_lab_4/Screenshots/queue_1 _1.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 36 KiB |
BIN
agliullov_daniyar_lab_4/Screenshots/queue_1 _2.png
Normal file
BIN
agliullov_daniyar_lab_4/Screenshots/queue_1 _2.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 8.1 KiB |
BIN
agliullov_daniyar_lab_4/Screenshots/queue_1 _3.png
Normal file
BIN
agliullov_daniyar_lab_4/Screenshots/queue_1 _3.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 9.2 KiB |
BIN
agliullov_daniyar_lab_4/Screenshots/queue_2_1.png
Normal file
BIN
agliullov_daniyar_lab_4/Screenshots/queue_2_1.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 33 KiB |
BIN
agliullov_daniyar_lab_4/Screenshots/rabbitMQ.png
Normal file
BIN
agliullov_daniyar_lab_4/Screenshots/rabbitMQ.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 15 KiB |
BIN
agliullov_daniyar_lab_4/Screenshots/tutorial_1.png
Normal file
BIN
agliullov_daniyar_lab_4/Screenshots/tutorial_1.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 43 KiB |
BIN
agliullov_daniyar_lab_4/Screenshots/tutorial_2.png
Normal file
BIN
agliullov_daniyar_lab_4/Screenshots/tutorial_2.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 46 KiB |
BIN
agliullov_daniyar_lab_4/Screenshots/tutorial_3.png
Normal file
BIN
agliullov_daniyar_lab_4/Screenshots/tutorial_3.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 24 KiB |
28
agliullov_daniyar_lab_4/publisher.py
Normal file
28
agliullov_daniyar_lab_4/publisher.py
Normal file
@ -0,0 +1,28 @@
|
||||
import pika
|
||||
import time
|
||||
|
||||
|
||||
def publish_events():
|
||||
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
|
||||
channel = connection.channel()
|
||||
|
||||
# Создание exchange типа fanout
|
||||
channel.exchange_declare(exchange='beauty_salon_events', exchange_type='fanout')
|
||||
|
||||
events = [
|
||||
"Test1",
|
||||
"Test2",
|
||||
"Test3",
|
||||
"Test4",
|
||||
"Test5"
|
||||
]
|
||||
|
||||
while True:
|
||||
event = events[int(time.time()) % len(events)]
|
||||
channel.basic_publish(exchange='beauty_salon_events', routing_key='', body=event)
|
||||
print(f'Отправлено: {event}')
|
||||
time.sleep(1)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
publish_events()
|
||||
25
agliullov_daniyar_lab_4/tutorial_1/receive.py
Normal file
25
agliullov_daniyar_lab_4/tutorial_1/receive.py
Normal file
@ -0,0 +1,25 @@
|
||||
import pika, sys, os
|
||||
|
||||
def main():
|
||||
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
|
||||
channel = connection.channel()
|
||||
|
||||
channel.queue_declare(queue='hello')
|
||||
|
||||
def callback(ch, method, properties, body):
|
||||
print(f" [x] Received {body}")
|
||||
|
||||
channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True)
|
||||
|
||||
print(' [*] Waiting for messages. To exit press CTRL+C')
|
||||
channel.start_consuming()
|
||||
|
||||
if __name__ == '__main__':
|
||||
try:
|
||||
main()
|
||||
except KeyboardInterrupt:
|
||||
print('Interrupted')
|
||||
try:
|
||||
sys.exit(0)
|
||||
except SystemExit:
|
||||
os._exit(0)
|
||||
11
agliullov_daniyar_lab_4/tutorial_1/send.py
Normal file
11
agliullov_daniyar_lab_4/tutorial_1/send.py
Normal file
@ -0,0 +1,11 @@
|
||||
import pika
|
||||
|
||||
connection = pika.BlockingConnection(
|
||||
pika.ConnectionParameters(host='localhost'))
|
||||
channel = connection.channel()
|
||||
|
||||
channel.queue_declare(queue='hello')
|
||||
|
||||
channel.basic_publish(exchange='', routing_key='hello', body='Hello World!')
|
||||
print(" [x] Sent 'Hello World!'")
|
||||
connection.close()
|
||||
19
agliullov_daniyar_lab_4/tutorial_2/new_task.py
Normal file
19
agliullov_daniyar_lab_4/tutorial_2/new_task.py
Normal file
@ -0,0 +1,19 @@
|
||||
import pika
|
||||
import sys
|
||||
|
||||
connection = pika.BlockingConnection(
|
||||
pika.ConnectionParameters(host='localhost'))
|
||||
channel = connection.channel()
|
||||
|
||||
channel.queue_declare(queue='task_queue', durable=True)
|
||||
|
||||
message = ' '.join(sys.argv[1:]) or "Hello World!"
|
||||
channel.basic_publish(
|
||||
exchange='',
|
||||
routing_key='task_queue',
|
||||
body=message,
|
||||
properties=pika.BasicProperties(
|
||||
delivery_mode=pika.DeliveryMode.Persistent
|
||||
))
|
||||
print(f" [x] Sent {message}")
|
||||
connection.close()
|
||||
23
agliullov_daniyar_lab_4/tutorial_2/worker.py
Normal file
23
agliullov_daniyar_lab_4/tutorial_2/worker.py
Normal file
@ -0,0 +1,23 @@
|
||||
#!/usr/bin/env python
|
||||
import pika
|
||||
import time
|
||||
|
||||
connection = pika.BlockingConnection(
|
||||
pika.ConnectionParameters(host='localhost'))
|
||||
channel = connection.channel()
|
||||
|
||||
channel.queue_declare(queue='task_queue', durable=True)
|
||||
print(' [*] Waiting for messages. To exit press CTRL+C')
|
||||
|
||||
|
||||
def callback(ch, method, properties, body):
|
||||
print(f" [x] Received {body.decode()}")
|
||||
time.sleep(body.count(b'.'))
|
||||
print(" [x] Done")
|
||||
ch.basic_ack(delivery_tag=method.delivery_tag)
|
||||
|
||||
|
||||
channel.basic_qos(prefetch_count=1)
|
||||
channel.basic_consume(queue='task_queue', on_message_callback=callback)
|
||||
|
||||
channel.start_consuming()
|
||||
13
agliullov_daniyar_lab_4/tutorial_3/emit_log.py
Normal file
13
agliullov_daniyar_lab_4/tutorial_3/emit_log.py
Normal file
@ -0,0 +1,13 @@
|
||||
import pika
|
||||
import sys
|
||||
|
||||
connection = pika.BlockingConnection(
|
||||
pika.ConnectionParameters(host='localhost'))
|
||||
channel = connection.channel()
|
||||
|
||||
channel.exchange_declare(exchange='logs', exchange_type='fanout')
|
||||
|
||||
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
|
||||
channel.basic_publish(exchange='logs', routing_key='', body=message)
|
||||
print(f" [x] Sent {message}")
|
||||
connection.close()
|
||||
22
agliullov_daniyar_lab_4/tutorial_3/receive_logs.py
Normal file
22
agliullov_daniyar_lab_4/tutorial_3/receive_logs.py
Normal file
@ -0,0 +1,22 @@
|
||||
import pika
|
||||
|
||||
connection = pika.BlockingConnection(
|
||||
pika.ConnectionParameters(host='localhost'))
|
||||
channel = connection.channel()
|
||||
|
||||
channel.exchange_declare(exchange='logs', exchange_type='fanout')
|
||||
|
||||
result = channel.queue_declare(queue='', exclusive=True)
|
||||
queue_name = result.method.queue
|
||||
|
||||
channel.queue_bind(exchange='logs', queue=queue_name)
|
||||
|
||||
print(' [*] Waiting for logs. To exit press CTRL+C')
|
||||
|
||||
def callback(ch, method, properties, body):
|
||||
print(f" [x] {body}")
|
||||
|
||||
channel.basic_consume(
|
||||
queue=queue_name, on_message_callback=callback, auto_ack=True)
|
||||
|
||||
channel.start_consuming()
|
||||
BIN
agliullov_daniyar_lab_5/Screenshots/1.png
Normal file
BIN
agliullov_daniyar_lab_5/Screenshots/1.png
Normal file
Binary file not shown.
|
After 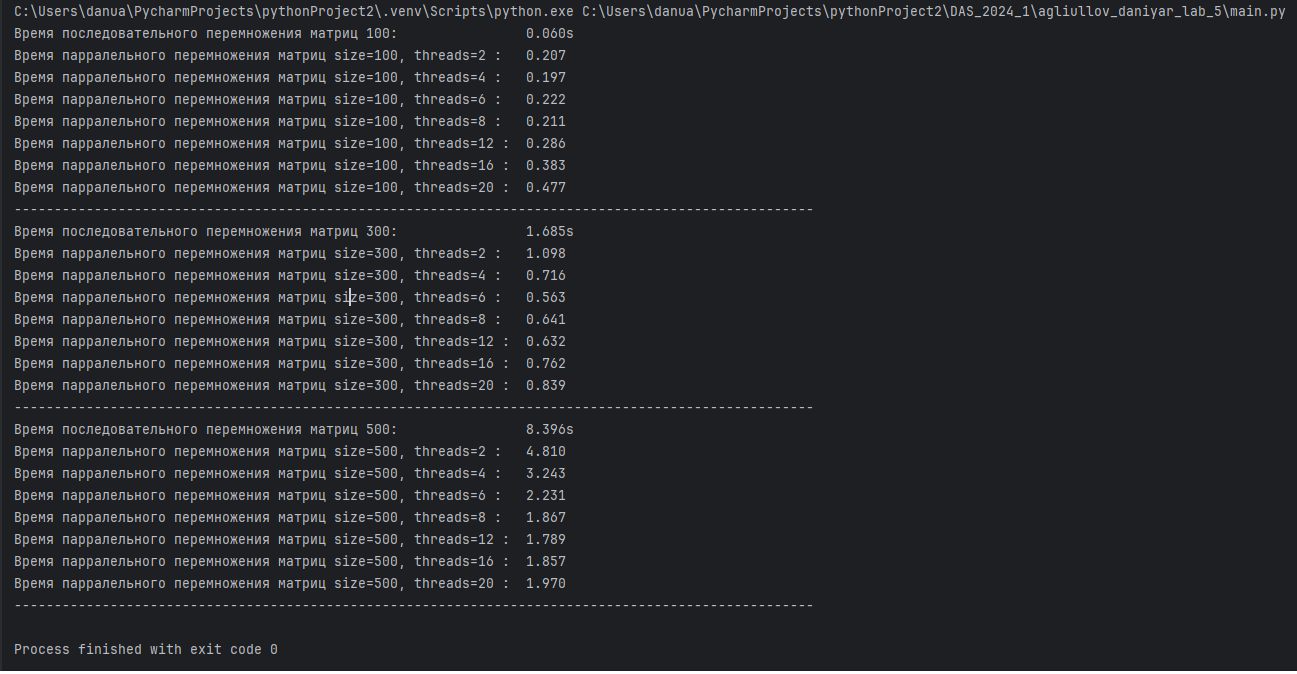
(image error) Size: 114 KiB |
Binary file not shown.
|
After 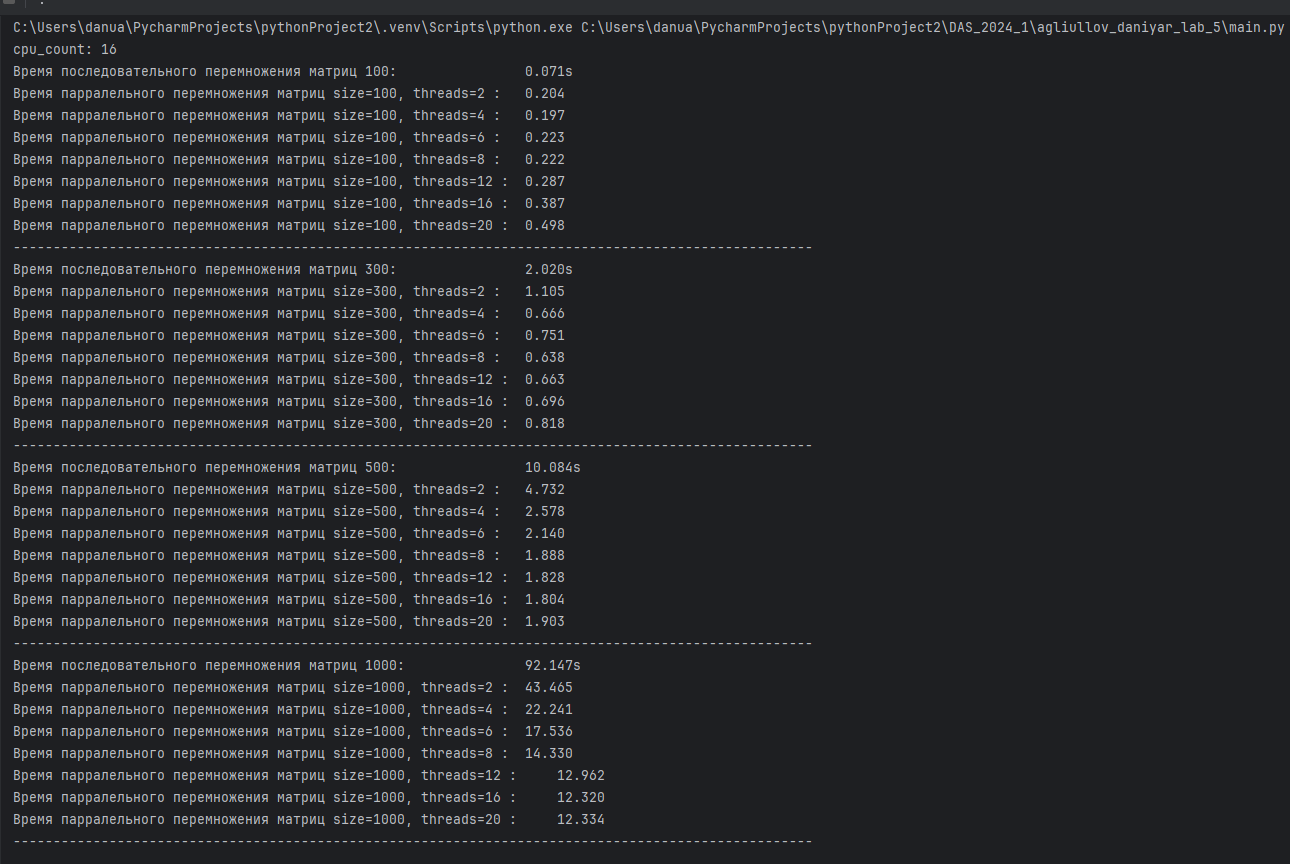
(image error) Size: 187 KiB |
68
agliullov_daniyar_lab_5/main.py
Normal file
68
agliullov_daniyar_lab_5/main.py
Normal file
@ -0,0 +1,68 @@
|
||||
import multiprocessing
|
||||
import random
|
||||
import time
|
||||
from pprint import pprint
|
||||
from multiprocessing import Pool
|
||||
|
||||
|
||||
def create_random_matrix(size):
|
||||
return [[random.random() for _ in range(size)] for __ in range(size)]
|
||||
|
||||
# def matrix_multiply_seq(matrix1: list[list[float]], matrix2: list[list[float]]) -> list[list[float]]:
|
||||
# """Выполняет последовательное перемножение двух матриц и возвращает результирующую матрицу"""
|
||||
# l1 = len(matrix1)
|
||||
# l2 = len(matrix2)
|
||||
# result = [[0 for _ in range(l2)] for __ in range(l1)]
|
||||
# for i in range(l1):
|
||||
# for j in range(l2):
|
||||
# for k in range(l2):
|
||||
# result[i][j] += matrix1[i][k] * matrix2[k][j]
|
||||
# return result
|
||||
|
||||
|
||||
matrix_result = [[0 for _ in range(1000)] for __ in range(1000)]
|
||||
|
||||
def matrix_multiply(args) -> None:
|
||||
"""Перемножает строки от start_cnt до end_cnt, результат помещает в глобальную переменную matrix_result"""
|
||||
matrix1, matrix2, start_cnt, end_cnt = args
|
||||
for i in range(start_cnt, end_cnt):
|
||||
for j in range(len(matrix2)):
|
||||
for k in range(len(matrix2)):
|
||||
matrix_result[i][j] += matrix1[i - start_cnt][k] * matrix2[k][j]
|
||||
|
||||
|
||||
def matrix_multiply_parralel(matrix1: list[list[float]], matrix2: list[list[float]], thread_count):
|
||||
"""Выполняет парралеьное перемножение матриц"""
|
||||
l1 = len(matrix1)
|
||||
|
||||
step = l1 // thread_count
|
||||
args = [(matrix1, matrix2, i, i + step) for i in range(0, l1, step)]
|
||||
args[-1] = (matrix1, matrix2, step * (l1 - 1), l1) # Остаток на последний поток
|
||||
|
||||
with Pool(processes=thread_count) as pool:
|
||||
pool.map(matrix_multiply, args)
|
||||
# pprint(matrix_result, compact=True)
|
||||
|
||||
def main():
|
||||
sizes = [100, 300, 500, 1000]
|
||||
num_threads = [2, 4, 6, 8, 12, 16, 20]
|
||||
print(f"cpu_count: {multiprocessing.cpu_count()}")
|
||||
|
||||
for size in sizes:
|
||||
matrix1 = create_random_matrix(size)
|
||||
matrix2 = create_random_matrix(size)
|
||||
t0 = time.perf_counter()
|
||||
matrix_multiply((matrix1, matrix2, 0, len(matrix1)))
|
||||
# pprint(matrix_result[:size][:size], compact=True)
|
||||
print(f"Время последовательного перемножения матриц {size=:4}: \t\t\t\t{time.perf_counter() - t0:.3f}s")
|
||||
|
||||
for threads in num_threads:
|
||||
start_time = time.perf_counter()
|
||||
matrix_multiply_parralel(matrix1, matrix2, threads)
|
||||
end_time = time.perf_counter()
|
||||
print(f"Время парралельного перемножения матриц {size=:4}, {threads=} : \t{end_time - start_time:.3f}")
|
||||
|
||||
print("-" * 100)
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
17
agliullov_daniyar_lab_5/readme.md
Normal file
17
agliullov_daniyar_lab_5/readme.md
Normal file
@ -0,0 +1,17 @@
|
||||
# Аглиуллов Данияр ИСЭбд-41
|
||||
# Лабораторная работа №5
|
||||
|
||||
В ходе выполнения задачи по умножению квадратных матриц с использованием обычного и параллельного алгоритмов были получены следующие результаты и выводы:
|
||||
|
||||
Результаты тестов:
|
||||

|
||||

|
||||
|
||||
Сравнение производительности:
|
||||
|
||||
• В тестах на матрицах размером 100x100, 300x300 и 500x500 было замечено, что параллельный алгоритм демонстрирует значительное сокращение времени выполнения по сравнению с обычным алгоритмом, особенно на больших матрицах. Это подтверждает эффективность использования многопоточности для задач, требующих больших вычислительных ресурсов.
|
||||
|
||||
• На малых размерах матриц (например, 100x100) преимущество было за последовательным умножением матрицы из-за накладных расходов на создание пула потоков. Однако при увеличении размера матриц (300x300 и 500x500) преимущества параллельного подхода становились более очевидными.
|
||||
• При превышении количества физических потоков процессора, производительность понижается за счет смены контекста при переключении виртуальных потоков на одном ядре
|
||||
|
||||

|
||||
Binary file not shown.
|
After 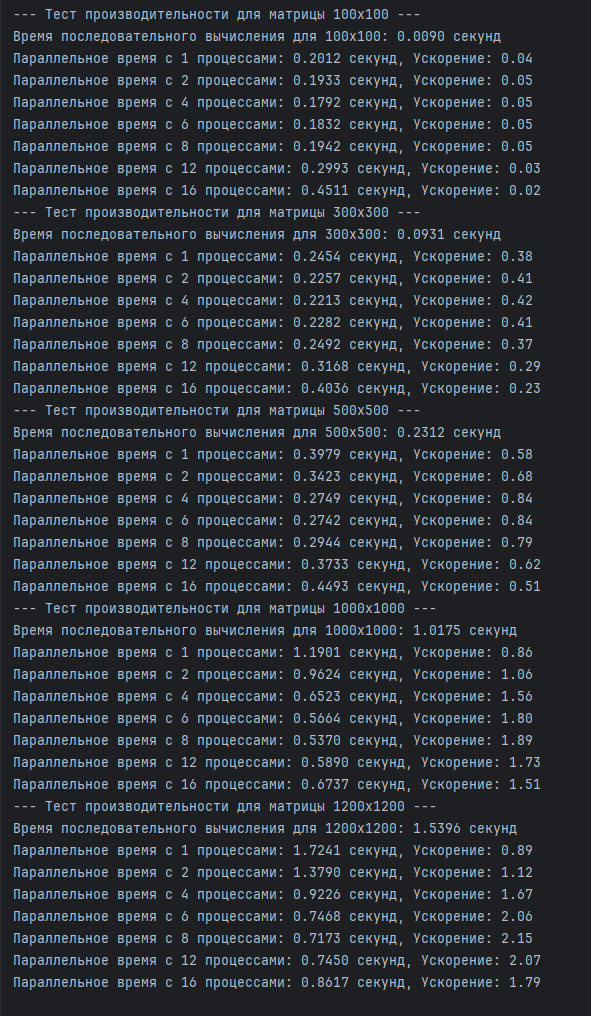
(image error) Size: 227 KiB |
86
agliullov_daniyar_lab_6/main.py
Normal file
86
agliullov_daniyar_lab_6/main.py
Normal file
@ -0,0 +1,86 @@
|
||||
import numpy as np
|
||||
import time
|
||||
from multiprocessing import Pool
|
||||
|
||||
np.seterr(over='ignore')
|
||||
|
||||
# Функция для вычисления детерминанта методом Гаусса
|
||||
def compute_determinant_gauss(mat):
|
||||
size = mat.shape[0]
|
||||
matrix_copy = mat.astype(float) # Копируем матрицу, чтобы не изменять исходную
|
||||
determinant = 1.0 # Начальное значение детерминанта
|
||||
|
||||
for k in range(size):
|
||||
# Находим максимальный элемент в текущем столбце для уменьшения ошибок округления
|
||||
max_index = np.argmax(np.abs(matrix_copy[k:size, k])) + k
|
||||
if matrix_copy[max_index, k] == 0:
|
||||
return 0 # Если на главной диагонали ноль, детерминант равен нулю
|
||||
# Меняем местами строки
|
||||
if max_index != k:
|
||||
matrix_copy[[k, max_index]] = matrix_copy[[max_index, k]]
|
||||
determinant *= -1 # Каждая перестановка меняет знак детерминанта
|
||||
# Обнуляем элементы ниже главной диагонали
|
||||
for m in range(k + 1, size):
|
||||
multiplier = matrix_copy[m, k] / matrix_copy[k, k]
|
||||
matrix_copy[m, k:] -= multiplier * matrix_copy[k, k:]
|
||||
|
||||
# Произведение элементов на главной диагонали
|
||||
for j in range(size):
|
||||
determinant *= matrix_copy[j, j]
|
||||
return determinant
|
||||
|
||||
# Функция для параллельного вычисления детерминанта
|
||||
def parallel_worker(index_range, mat):
|
||||
size = mat.shape[0]
|
||||
matrix_copy = mat.astype(float)
|
||||
det = 1.0
|
||||
|
||||
for k in range(index_range[0], index_range[1]):
|
||||
max_index = np.argmax(np.abs(matrix_copy[k:size, k])) + k
|
||||
if matrix_copy[max_index, k] == 0:
|
||||
return 0
|
||||
if max_index != k:
|
||||
matrix_copy[[k, max_index]] = matrix_copy[[max_index, k]]
|
||||
det *= -1
|
||||
for m in range(k + 1, size):
|
||||
multiplier = matrix_copy[m, k] / matrix_copy[k, k]
|
||||
matrix_copy[m, k:] -= multiplier * matrix_copy[k, k:]
|
||||
return det
|
||||
|
||||
# Функция для параллельного вычисления детерминанта
|
||||
def compute_parallel_determinant(mat, num_workers):
|
||||
size = mat.shape[0]
|
||||
block_size = size // num_workers
|
||||
ranges = [(i * block_size, (i + 1) * block_size) for i in range(num_workers)]
|
||||
|
||||
with Pool(processes=num_workers) as pool:
|
||||
results = pool.starmap(parallel_worker, [(block, mat) for block in ranges])
|
||||
|
||||
# Объединяем результаты
|
||||
total_determinant = sum(results)
|
||||
return total_determinant
|
||||
|
||||
# Функция для запуска тестов производительности
|
||||
def execute_benchmarks():
|
||||
sizes = [100, 300, 500] # Размеры матриц
|
||||
for size in sizes:
|
||||
random_matrix = np.random.rand(size, size) # Генерация случайной матрицы
|
||||
print(f"--- Тест производительности для матрицы {size}x{size} ---")
|
||||
|
||||
# Последовательное вычисление детерминанта
|
||||
start_time = time.time()
|
||||
sequential_det = compute_determinant_gauss(random_matrix)
|
||||
seq_duration = time.time() - start_time
|
||||
print(f"Время последовательного вычисления для {size}x{size}: {seq_duration:.4f} секунд")
|
||||
|
||||
# Параллельное вычисление с различным количеством процессов
|
||||
for workers in [1, 2, 4, 6, 8, 12, 16]:
|
||||
start_time = time.time()
|
||||
parallel_det = compute_parallel_determinant(random_matrix, workers)
|
||||
par_duration = time.time() - start_time
|
||||
speedup_ratio = seq_duration / par_duration if par_duration > 0 else 0
|
||||
print(f"Параллельное время с {workers} процессами: {par_duration:.4f} секунд, Ускорение: {speedup_ratio:.2f}")
|
||||
|
||||
# Запуск тестов производительности
|
||||
if __name__ == '__main__':
|
||||
execute_benchmarks()
|
||||
16
agliullov_daniyar_lab_6/readme.md
Normal file
16
agliullov_daniyar_lab_6/readme.md
Normal file
@ -0,0 +1,16 @@
|
||||
# Аглиуллов Данияр ИСЭбд-41
|
||||
# Лабораторная работа №6
|
||||
|
||||
Для повышения производительности при вычислении детерминанта для больших матриц была добавлена возможность параллельной обработки с использованием библиотеки multiprocessing. Это позволило значительно ускорить вычисления за счет распределения нагрузки между несколькими процессами.
|
||||
|
||||
Результаты тестов:
|
||||

|
||||
|
||||
Сравнение производительности:
|
||||
|
||||
• В тестах на матрицах размером 100x100, 300x300 и 500x500 было замечено, что параллельный алгоритм демонстрирует значительное сокращение времени выполнения по сравнению с обычным алгоритмом, особенно на больших матрицах. Это подтверждает эффективность использования многопоточности для задач, требующих больших вычислительных ресурсов.
|
||||
|
||||
• На малых размерах матриц (например, 100x100) преимущество было за последовательным умножением матрицы из-за накладных расходов на создание пула потоков. Однако при увеличении размера матрицы (300x300 и 500x500) преимущества параллельного подхода становились более очевидными.
|
||||
• При превышении количества физических потоков процессора, производительность понижается за счет смены контекста при переключении виртуальных потоков на одном ядре
|
||||
|
||||

|
||||
24
agliullov_daniyar_lab_7/readme.md
Normal file
24
agliullov_daniyar_lab_7/readme.md
Normal file
@ -0,0 +1,24 @@
|
||||
# Лабораторная работа 7. Балансировка нагрузки в распределённых системах с использованием открытых технологий
|
||||
|
||||
## Задание
|
||||
|
||||
Написать краткое эссе, отвечая на следующие вопросы:
|
||||
|
||||
1. Какие алгоритмы и методы применяются для балансировки нагрузки?
|
||||
|
||||
2. Какие открытые технологии доступны для этой задачи?
|
||||
|
||||
3. Как осуществляется балансировка нагрузки в системах управления базами данных?
|
||||
|
||||
4. Какова роль реверс-прокси в процессе балансировки нагрузки?
|
||||
## Эссе по теме
|
||||
|
||||
Балансировка нагрузки является ключевым аспектом проектирования распределённых систем, позволяя равномерно распределять входящие запросы между несколькими серверами или ресурсами. Это способствует повышению доступности, производительности и устойчивости к сбоям системы.
|
||||
|
||||
Существует множество алгоритмов и методов, применяемых для балансировки нагрузки. К ним относятся Least Connections (минимальное количество соединений), Round Robin (круговая схема), Server Health Check (проверка состояния сервера), Least Response Time (минимальное время ответа) и Random (случайный выбор). Эти подходы помогают эффективно распределять клиентские запросы с учётом текущей загруженности серверов.
|
||||
|
||||
Среди открытых технологий для балансировки нагрузки можно выделить Nginx, HAProxy, Apache HTTP Server и другие. Эти инструменты позволяют настроить прокси-серверы, которые принимают запросы от пользователей и направляют их на один или несколько серверов приложений, обеспечивая равномерное распределение нагрузки.
|
||||
|
||||
Балансировка нагрузки в базах данных важна для поддержания доступности и производительности системы. Для этого используются специализированные решения, такие как ProxySQL, pgpool-II и MySQL Router. Они помогают распределять запросы к базам данных между различными узлами, что позволяет снизить нагрузку на основной сервер.
|
||||
|
||||
Реверс-прокси представляет собой сервер, который принимает запросы от клиентов и перенаправляет их на один или несколько серверов приложений. Он выполняет множество функций, включая балансировку нагрузки, обеспечение безопасности, кэширование, SSL-терминацию, а также мониторинг и ведение логов.
|
||||
52
agliullov_daniyar_lab_8/readme.md
Normal file
52
agliullov_daniyar_lab_8/readme.md
Normal file
@ -0,0 +1,52 @@
|
||||
# Лабораторная работа 8. Как Вы поняли, что называется распределенной системой и как она устроена?
|
||||
|
||||
## Задание:
|
||||
Написать небольшое эссе (буквально несколько абзацев) своими словами на тему "Устройство распределенных систем". Вопросы:
|
||||
|
||||
1. Зачем сложные системы (например, социальная сеть ВКонтакте) пишутся в "распределенном" стиле, где каждое отдельное приложение (или сервис) функционально выполняет только ограниченный спектр задач?
|
||||
|
||||
2. Для чего были созданы системы оркестрации приложений? Каким образом они упрощают / усложняют разработку и сопровождение распределенных систем?
|
||||
|
||||
3. Для чего нужны очереди обработки сообщений и что может подразумеваться под сообщениями?
|
||||
|
||||
4. Какие преимущества и недостатки распределенных приложений существуют на Ваш взгляд?
|
||||
|
||||
5. Целесообразно ли в сложную распределенную систему внедрять параллельные вычисления? Приведите примеры, когда это действительно нужно, а когда нет.
|
||||
|
||||
|
||||
## Преимущества распределённых приложений
|
||||
|
||||
1. Высокая доступность и отказоустойчивость: Один из основных плюсов распределённых систем заключается в том, что они могут продолжать функционировать даже при сбое отдельных компонентов. Это достигается за счёт дублирования сервисов и автоматического перенаправления запросов на работающие узлы.
|
||||
|
||||
2. Масштабируемость: Распределённые системы легко масштабируются. При увеличении нагрузки можно добавлять новые серверы или ресурсы без значительных изменений в архитектуре.
|
||||
|
||||
3. Обработка больших объёмов данных: Распределённые приложения могут одновременно обрабатывать множество запросов и большие объёмы данных, что делает их идеальными для таких задач, как анализ больших данных и машинное обучение.
|
||||
|
||||
## Недостатки распределённых приложений
|
||||
|
||||
1. Сложность архитектуры: Архитектура распределённых систем может быть значительно сложнее, чем у монолитных приложений. Это затрудняет отладку и мониторинг, так как необходимо учитывать взаимодействие множества компонентов.
|
||||
|
||||
2. Проблемы с согласованностью данных: В распределённых системах может возникнуть несогласованность данных между различными сервисами, особенно если они работают с копиями одних и тех же данных.
|
||||
|
||||
3. Управление безопасностью: Увеличение числа взаимодействий между компонентами системы требует более тщательного управления безопасностью, так как это повышает вероятность уязвимостей и атак.
|
||||
|
||||
## Внедрение параллельных вычислений
|
||||
|
||||
Параллельные вычисления в распределённых системах оправданы, когда необходимо обрабатывать большие объёмы данных или выполнять сложные вычисления. Например:
|
||||
|
||||
• Машинное обучение: Обучение моделей на больших наборах данных может быть значительно ускорено за счёт распараллеливания вычислений.
|
||||
|
||||
• Анализ больших данных: Параллельные вычисления позволяют эффективно обрабатывать данные, разбивая их на части и распределяя по нескольким узлам.
|
||||
|
||||
Однако стоит помнить, что не всегда параллельные вычисления оправданы:
|
||||
|
||||
• Если задача не требует значительных ресурсов или имеет низкую степень параллелизма, внедрение параллельных вычислений может усложнить архитектуру без ощутимой выгоды.
|
||||
|
||||
• Простые операции, такие как CRUD-операции, могут быть более эффективно реализованы в рамках монолитной архитектуры без необходимости распараллеливания.
|
||||
|
||||
|
||||
## Эссе на тему
|
||||
|
||||
Распределенные приложения имеют множество преимуществ. Во-первых, они обеспечивают высокую доступность и отказоустойчивость: если один компонент выходит из строя, остальные продолжают функционировать. Во-вторых, они масштабируемы: можно легко добавлять новые ресурсы по мере необходимости. В-третьих, распределенные системы могут обрабатывать большие объемы данных и запросов одновременно. Однако у них есть и недостатки. Сложность архитектуры может привести к трудностям в отладке и мониторинге. Также возможны проблемы с согласованностью данных между различными сервисами. Наконец, распределенные системы требуют более тщательного управления безопасностью, так как большее количество взаимодействий увеличивает вероятность уязвимостей.
|
||||
|
||||
Внедрение параллельных вычислений в распределенные системы целесообразно в тех случаях, когда необходимо обрабатывать большие объемы данных или выполнять сложные вычисления. Например, в задачах машинного обучения или анализа больших данных параллельные вычисления позволяют значительно сократить время обработки. Однако не всегда параллельные вычисления оправданы. Если задача не требует значительных ресурсов или имеет низкую степень параллелизма, то их внедрение может усложнить архитектуру без ощутимой выгоды. Например, простые CRUD-операции (создание, чтение, обновление и удаление) могут быть более эффективно реализованы без использования параллельных вычислений.
|
||||
30
aleikin_artem_lab_2/.dockerignore
Normal file
30
aleikin_artem_lab_2/.dockerignore
Normal file
@ -0,0 +1,30 @@
|
||||
**/.classpath
|
||||
**/.dockerignore
|
||||
**/.env
|
||||
**/.git
|
||||
**/.gitignore
|
||||
**/.project
|
||||
**/.settings
|
||||
**/.toolstarget
|
||||
**/.vs
|
||||
**/.vscode
|
||||
**/*.*proj.user
|
||||
**/*.dbmdl
|
||||
**/*.jfm
|
||||
**/azds.yaml
|
||||
**/bin
|
||||
**/charts
|
||||
**/docker-compose*
|
||||
**/Dockerfile*
|
||||
**/node_modules
|
||||
**/npm-debug.log
|
||||
**/obj
|
||||
**/secrets.dev.yaml
|
||||
**/values.dev.yaml
|
||||
LICENSE
|
||||
README.md
|
||||
!**/.gitignore
|
||||
!.git/HEAD
|
||||
!.git/config
|
||||
!.git/packed-refs
|
||||
!.git/refs/heads/**
|
||||
15
aleikin_artem_lab_2/ConsoleApp1/ConsoleApp1.csproj
Normal file
15
aleikin_artem_lab_2/ConsoleApp1/ConsoleApp1.csproj
Normal file
@ -0,0 +1,15 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk">
|
||||
|
||||
<PropertyGroup>
|
||||
<OutputType>Exe</OutputType>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<Nullable>enable</Nullable>
|
||||
<DockerDefaultTargetOS>Linux</DockerDefaultTargetOS>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="Microsoft.VisualStudio.Azure.Containers.Tools.Targets" Version="1.21.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
6
aleikin_artem_lab_2/ConsoleApp1/ConsoleApp1.csproj.user
Normal file
6
aleikin_artem_lab_2/ConsoleApp1/ConsoleApp1.csproj.user
Normal file
@ -0,0 +1,6 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<Project ToolsVersion="Current" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
|
||||
<PropertyGroup>
|
||||
<ActiveDebugProfile>Container (Dockerfile)</ActiveDebugProfile>
|
||||
</PropertyGroup>
|
||||
</Project>
|
||||
28
aleikin_artem_lab_2/ConsoleApp1/Dockerfile
Normal file
28
aleikin_artem_lab_2/ConsoleApp1/Dockerfile
Normal file
@ -0,0 +1,28 @@
|
||||
# См. статью по ссылке https://aka.ms/customizecontainer, чтобы узнать как настроить контейнер отладки и как Visual Studio использует этот Dockerfile для создания образов для ускорения отладки.
|
||||
|
||||
# Этот этап используется при запуске из VS в быстром режиме (по умолчанию для конфигурации отладки)
|
||||
FROM mcr.microsoft.com/dotnet/runtime:8.0 AS base
|
||||
USER app
|
||||
WORKDIR /app
|
||||
|
||||
|
||||
# Этот этап используется для сборки проекта службы
|
||||
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
WORKDIR /src
|
||||
COPY ["ConsoleApp1/ConsoleApp1.csproj", "ConsoleApp1/"]
|
||||
RUN dotnet restore "./ConsoleApp1/ConsoleApp1.csproj"
|
||||
COPY . .
|
||||
WORKDIR "/src/ConsoleApp1"
|
||||
RUN dotnet build "./ConsoleApp1.csproj" -c $BUILD_CONFIGURATION -o /app/build
|
||||
|
||||
# Этот этап используется для публикации проекта службы, который будет скопирован на последний этап
|
||||
FROM build AS publish
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
RUN dotnet publish "./ConsoleApp1.csproj" -c $BUILD_CONFIGURATION -o /app/publish /p:UseAppHost=false
|
||||
|
||||
# Этот этап используется в рабочей среде или при запуске из VS в обычном режиме (по умолчанию, когда конфигурация отладки не используется)
|
||||
FROM base AS final
|
||||
WORKDIR /app
|
||||
COPY --from=publish /app/publish .
|
||||
ENTRYPOINT ["dotnet", "ConsoleApp1.dll"]
|
||||
36
aleikin_artem_lab_2/ConsoleApp1/Program.cs
Normal file
36
aleikin_artem_lab_2/ConsoleApp1/Program.cs
Normal file
@ -0,0 +1,36 @@
|
||||
using System;
|
||||
using System.IO;
|
||||
|
||||
class Program
|
||||
{
|
||||
static void Main()
|
||||
{
|
||||
const string inputDir = "/var/data";
|
||||
const string outputFile = "/var/result/data.txt";
|
||||
|
||||
try
|
||||
{
|
||||
using (var writer = new StreamWriter(outputFile))
|
||||
{
|
||||
var files = Directory.GetFiles(inputDir);
|
||||
foreach (var file in files)
|
||||
{
|
||||
using (var reader = new StreamReader(file))
|
||||
{
|
||||
string firstLine = reader.ReadLine();
|
||||
if (!string.IsNullOrEmpty(firstLine))
|
||||
{
|
||||
writer.WriteLine(firstLine);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Console.WriteLine($"Файл {outputFile} успешно создан.");
|
||||
}
|
||||
catch (Exception ex)
|
||||
{
|
||||
Console.WriteLine($"Ошибка: {ex.Message}");
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,10 @@
|
||||
{
|
||||
"profiles": {
|
||||
"ConsoleApp1": {
|
||||
"commandName": "Project"
|
||||
},
|
||||
"Container (Dockerfile)": {
|
||||
"commandName": "Docker"
|
||||
}
|
||||
}
|
||||
}
|
||||
15
aleikin_artem_lab_2/ConsoleApp2/ConsoleApp2.csproj
Normal file
15
aleikin_artem_lab_2/ConsoleApp2/ConsoleApp2.csproj
Normal file
@ -0,0 +1,15 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk">
|
||||
|
||||
<PropertyGroup>
|
||||
<OutputType>Exe</OutputType>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<Nullable>enable</Nullable>
|
||||
<DockerDefaultTargetOS>Linux</DockerDefaultTargetOS>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="Microsoft.VisualStudio.Azure.Containers.Tools.Targets" Version="1.21.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
6
aleikin_artem_lab_2/ConsoleApp2/ConsoleApp2.csproj.user
Normal file
6
aleikin_artem_lab_2/ConsoleApp2/ConsoleApp2.csproj.user
Normal file
@ -0,0 +1,6 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<Project ToolsVersion="Current" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
|
||||
<PropertyGroup>
|
||||
<ActiveDebugProfile>Container (Dockerfile)</ActiveDebugProfile>
|
||||
</PropertyGroup>
|
||||
</Project>
|
||||
28
aleikin_artem_lab_2/ConsoleApp2/Dockerfile
Normal file
28
aleikin_artem_lab_2/ConsoleApp2/Dockerfile
Normal file
@ -0,0 +1,28 @@
|
||||
# См. статью по ссылке https://aka.ms/customizecontainer, чтобы узнать как настроить контейнер отладки и как Visual Studio использует этот Dockerfile для создания образов для ускорения отладки.
|
||||
|
||||
# Этот этап используется при запуске из VS в быстром режиме (по умолчанию для конфигурации отладки)
|
||||
FROM mcr.microsoft.com/dotnet/runtime:8.0 AS base
|
||||
USER app
|
||||
WORKDIR /app
|
||||
|
||||
|
||||
# Этот этап используется для сборки проекта службы
|
||||
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
WORKDIR /src
|
||||
COPY ["ConsoleApp2/ConsoleApp2.csproj", "ConsoleApp2/"]
|
||||
RUN dotnet restore "./ConsoleApp2/ConsoleApp2.csproj"
|
||||
COPY . .
|
||||
WORKDIR "/src/ConsoleApp2"
|
||||
RUN dotnet build "./ConsoleApp2.csproj" -c $BUILD_CONFIGURATION -o /app/build
|
||||
|
||||
# Этот этап используется для публикации проекта службы, который будет скопирован на последний этап
|
||||
FROM build AS publish
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
RUN dotnet publish "./ConsoleApp2.csproj" -c $BUILD_CONFIGURATION -o /app/publish /p:UseAppHost=false
|
||||
|
||||
# Этот этап используется в рабочей среде или при запуске из VS в обычном режиме (по умолчанию, когда конфигурация отладки не используется)
|
||||
FROM base AS final
|
||||
WORKDIR /app
|
||||
COPY --from=publish /app/publish .
|
||||
ENTRYPOINT ["dotnet", "ConsoleApp2.dll"]
|
||||
34
aleikin_artem_lab_2/ConsoleApp2/Program.cs
Normal file
34
aleikin_artem_lab_2/ConsoleApp2/Program.cs
Normal file
@ -0,0 +1,34 @@
|
||||
using System;
|
||||
using System.IO;
|
||||
using System.Linq;
|
||||
|
||||
class Program
|
||||
{
|
||||
static void Main()
|
||||
{
|
||||
const string inputFile = "/var/result/data.txt";
|
||||
const string outputFile = "/var/result/result.txt";
|
||||
|
||||
try
|
||||
{
|
||||
var lines = File.ReadAllLines(inputFile).Select(int.Parse).ToArray();
|
||||
|
||||
if (lines.Length >= 2)
|
||||
{
|
||||
int result = lines.First() * lines.Last();
|
||||
|
||||
File.WriteAllText(outputFile, result.ToString());
|
||||
|
||||
Console.WriteLine($"Произведение: {result}");
|
||||
}
|
||||
else
|
||||
{
|
||||
Console.WriteLine("Недостаточно данных в файле для вычисления.");
|
||||
}
|
||||
}
|
||||
catch (Exception ex)
|
||||
{
|
||||
Console.WriteLine($"Ошибка: {ex.Message}");
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,10 @@
|
||||
{
|
||||
"profiles": {
|
||||
"ConsoleApp2": {
|
||||
"commandName": "Project"
|
||||
},
|
||||
"Container (Dockerfile)": {
|
||||
"commandName": "Docker"
|
||||
}
|
||||
}
|
||||
}
|
||||
10
aleikin_artem_lab_2/data/file1.txt
Normal file
10
aleikin_artem_lab_2/data/file1.txt
Normal file
@ -0,0 +1,10 @@
|
||||
25
|
||||
91
|
||||
77
|
||||
63
|
||||
45
|
||||
25
|
||||
21
|
||||
89
|
||||
6
|
||||
18
|
||||
10
aleikin_artem_lab_2/data/file10.txt
Normal file
10
aleikin_artem_lab_2/data/file10.txt
Normal file
@ -0,0 +1,10 @@
|
||||
10
|
||||
3
|
||||
38
|
||||
9
|
||||
36
|
||||
43
|
||||
96
|
||||
31
|
||||
95
|
||||
58
|
||||
10
aleikin_artem_lab_2/data/file11.txt
Normal file
10
aleikin_artem_lab_2/data/file11.txt
Normal file
@ -0,0 +1,10 @@
|
||||
13
|
||||
35
|
||||
38
|
||||
31
|
||||
19
|
||||
94
|
||||
94
|
||||
84
|
||||
18
|
||||
47
|
||||
10
aleikin_artem_lab_2/data/file12.txt
Normal file
10
aleikin_artem_lab_2/data/file12.txt
Normal file
@ -0,0 +1,10 @@
|
||||
9
|
||||
32
|
||||
75
|
||||
92
|
||||
100
|
||||
85
|
||||
85
|
||||
10
|
||||
50
|
||||
54
|
||||
10
aleikin_artem_lab_2/data/file13.txt
Normal file
10
aleikin_artem_lab_2/data/file13.txt
Normal file
@ -0,0 +1,10 @@
|
||||
83
|
||||
88
|
||||
29
|
||||
86
|
||||
87
|
||||
79
|
||||
18
|
||||
22
|
||||
76
|
||||
71
|
||||
10
aleikin_artem_lab_2/data/file14.txt
Normal file
10
aleikin_artem_lab_2/data/file14.txt
Normal file
@ -0,0 +1,10 @@
|
||||
15
|
||||
22
|
||||
92
|
||||
91
|
||||
78
|
||||
47
|
||||
53
|
||||
98
|
||||
72
|
||||
64
|
||||
10
aleikin_artem_lab_2/data/file15.txt
Normal file
10
aleikin_artem_lab_2/data/file15.txt
Normal file
@ -0,0 +1,10 @@
|
||||
66
|
||||
45
|
||||
83
|
||||
55
|
||||
25
|
||||
82
|
||||
95
|
||||
42
|
||||
18
|
||||
6
|
||||
10
aleikin_artem_lab_2/data/file16.txt
Normal file
10
aleikin_artem_lab_2/data/file16.txt
Normal file
@ -0,0 +1,10 @@
|
||||
25
|
||||
71
|
||||
35
|
||||
71
|
||||
78
|
||||
51
|
||||
29
|
||||
67
|
||||
87
|
||||
33
|
||||
10
aleikin_artem_lab_2/data/file17.txt
Normal file
10
aleikin_artem_lab_2/data/file17.txt
Normal file
@ -0,0 +1,10 @@
|
||||
93
|
||||
19
|
||||
32
|
||||
13
|
||||
75
|
||||
86
|
||||
46
|
||||
87
|
||||
39
|
||||
66
|
||||
10
aleikin_artem_lab_2/data/file18.txt
Normal file
10
aleikin_artem_lab_2/data/file18.txt
Normal file
@ -0,0 +1,10 @@
|
||||
7
|
||||
74
|
||||
69
|
||||
75
|
||||
45
|
||||
28
|
||||
92
|
||||
9
|
||||
77
|
||||
32
|
||||
10
aleikin_artem_lab_2/data/file19.txt
Normal file
10
aleikin_artem_lab_2/data/file19.txt
Normal file
@ -0,0 +1,10 @@
|
||||
42
|
||||
75
|
||||
67
|
||||
53
|
||||
2
|
||||
34
|
||||
57
|
||||
47
|
||||
83
|
||||
52
|
||||
10
aleikin_artem_lab_2/data/file2.txt
Normal file
10
aleikin_artem_lab_2/data/file2.txt
Normal file
@ -0,0 +1,10 @@
|
||||
98
|
||||
62
|
||||
45
|
||||
77
|
||||
65
|
||||
45
|
||||
61
|
||||
62
|
||||
10
|
||||
76
|
||||
10
aleikin_artem_lab_2/data/file20.txt
Normal file
10
aleikin_artem_lab_2/data/file20.txt
Normal file
@ -0,0 +1,10 @@
|
||||
41
|
||||
30
|
||||
41
|
||||
39
|
||||
62
|
||||
3
|
||||
79
|
||||
93
|
||||
56
|
||||
82
|
||||
10
aleikin_artem_lab_2/data/file21.txt
Normal file
10
aleikin_artem_lab_2/data/file21.txt
Normal file
@ -0,0 +1,10 @@
|
||||
85
|
||||
29
|
||||
46
|
||||
36
|
||||
82
|
||||
52
|
||||
4
|
||||
14
|
||||
89
|
||||
17
|
||||
10
aleikin_artem_lab_2/data/file22.txt
Normal file
10
aleikin_artem_lab_2/data/file22.txt
Normal file
@ -0,0 +1,10 @@
|
||||
35
|
||||
98
|
||||
38
|
||||
31
|
||||
39
|
||||
76
|
||||
5
|
||||
71
|
||||
7
|
||||
58
|
||||
10
aleikin_artem_lab_2/data/file23.txt
Normal file
10
aleikin_artem_lab_2/data/file23.txt
Normal file
@ -0,0 +1,10 @@
|
||||
50
|
||||
93
|
||||
18
|
||||
76
|
||||
13
|
||||
62
|
||||
16
|
||||
45
|
||||
65
|
||||
25
|
||||
10
aleikin_artem_lab_2/data/file24.txt
Normal file
10
aleikin_artem_lab_2/data/file24.txt
Normal file
@ -0,0 +1,10 @@
|
||||
98
|
||||
45
|
||||
1
|
||||
52
|
||||
14
|
||||
7
|
||||
56
|
||||
38
|
||||
7
|
||||
50
|
||||
10
aleikin_artem_lab_2/data/file25.txt
Normal file
10
aleikin_artem_lab_2/data/file25.txt
Normal file
@ -0,0 +1,10 @@
|
||||
41
|
||||
27
|
||||
27
|
||||
24
|
||||
76
|
||||
36
|
||||
19
|
||||
87
|
||||
83
|
||||
35
|
||||
10
aleikin_artem_lab_2/data/file26.txt
Normal file
10
aleikin_artem_lab_2/data/file26.txt
Normal file
@ -0,0 +1,10 @@
|
||||
16
|
||||
5
|
||||
95
|
||||
36
|
||||
20
|
||||
60
|
||||
79
|
||||
46
|
||||
61
|
||||
77
|
||||
10
aleikin_artem_lab_2/data/file27.txt
Normal file
10
aleikin_artem_lab_2/data/file27.txt
Normal file
@ -0,0 +1,10 @@
|
||||
43
|
||||
23
|
||||
53
|
||||
6
|
||||
88
|
||||
27
|
||||
55
|
||||
15
|
||||
94
|
||||
36
|
||||
10
aleikin_artem_lab_2/data/file28.txt
Normal file
10
aleikin_artem_lab_2/data/file28.txt
Normal file
@ -0,0 +1,10 @@
|
||||
62
|
||||
95
|
||||
50
|
||||
65
|
||||
13
|
||||
56
|
||||
74
|
||||
37
|
||||
99
|
||||
93
|
||||
10
aleikin_artem_lab_2/data/file29.txt
Normal file
10
aleikin_artem_lab_2/data/file29.txt
Normal file
@ -0,0 +1,10 @@
|
||||
13
|
||||
2
|
||||
31
|
||||
49
|
||||
80
|
||||
73
|
||||
47
|
||||
61
|
||||
96
|
||||
69
|
||||
10
aleikin_artem_lab_2/data/file3.txt
Normal file
10
aleikin_artem_lab_2/data/file3.txt
Normal file
@ -0,0 +1,10 @@
|
||||
37
|
||||
54
|
||||
100
|
||||
34
|
||||
1
|
||||
77
|
||||
55
|
||||
10
|
||||
30
|
||||
28
|
||||
10
aleikin_artem_lab_2/data/file30.txt
Normal file
10
aleikin_artem_lab_2/data/file30.txt
Normal file
@ -0,0 +1,10 @@
|
||||
35
|
||||
17
|
||||
95
|
||||
59
|
||||
17
|
||||
98
|
||||
68
|
||||
54
|
||||
89
|
||||
56
|
||||
10
aleikin_artem_lab_2/data/file4.txt
Normal file
10
aleikin_artem_lab_2/data/file4.txt
Normal file
@ -0,0 +1,10 @@
|
||||
38
|
||||
80
|
||||
93
|
||||
2
|
||||
61
|
||||
29
|
||||
4
|
||||
41
|
||||
83
|
||||
100
|
||||
10
aleikin_artem_lab_2/data/file5.txt
Normal file
10
aleikin_artem_lab_2/data/file5.txt
Normal file
@ -0,0 +1,10 @@
|
||||
40
|
||||
61
|
||||
30
|
||||
92
|
||||
84
|
||||
37
|
||||
79
|
||||
81
|
||||
98
|
||||
88
|
||||
10
aleikin_artem_lab_2/data/file6.txt
Normal file
10
aleikin_artem_lab_2/data/file6.txt
Normal file
@ -0,0 +1,10 @@
|
||||
66
|
||||
32
|
||||
27
|
||||
5
|
||||
49
|
||||
50
|
||||
44
|
||||
51
|
||||
7
|
||||
32
|
||||
10
aleikin_artem_lab_2/data/file7.txt
Normal file
10
aleikin_artem_lab_2/data/file7.txt
Normal file
@ -0,0 +1,10 @@
|
||||
9
|
||||
46
|
||||
16
|
||||
27
|
||||
14
|
||||
78
|
||||
6
|
||||
45
|
||||
26
|
||||
99
|
||||
10
aleikin_artem_lab_2/data/file8.txt
Normal file
10
aleikin_artem_lab_2/data/file8.txt
Normal file
@ -0,0 +1,10 @@
|
||||
48
|
||||
41
|
||||
43
|
||||
93
|
||||
91
|
||||
95
|
||||
16
|
||||
23
|
||||
91
|
||||
43
|
||||
10
aleikin_artem_lab_2/data/file9.txt
Normal file
10
aleikin_artem_lab_2/data/file9.txt
Normal file
@ -0,0 +1,10 @@
|
||||
67
|
||||
82
|
||||
16
|
||||
87
|
||||
69
|
||||
83
|
||||
94
|
||||
59
|
||||
34
|
||||
73
|
||||
20
aleikin_artem_lab_2/docker-compose.yml
Normal file
20
aleikin_artem_lab_2/docker-compose.yml
Normal file
@ -0,0 +1,20 @@
|
||||
services:
|
||||
app1:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: ConsoleApp1/Dockerfile
|
||||
volumes:
|
||||
- ./data:/var/data
|
||||
- ./result:/var/result
|
||||
container_name: app1
|
||||
|
||||
app2:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: ConsoleApp2/Dockerfile
|
||||
volumes:
|
||||
- ./data:/var/data
|
||||
- ./result:/var/result
|
||||
container_name: app2
|
||||
depends_on:
|
||||
- app1
|
||||
97
aleikin_artem_lab_2/readme.md
Normal file
97
aleikin_artem_lab_2/readme.md
Normal file
@ -0,0 +1,97 @@
|
||||
# Лабораторная работа 2 - Разработка простейшего распределённого приложения
|
||||
## ПИбд-42 || Алейкин Артем
|
||||
|
||||
### Описание
|
||||
В данной лабораторной работе мы изучили способы создания и развертывания простого распределённого приложения.
|
||||
Для выполнения лабораторной работы в рамках реализации первого проекта был выбран 2-ой вариант, а для второго проекта - 0-ой вариант.
|
||||
1.2: Формирует файл /var/result/data.txt из первых строк всех файлов каталога /var/data.
|
||||
2.0: Сохраняет произведение первого и последнего числа из файла /var/data/data.txt в /var/result/result.txt.
|
||||
|
||||
### Docker-compose.yml
|
||||
```
|
||||
services:
|
||||
app1:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: ConsoleApp1/Dockerfile
|
||||
volumes:
|
||||
- ./data:/var/data
|
||||
- ./result:/var/result
|
||||
container_name: app1
|
||||
|
||||
app2:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: ConsoleApp2/Dockerfile
|
||||
volumes:
|
||||
- ./data:/var/data
|
||||
- ./result:/var/result
|
||||
container_name: app2
|
||||
depends_on:
|
||||
- app1
|
||||
```
|
||||
|
||||
app1:
|
||||
build: Контейнер для app1 создается с использованием Dockerfile, расположенного в ConsoleApp1/Dockerfile.
|
||||
volumes: Монтируются две локальные директории:
|
||||
./data в /var/data внутри контейнера
|
||||
./result в /var/result внутри контейнера
|
||||
container_name: Контейнер будет называться app1.
|
||||
|
||||
app2:
|
||||
build: Контейнер для app2 создается с использованием Dockerfile, расположенного в ConsoleApp2/Dockerfile.
|
||||
volumes: Монтируются те же локальные директории, что и для app1.
|
||||
container_name: Контейнер будет называться app2.
|
||||
depends_on: Контейнер app2 зависит от запуска контейнера app1, что означает, что app2 будет запускаться только после того, как контейнер app1 будет готов.
|
||||
|
||||
|
||||
### Шаги для запуска:
|
||||
1. Запуск Docker - Desktop
|
||||
2. Открыть консоль в папке с docker-compose.yml
|
||||
3. Ввести команду:
|
||||
```
|
||||
docket-compose up --build
|
||||
```
|
||||
|
||||
#### В результате в папке result создаётся два текстовых документа:
|
||||
|
||||
data - результат работы первого проекта
|
||||
```
|
||||
25
|
||||
10
|
||||
13
|
||||
9
|
||||
83
|
||||
15
|
||||
66
|
||||
25
|
||||
93
|
||||
7
|
||||
42
|
||||
98
|
||||
41
|
||||
85
|
||||
35
|
||||
50
|
||||
98
|
||||
41
|
||||
16
|
||||
43
|
||||
62
|
||||
13
|
||||
37
|
||||
35
|
||||
38
|
||||
40
|
||||
66
|
||||
9
|
||||
48
|
||||
67
|
||||
```
|
||||
result - результат работы второго проекта
|
||||
```
|
||||
1675
|
||||
```
|
||||
|
||||
|
||||
Видео демонстрации работы: https://vk.com/video248424990_456239609?list=ln-jAWvJM5pgqjuzJLU1j
|
||||
30
aleikin_artem_lab_2/result/data.txt
Normal file
30
aleikin_artem_lab_2/result/data.txt
Normal file
@ -0,0 +1,30 @@
|
||||
25
|
||||
10
|
||||
13
|
||||
9
|
||||
83
|
||||
15
|
||||
66
|
||||
25
|
||||
93
|
||||
7
|
||||
42
|
||||
98
|
||||
41
|
||||
85
|
||||
35
|
||||
50
|
||||
98
|
||||
41
|
||||
16
|
||||
43
|
||||
62
|
||||
13
|
||||
37
|
||||
35
|
||||
38
|
||||
40
|
||||
66
|
||||
9
|
||||
48
|
||||
67
|
||||
1
aleikin_artem_lab_2/result/result.txt
Normal file
1
aleikin_artem_lab_2/result/result.txt
Normal file
@ -0,0 +1 @@
|
||||
1675
|
||||
30
aleikin_artem_lab_3/.dockerignore
Normal file
30
aleikin_artem_lab_3/.dockerignore
Normal file
@ -0,0 +1,30 @@
|
||||
**/.classpath
|
||||
**/.dockerignore
|
||||
**/.env
|
||||
**/.git
|
||||
**/.gitignore
|
||||
**/.project
|
||||
**/.settings
|
||||
**/.toolstarget
|
||||
**/.vs
|
||||
**/.vscode
|
||||
**/*.*proj.user
|
||||
**/*.dbmdl
|
||||
**/*.jfm
|
||||
**/azds.yaml
|
||||
**/bin
|
||||
**/charts
|
||||
**/docker-compose*
|
||||
**/Dockerfile*
|
||||
**/node_modules
|
||||
**/npm-debug.log
|
||||
**/obj
|
||||
**/secrets.dev.yaml
|
||||
**/values.dev.yaml
|
||||
LICENSE
|
||||
README.md
|
||||
!**/.gitignore
|
||||
!.git/HEAD
|
||||
!.git/config
|
||||
!.git/packed-refs
|
||||
!.git/refs/heads/**
|
||||
@ -0,0 +1,60 @@
|
||||
using Microsoft.AspNetCore.Http;
|
||||
using Microsoft.AspNetCore.Mvc;
|
||||
using ProjectEntityProject.Entity;
|
||||
|
||||
namespace ProjectEntityProject.Controllers
|
||||
{
|
||||
[ApiController]
|
||||
[Route("projects")]
|
||||
public class ProjectController : ControllerBase
|
||||
{
|
||||
private static readonly List<Project> Projects = new();
|
||||
|
||||
[HttpGet]
|
||||
public ActionResult<List<Project>> GetProjects() => Ok(Projects);
|
||||
|
||||
[HttpGet("{id}")]
|
||||
public ActionResult<Project> GetProject([FromRoute] Guid id)
|
||||
{
|
||||
var project = Projects.FirstOrDefault(p => p.Id == id);
|
||||
return project is null ? NotFound() : Ok(project);
|
||||
}
|
||||
|
||||
[HttpPost]
|
||||
public ActionResult<Project> CreateProject([FromBody] ProjectDto projectdDto)
|
||||
{
|
||||
Project project = new Project
|
||||
{
|
||||
Name = projectdDto.Name,
|
||||
Description = projectdDto.Description,
|
||||
};
|
||||
Projects.Add(project);
|
||||
return CreatedAtAction(nameof(GetProject), new { id = project.Id }, project);
|
||||
}
|
||||
|
||||
[HttpPut("{id}")]
|
||||
public ActionResult<Project> UpdateProject(Guid id, [FromBody] ProjectDto projectDto)
|
||||
{
|
||||
var project = Projects.FirstOrDefault(p => p.Id == id);
|
||||
if (project is null) return NotFound();
|
||||
|
||||
project.Name = projectDto.Name;
|
||||
project.Description = projectDto.Description;
|
||||
return Ok(project);
|
||||
}
|
||||
|
||||
[HttpDelete("{id}")]
|
||||
public IActionResult DeleteProject(Guid id)
|
||||
{
|
||||
var project = Projects.FirstOrDefault(p => p.Id == id);
|
||||
if (project is null) return NotFound();
|
||||
|
||||
Projects.Remove(project);
|
||||
|
||||
var client = new HttpClient();
|
||||
var response = client.DeleteAsync($"http://nginx/taskservice/tasks/by-project/{id}").Result;
|
||||
return response.IsSuccessStatusCode ? Ok() : StatusCode(500);
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
29
aleikin_artem_lab_3/ProjectEntityProject/Dockerfile
Normal file
29
aleikin_artem_lab_3/ProjectEntityProject/Dockerfile
Normal file
@ -0,0 +1,29 @@
|
||||
# См. статью по ссылке https://aka.ms/customizecontainer, чтобы узнать как настроить контейнер отладки и как Visual Studio использует этот Dockerfile для создания образов для ускорения отладки.
|
||||
|
||||
# Этот этап используется при запуске из VS в быстром режиме (по умолчанию для конфигурации отладки)
|
||||
FROM mcr.microsoft.com/dotnet/aspnet:8.0 AS base
|
||||
USER app
|
||||
WORKDIR /app
|
||||
EXPOSE 5001
|
||||
|
||||
|
||||
# Этот этап используется для сборки проекта службы
|
||||
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
WORKDIR /src
|
||||
COPY ["ProjectEntityProject/ProjectEntityProject.csproj", "ProjectEntityProject/"]
|
||||
RUN dotnet restore "./ProjectEntityProject/ProjectEntityProject.csproj"
|
||||
COPY . .
|
||||
WORKDIR "/src/ProjectEntityProject"
|
||||
RUN dotnet build "./ProjectEntityProject.csproj" -c $BUILD_CONFIGURATION -o /app/build
|
||||
|
||||
# Этот этап используется для публикации проекта службы, который будет скопирован на последний этап
|
||||
FROM build AS publish
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
RUN dotnet publish "./ProjectEntityProject.csproj" -c $BUILD_CONFIGURATION -o /app/publish /p:UseAppHost=false
|
||||
|
||||
# Этот этап используется в рабочей среде или при запуске из VS в обычном режиме (по умолчанию, когда конфигурация отладки не используется)
|
||||
FROM base AS final
|
||||
WORKDIR /app
|
||||
COPY --from=publish /app/publish .
|
||||
ENTRYPOINT ["dotnet", "ProjectEntityProject.dll"]
|
||||
10
aleikin_artem_lab_3/ProjectEntityProject/Entity/Project.cs
Normal file
10
aleikin_artem_lab_3/ProjectEntityProject/Entity/Project.cs
Normal file
@ -0,0 +1,10 @@
|
||||
namespace ProjectEntityProject.Entity
|
||||
{
|
||||
public class Project
|
||||
{
|
||||
public Guid Id { get; init; } = Guid.NewGuid();
|
||||
public string Name { get; set; } = string.Empty;
|
||||
public string Description { get; set; } = string.Empty;
|
||||
}
|
||||
|
||||
}
|
||||
@ -0,0 +1,4 @@
|
||||
namespace ProjectEntityProject.Entity
|
||||
{
|
||||
public record ProjectDto(string Name, string Description) { }
|
||||
}
|
||||
46
aleikin_artem_lab_3/ProjectEntityProject/Program.cs
Normal file
46
aleikin_artem_lab_3/ProjectEntityProject/Program.cs
Normal file
@ -0,0 +1,46 @@
|
||||
using Microsoft.AspNetCore.Hosting;
|
||||
using Microsoft.OpenApi.Models;
|
||||
|
||||
var builder = WebApplication.CreateBuilder(args);
|
||||
|
||||
builder.WebHost.ConfigureKestrel(serverOptions =>
|
||||
{
|
||||
serverOptions.ListenAnyIP(5001);
|
||||
});
|
||||
|
||||
builder.Services.AddControllers();
|
||||
// Learn more about configuring Swagger/OpenAPI at https://aka.ms/aspnetcore/swashbuckle
|
||||
builder.Services.AddEndpointsApiExplorer();
|
||||
builder.Services.AddSwaggerGen();
|
||||
|
||||
builder.Services.AddCors(options =>
|
||||
{
|
||||
options.AddPolicy("AllowAll", policy =>
|
||||
{
|
||||
policy.AllowAnyOrigin()
|
||||
.AllowAnyMethod()
|
||||
.AllowAnyHeader();
|
||||
});
|
||||
});
|
||||
|
||||
var app = builder.Build();
|
||||
|
||||
app.UseCors("AllowAll");
|
||||
|
||||
app.UseSwagger(c =>
|
||||
{
|
||||
|
||||
c.PreSerializeFilters.Add((swaggerDoc, httpReq) =>
|
||||
{
|
||||
swaggerDoc.Servers = new List<OpenApiServer> { new OpenApiServer { Url = $"{httpReq.Scheme}://{httpReq.Host.Value}/projectservice" } };
|
||||
});
|
||||
});
|
||||
app.UseSwaggerUI();
|
||||
|
||||
app.UseHttpsRedirection();
|
||||
|
||||
app.UseAuthorization();
|
||||
|
||||
app.MapControllers();
|
||||
|
||||
app.Run();
|
||||
@ -0,0 +1,16 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk.Web">
|
||||
|
||||
<PropertyGroup>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<Nullable>enable</Nullable>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<UserSecretsId>8c799772-d663-4c4a-8e6b-cce6a75ee84e</UserSecretsId>
|
||||
<DockerDefaultTargetOS>Linux</DockerDefaultTargetOS>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="Microsoft.VisualStudio.Azure.Containers.Tools.Targets" Version="1.21.0" />
|
||||
<PackageReference Include="Swashbuckle.AspNetCore" Version="6.4.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
@ -0,0 +1,8 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<Project ToolsVersion="Current" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
|
||||
<PropertyGroup>
|
||||
<ActiveDebugProfile>Container (Dockerfile)</ActiveDebugProfile>
|
||||
<Controller_SelectedScaffolderID>MvcControllerWithActionsScaffolder</Controller_SelectedScaffolderID>
|
||||
<Controller_SelectedScaffolderCategoryPath>root/Common/MVC/Controller</Controller_SelectedScaffolderCategoryPath>
|
||||
</PropertyGroup>
|
||||
</Project>
|
||||
@ -0,0 +1,6 @@
|
||||
@ProjectEntityProject_HostAddress = http://localhost:5168
|
||||
|
||||
GET {{ProjectEntityProject_HostAddress}}/weatherforecast/
|
||||
Accept: application/json
|
||||
|
||||
###
|
||||
@ -0,0 +1,52 @@
|
||||
{
|
||||
"profiles": {
|
||||
"http": {
|
||||
"commandName": "Project",
|
||||
"launchBrowser": true,
|
||||
"launchUrl": "swagger",
|
||||
"environmentVariables": {
|
||||
"ASPNETCORE_ENVIRONMENT": "Development"
|
||||
},
|
||||
"dotnetRunMessages": true,
|
||||
"applicationUrl": "http://localhost:5168"
|
||||
},
|
||||
"https": {
|
||||
"commandName": "Project",
|
||||
"launchBrowser": true,
|
||||
"launchUrl": "swagger",
|
||||
"environmentVariables": {
|
||||
"ASPNETCORE_ENVIRONMENT": "Development"
|
||||
},
|
||||
"dotnetRunMessages": true,
|
||||
"applicationUrl": "https://localhost:7265;http://localhost:5168"
|
||||
},
|
||||
"IIS Express": {
|
||||
"commandName": "IISExpress",
|
||||
"launchBrowser": true,
|
||||
"launchUrl": "swagger",
|
||||
"environmentVariables": {
|
||||
"ASPNETCORE_ENVIRONMENT": "Development"
|
||||
}
|
||||
},
|
||||
"Container (Dockerfile)": {
|
||||
"commandName": "Docker",
|
||||
"launchBrowser": true,
|
||||
"launchUrl": "{Scheme}://{ServiceHost}:{ServicePort}/swagger",
|
||||
"environmentVariables": {
|
||||
"ASPNETCORE_HTTPS_PORTS": "8081",
|
||||
"ASPNETCORE_HTTP_PORTS": "8080"
|
||||
},
|
||||
"publishAllPorts": true,
|
||||
"useSSL": true
|
||||
}
|
||||
},
|
||||
"$schema": "http://json.schemastore.org/launchsettings.json",
|
||||
"iisSettings": {
|
||||
"windowsAuthentication": false,
|
||||
"anonymousAuthentication": true,
|
||||
"iisExpress": {
|
||||
"applicationUrl": "http://localhost:54970",
|
||||
"sslPort": 44349
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,8 @@
|
||||
{
|
||||
"Logging": {
|
||||
"LogLevel": {
|
||||
"Default": "Information",
|
||||
"Microsoft.AspNetCore": "Warning"
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,9 @@
|
||||
{
|
||||
"Logging": {
|
||||
"LogLevel": {
|
||||
"Default": "Information",
|
||||
"Microsoft.AspNetCore": "Warning"
|
||||
}
|
||||
},
|
||||
"AllowedHosts": "*"
|
||||
}
|
||||
@ -0,0 +1,77 @@
|
||||
using Microsoft.AspNetCore.Http;
|
||||
using Microsoft.AspNetCore.Mvc;
|
||||
using System.Net.Http;
|
||||
using TaskProject.Entity;
|
||||
using static System.Runtime.InteropServices.JavaScript.JSType;
|
||||
using Task = TaskProject.Entity.Task;
|
||||
|
||||
namespace TaskProject.Controllers
|
||||
{
|
||||
[ApiController]
|
||||
[Route("tasks")]
|
||||
public class TaskController : ControllerBase
|
||||
{
|
||||
private static readonly List<Task> Tasks = new();
|
||||
|
||||
[HttpGet]
|
||||
public ActionResult<List<Task>> GetTasks() => Ok(Tasks);
|
||||
|
||||
[HttpGet("{id}")]
|
||||
public ActionResult<Task> GetTask(Guid id)
|
||||
{
|
||||
var task = Tasks.FirstOrDefault(t => t.Id == id);
|
||||
return task is null ? NotFound() : Ok(task);
|
||||
}
|
||||
|
||||
[HttpPost]
|
||||
public ActionResult<Task> CreateTask([FromBody] TaskDto taskDto)
|
||||
{
|
||||
Task task = new Task
|
||||
{
|
||||
Title = taskDto.Title,
|
||||
Description = taskDto.Description,
|
||||
ProjectId = taskDto.ProjectId,
|
||||
};
|
||||
var client = new HttpClient();
|
||||
var response = client.GetAsync($"http://nginx/projectservice/projects/{task.ProjectId}").Result;
|
||||
if (!response.IsSuccessStatusCode) return BadRequest("Project not found");
|
||||
|
||||
Tasks.Add(task);
|
||||
return CreatedAtAction(nameof(GetTask), new { id = task.Id }, task);
|
||||
}
|
||||
|
||||
[HttpPut("{id}")]
|
||||
public ActionResult<Task> UpdateTask(Guid id, [FromBody] TaskDto taskDto)
|
||||
{
|
||||
var task = Tasks.FirstOrDefault(t => t.Id == id);
|
||||
if (task is null) return NotFound();
|
||||
|
||||
var client = new HttpClient();
|
||||
var response = client.GetAsync($"http://nginx/projectservice/projects/{task.ProjectId}").Result;
|
||||
if (!response.IsSuccessStatusCode) return BadRequest("Project not found");
|
||||
|
||||
task.Title = taskDto.Title;
|
||||
task.Description = taskDto.Description;
|
||||
task.ProjectId = taskDto.ProjectId;
|
||||
return Ok(task);
|
||||
}
|
||||
|
||||
[HttpDelete("{id}")]
|
||||
public IActionResult DeleteTask(Guid id)
|
||||
{
|
||||
var task = Tasks.FirstOrDefault(t => t.Id == id);
|
||||
if (task is null) return NotFound();
|
||||
|
||||
Tasks.Remove(task);
|
||||
return Ok();
|
||||
}
|
||||
|
||||
[HttpDelete("by-project/{projectId}")]
|
||||
public IActionResult DeleteTasksByProject(Guid projectId)
|
||||
{
|
||||
Tasks.RemoveAll(t => t.ProjectId == projectId);
|
||||
return Ok();
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
29
aleikin_artem_lab_3/TaskProject/Dockerfile
Normal file
29
aleikin_artem_lab_3/TaskProject/Dockerfile
Normal file
@ -0,0 +1,29 @@
|
||||
# См. статью по ссылке https://aka.ms/customizecontainer, чтобы узнать как настроить контейнер отладки и как Visual Studio использует этот Dockerfile для создания образов для ускорения отладки.
|
||||
|
||||
# Этот этап используется при запуске из VS в быстром режиме (по умолчанию для конфигурации отладки)
|
||||
FROM mcr.microsoft.com/dotnet/aspnet:8.0 AS base
|
||||
USER app
|
||||
WORKDIR /app
|
||||
EXPOSE 5002
|
||||
|
||||
|
||||
# Этот этап используется для сборки проекта службы
|
||||
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
WORKDIR /src
|
||||
COPY ["TaskProject/TaskProject.csproj", "TaskProject/"]
|
||||
RUN dotnet restore "./TaskProject/TaskProject.csproj"
|
||||
COPY . .
|
||||
WORKDIR "/src/TaskProject"
|
||||
RUN dotnet build "./TaskProject.csproj" -c $BUILD_CONFIGURATION -o /app/build
|
||||
|
||||
# Этот этап используется для публикации проекта службы, который будет скопирован на последний этап
|
||||
FROM build AS publish
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
RUN dotnet publish "./TaskProject.csproj" -c $BUILD_CONFIGURATION -o /app/publish /p:UseAppHost=false
|
||||
|
||||
# Этот этап используется в рабочей среде или при запуске из VS в обычном режиме (по умолчанию, когда конфигурация отладки не используется)
|
||||
FROM base AS final
|
||||
WORKDIR /app
|
||||
COPY --from=publish /app/publish .
|
||||
ENTRYPOINT ["dotnet", "TaskProject.dll"]
|
||||
11
aleikin_artem_lab_3/TaskProject/Entity/Task.cs
Normal file
11
aleikin_artem_lab_3/TaskProject/Entity/Task.cs
Normal file
@ -0,0 +1,11 @@
|
||||
namespace TaskProject.Entity
|
||||
{
|
||||
public class Task
|
||||
{
|
||||
public Guid Id { get; init; } = Guid.NewGuid();
|
||||
public string Title { get; set; } = string.Empty;
|
||||
public string Description { get; set; } = string.Empty;
|
||||
public Guid ProjectId { get; set; }
|
||||
}
|
||||
|
||||
}
|
||||
4
aleikin_artem_lab_3/TaskProject/Entity/TaskDto.cs
Normal file
4
aleikin_artem_lab_3/TaskProject/Entity/TaskDto.cs
Normal file
@ -0,0 +1,4 @@
|
||||
namespace TaskProject.Entity
|
||||
{
|
||||
public record TaskDto(string Title, string Description, Guid ProjectId) {}
|
||||
}
|
||||
45
aleikin_artem_lab_3/TaskProject/Program.cs
Normal file
45
aleikin_artem_lab_3/TaskProject/Program.cs
Normal file
@ -0,0 +1,45 @@
|
||||
using Microsoft.OpenApi.Models;
|
||||
|
||||
var builder = WebApplication.CreateBuilder(args);
|
||||
|
||||
builder.WebHost.ConfigureKestrel(serverOptions =>
|
||||
{
|
||||
serverOptions.ListenAnyIP(5002);
|
||||
});
|
||||
|
||||
builder.Services.AddCors(options =>
|
||||
{
|
||||
options.AddPolicy("AllowAll", policy =>
|
||||
{
|
||||
policy.AllowAnyOrigin()
|
||||
.AllowAnyMethod()
|
||||
.AllowAnyHeader();
|
||||
});
|
||||
});
|
||||
|
||||
builder.Services.AddControllers();
|
||||
// Learn more about configuring Swagger/OpenAPI at https://aka.ms/aspnetcore/swashbuckle
|
||||
builder.Services.AddEndpointsApiExplorer();
|
||||
builder.Services.AddSwaggerGen();
|
||||
|
||||
var app = builder.Build();
|
||||
|
||||
app.UseCors("AllowAll");
|
||||
|
||||
app.UseSwagger(c =>
|
||||
{
|
||||
|
||||
c.PreSerializeFilters.Add((swaggerDoc, httpReq) =>
|
||||
{
|
||||
swaggerDoc.Servers = new List<OpenApiServer> { new OpenApiServer { Url = $"{httpReq.Scheme}://{httpReq.Host.Value}/taskservice" } };
|
||||
});
|
||||
});
|
||||
app.UseSwaggerUI();
|
||||
|
||||
app.UseHttpsRedirection();
|
||||
|
||||
app.UseAuthorization();
|
||||
|
||||
app.MapControllers();
|
||||
|
||||
app.Run();
|
||||
@ -0,0 +1,52 @@
|
||||
{
|
||||
"profiles": {
|
||||
"http": {
|
||||
"commandName": "Project",
|
||||
"launchBrowser": true,
|
||||
"launchUrl": "swagger",
|
||||
"environmentVariables": {
|
||||
"ASPNETCORE_ENVIRONMENT": "Development"
|
||||
},
|
||||
"dotnetRunMessages": true,
|
||||
"applicationUrl": "http://localhost:5079"
|
||||
},
|
||||
"https": {
|
||||
"commandName": "Project",
|
||||
"launchBrowser": true,
|
||||
"launchUrl": "swagger",
|
||||
"environmentVariables": {
|
||||
"ASPNETCORE_ENVIRONMENT": "Development"
|
||||
},
|
||||
"dotnetRunMessages": true,
|
||||
"applicationUrl": "https://localhost:7111;http://localhost:5079"
|
||||
},
|
||||
"IIS Express": {
|
||||
"commandName": "IISExpress",
|
||||
"launchBrowser": true,
|
||||
"launchUrl": "swagger",
|
||||
"environmentVariables": {
|
||||
"ASPNETCORE_ENVIRONMENT": "Development"
|
||||
}
|
||||
},
|
||||
"Container (Dockerfile)": {
|
||||
"commandName": "Docker",
|
||||
"launchBrowser": true,
|
||||
"launchUrl": "{Scheme}://{ServiceHost}:{ServicePort}/swagger",
|
||||
"environmentVariables": {
|
||||
"ASPNETCORE_HTTPS_PORTS": "8081",
|
||||
"ASPNETCORE_HTTP_PORTS": "8080"
|
||||
},
|
||||
"publishAllPorts": true,
|
||||
"useSSL": true
|
||||
}
|
||||
},
|
||||
"$schema": "http://json.schemastore.org/launchsettings.json",
|
||||
"iisSettings": {
|
||||
"windowsAuthentication": false,
|
||||
"anonymousAuthentication": true,
|
||||
"iisExpress": {
|
||||
"applicationUrl": "http://localhost:54012",
|
||||
"sslPort": 44337
|
||||
}
|
||||
}
|
||||
}
|
||||
16
aleikin_artem_lab_3/TaskProject/TaskProject.csproj
Normal file
16
aleikin_artem_lab_3/TaskProject/TaskProject.csproj
Normal file
@ -0,0 +1,16 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk.Web">
|
||||
|
||||
<PropertyGroup>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<Nullable>enable</Nullable>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<UserSecretsId>735c8756-0d0c-4166-875d-9dfbf7cf10c4</UserSecretsId>
|
||||
<DockerDefaultTargetOS>Linux</DockerDefaultTargetOS>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="Microsoft.VisualStudio.Azure.Containers.Tools.Targets" Version="1.21.0" />
|
||||
<PackageReference Include="Swashbuckle.AspNetCore" Version="6.4.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
8
aleikin_artem_lab_3/TaskProject/TaskProject.csproj.user
Normal file
8
aleikin_artem_lab_3/TaskProject/TaskProject.csproj.user
Normal file
@ -0,0 +1,8 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<Project ToolsVersion="Current" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
|
||||
<PropertyGroup>
|
||||
<ActiveDebugProfile>Container (Dockerfile)</ActiveDebugProfile>
|
||||
<Controller_SelectedScaffolderID>MvcControllerWithActionsScaffolder</Controller_SelectedScaffolderID>
|
||||
<Controller_SelectedScaffolderCategoryPath>root/Common/MVC/Controller</Controller_SelectedScaffolderCategoryPath>
|
||||
</PropertyGroup>
|
||||
</Project>
|
||||
6
aleikin_artem_lab_3/TaskProject/TaskProject.http
Normal file
6
aleikin_artem_lab_3/TaskProject/TaskProject.http
Normal file
@ -0,0 +1,6 @@
|
||||
@TaskProject_HostAddress = http://localhost:5079
|
||||
|
||||
GET {{TaskProject_HostAddress}}/weatherforecast/
|
||||
Accept: application/json
|
||||
|
||||
###
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user