Compare commits
185 Commits
kurushina_
...
main
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
5dd9e26f07 | ||
| 60e2c7996c | |||
| 95d2554f95 | |||
| d9c57f2e8e | |||
| 158c0670a4 | |||
| df8cf26c03 | |||
| 9495f5cd12 | |||
| 9e71d368c8 | |||
| 5c8dbc4ae3 | |||
| e89eb8fc8d | |||
| a74ea43db8 | |||
| f1afb24c8b | |||
| 2c12d97510 | |||
| 00c170a00c | |||
| c620f10752 | |||
| e46d33bc4d | |||
| 1a11fca0e4 | |||
| db9395340c | |||
| 9485011484 | |||
| 75c4fde178 | |||
| 93f689f155 | |||
| 6e224cf288 | |||
| a9fba22e19 | |||
| d7008ca1e5 | |||
| 3fb94595bc | |||
| 14de0603a8 | |||
| 31346e7082 | |||
| fc6f211197 | |||
| b5944df141 | |||
|
|
1812ac159e | ||
| fa4c181ac0 | |||
| 4343669b5a | |||
| d95e2a9d3a | |||
| 2f9c00b03b | |||
| 51af80f3ad | |||
| 1fffeaa7e9 | |||
| a463ec8241 | |||
| 7a1ba7aa9a | |||
| 08cc99b0fc | |||
| 6556e21d9a | |||
| 7accd18aea | |||
| bfc6d8bb95 | |||
| cdd0a7b7c9 | |||
| 27850eb504 | |||
| 6feebae507 | |||
| 1648f5995a | |||
| bf8d06a85d | |||
| de0f1780c7 | |||
| e54fd14090 | |||
| ce580c4572 | |||
| 84f32a0993 | |||
| 7a36b2b0af | |||
| 02d6165c7e | |||
| 18c838d58c | |||
| 9d6529c11d | |||
| 1dc61d09d4 | |||
| 84edc080bd | |||
| 885ad1ffec | |||
| 4b1c9666a0 | |||
| 135f79e158 | |||
| 62b20a244e | |||
| e8f3643fd1 | |||
| 2a388e9788 | |||
| 3be8ceb996 | |||
| 84786b8531 | |||
| 6b370579f8 | |||
| a608e3a24b | |||
| 4f7d9d4ba1 | |||
| 547212dca6 | |||
| 58f4127148 | |||
| f12a88ed52 | |||
| e3979acf4d | |||
| 8640f9e8fc | |||
| c26a7b8d97 | |||
| 29320bae24 | |||
| 5449675d39 | |||
| b895c806e7 | |||
| 920dec1ede | |||
| fdba824237 | |||
|
|
10a12d8da0 | ||
| 25b2a2c481 | |||
| c699558126 | |||
| 4226945dca | |||
| 239da31a0d | |||
| 693c6bd91d | |||
| 31c074f6bb | |||
| 21c4aa5f5e | |||
|
|
75b27fd1f5 | ||
|
|
05293340a3 | ||
|
|
ef4acd4ec6 | ||
|
|
356bb54247 | ||
| c9b601dda5 | |||
| a3dc157784 | |||
| c06d3e291b | |||
| 4c83bd29bf | |||
|
|
a3827d5b4b | ||
| b64b354a74 | |||
| 8ef7197268 | |||
| 8e5776d104 | |||
| 25f8ce44eb | |||
| a25c242bda | |||
| 429ab85f80 | |||
| 681b9b4c00 | |||
| ae4ba4c88d | |||
| 91b02cece8 | |||
| fb3994fcab | |||
| af77bb1076 | |||
| 3fb0096475 | |||
| 752036c0ae | |||
|
|
544d4c2714 | ||
| 5247783708 | |||
| 7e69d49c4d | |||
| 753e2f6593 | |||
| 055bb25d6b | |||
| e760640200 | |||
|
|
063b93d78e | ||
|
|
44a4ee7eec | ||
| 3df2cc1a48 | |||
| 8c5f33678e | |||
|
|
2cfe26ee1b | ||
| ee80d0ffdd | |||
| 63854633e1 | |||
| b38e755299 | |||
|
|
65121a52d7 | ||
| db8939f045 | |||
|
|
219c77a03f | ||
| 8462ae9c2f | |||
| a5a422fc0f | |||
| a1bca21933 | |||
| 6f030312a7 | |||
| 2fc7e3e67f | |||
| 9bbe7b8b53 | |||
| 0add49368f | |||
| 41d7a3d8fd | |||
| 7002b58201 | |||
| a3c467e867 | |||
| e7a219301e | |||
| bc54fabeb5 | |||
| 90206c821f | |||
|
|
f6614533d7 | ||
|
|
3ef7c65962 | ||
|
|
9808787f27 | ||
|
|
c3b1e9157a | ||
|
|
69f42f260e | ||
|
|
cdaa75298a | ||
|
|
4390166883 | ||
| 287fb33386 | |||
| 9ff5b267bc | |||
|
|
6beff3a600 | ||
| 9d7821b12b | |||
| 07a49d9b7b | |||
|
|
8546d15925 | ||
| ead1821703 | |||
| ba0da1d0d4 | |||
| ad560d4736 | |||
| ed5444768f | |||
| f3b2646a1e | |||
| accd6bf3ee | |||
| aabcb9cd0b | |||
| 743c9ebc3c | |||
| f8750da593 | |||
| d91622551e | |||
| 9995db128b | |||
| f70c507b05 | |||
| 715d3aed42 | |||
| 56094094e4 | |||
| c406c5bfb5 | |||
| c0d126982f | |||
| 1b7e6aaa75 | |||
| 729994bd69 | |||
| 0126669fcf | |||
| 17d5f3321a | |||
| b3c516e6c1 | |||
| 877d246bb5 | |||
| db3d13a606 | |||
| 2308bf7b72 | |||
| 9915587ada | |||
| 31381ab310 | |||
| e0a2b5991a | |||
| 224878be45 | |||
| ea2cfbc71b | |||
| 75e377a2db | |||
| fc6efda0c2 | |||
| 201eb8f79e | |||
| 115085bb88 |
.gitignore
afanasev_dmitry_lab_6
afanasev_dmitry_lab_7
afanasev_dmitry_lab_8
aleikin_artem_lab_4
Consumer1
Consumer2
FirstTutorial
Images
Лаба_Отчет1.pngЛаба_Отчет2.pngЛаба_Отчет3.pngЛаба_Отчет4.pngТуториал_1.pngТуториал_2.pngТуториал_3.png
Publisher
SecondTutorial
ThirdTutorial
docker-compose.ymlreadme.mdalkin_ivan_lab_2
alkin_ivan_lab_3
artamonova_tatyana_lab_5
artamonova_tatyana_lab_6
artamonova_tatyana_lab_7
artamonova_tatyana_lab_8
bazunov_andrew_lab_7
bazunov_andrew_lab_8
bondarenko_max_lab_2
bondarenko_max_lab_3
57
.gitignore
vendored
Normal file
57
.gitignore
vendored
Normal file
@ -0,0 +1,57 @@
|
||||
################################################################################
|
||||
# Данный GITIGNORE-файл был автоматически создан Microsoft(R) Visual Studio.
|
||||
################################################################################
|
||||
|
||||
/.vs/DAS_2024_1
|
||||
/.vs
|
||||
/aleikin_artem_lab_3/.vs
|
||||
/aleikin_artem_lab_3/ProjectEntityProject/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_3/ProjectEntityProject/obj
|
||||
/aleikin_artem_lab_3/TaskProject/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_3/TaskProject/obj/Container
|
||||
/aleikin_artem_lab_3/TaskProject/obj
|
||||
/aleikin_artem_lab_4/RVIPLab4/.vs
|
||||
/aleikin_artem_lab_4/RVIPLab4/Consumer1/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/RVIPLab4/Consumer1/obj
|
||||
/aleikin_artem_lab_4/RVIPLab4/Consumer2/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/RVIPLab4/Consumer2/obj
|
||||
/aleikin_artem_lab_4/RVIPLab4/FirstTutorial/Receive/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/RVIPLab4/FirstTutorial/Receive/obj
|
||||
/aleikin_artem_lab_4/RVIPLab4/FirstTutorial/Send/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/RVIPLab4/FirstTutorial/Send/obj
|
||||
/aleikin_artem_lab_4/RVIPLab4/Publisher/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/RVIPLab4/Publisher/obj
|
||||
/aleikin_artem_lab_4/RVIPLab4/SecondTutorial/NewTask/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/RVIPLab4/SecondTutorial/NewTask/obj
|
||||
/aleikin_artem_lab_4/RVIPLab4/SecondTutorial/Worker/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/RVIPLab4/SecondTutorial/Worker/obj
|
||||
/aleikin_artem_lab_4/RVIPLab4/ThirdTutorial/EmitLog/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/RVIPLab4/ThirdTutorial/EmitLog/obj
|
||||
/aleikin_artem_lab_4/RVIPLab4/ThirdTutorial/ReceiveLogs/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/RVIPLab4/ThirdTutorial/ReceiveLogs/obj
|
||||
/dozorova_alena_lab_2
|
||||
/dozorova_alena_lab_3
|
||||
/dozorova_alena_lab_4
|
||||
/dozorova_alena_lab_5/ConsoleApp1/obj
|
||||
/dozorova_alena_lab_6/ConsoleApp1/obj
|
||||
/aleikin_artem_lab_4/RVIPLab4/RVIPLab4.sln
|
||||
/aleikin_artem_lab_4/.vs
|
||||
/aleikin_artem_lab_4/Consumer1/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/Consumer1/obj
|
||||
/aleikin_artem_lab_4/Consumer2/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/Consumer2/obj
|
||||
/aleikin_artem_lab_4/FirstTutorial/Receive/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/FirstTutorial/Receive/obj
|
||||
/aleikin_artem_lab_4/FirstTutorial/Send/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/FirstTutorial/Send/obj
|
||||
/aleikin_artem_lab_4/Publisher/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/Publisher/obj
|
||||
/aleikin_artem_lab_4/SecondTutorial/NewTask/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/SecondTutorial/NewTask/obj
|
||||
/aleikin_artem_lab_4/SecondTutorial/Worker/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/SecondTutorial/Worker/obj
|
||||
/aleikin_artem_lab_4/ThirdTutorial/EmitLog/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/ThirdTutorial/EmitLog/obj
|
||||
/aleikin_artem_lab_4/ThirdTutorial/ReceiveLogs/bin/Debug/net8.0
|
||||
/aleikin_artem_lab_4/ThirdTutorial/ReceiveLogs/obj
|
||||
/aleikin_artem_lab_4/RVIPLab4.sln
|
||||
118
afanasev_dmitry_lab_6/FastDeterminantCalculator.java
Normal file
118
afanasev_dmitry_lab_6/FastDeterminantCalculator.java
Normal file
@ -0,0 +1,118 @@
|
||||
import java.math.BigDecimal;
|
||||
import java.math.MathContext;
|
||||
import java.math.RoundingMode;
|
||||
import java.util.concurrent.CountDownLatch;
|
||||
import java.util.concurrent.ExecutorService;
|
||||
import java.util.concurrent.Executors;
|
||||
|
||||
public class FastDeterminantCalculator {
|
||||
|
||||
public static void main(String[] args) {
|
||||
int[] sizes = {100, 300, 500};
|
||||
int[] threads = {1, 4, 8, 10};
|
||||
|
||||
for (int size : sizes) {
|
||||
BigDecimal[][] matrix = generateMatrix(size);
|
||||
for (int threadCount : threads) {
|
||||
long start = System.currentTimeMillis();
|
||||
BigDecimal determinant = calculateDeterminant(matrix, threadCount);
|
||||
long end = System.currentTimeMillis();
|
||||
System.out.printf("Matrix size: %dx%d, Threads: %d, Time: %d ms\n",
|
||||
size, size, threadCount, (end - start));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
public static BigDecimal[][] generateMatrix(int size) {
|
||||
BigDecimal[][] matrix = new BigDecimal[size][size];
|
||||
for (int i = 0; i < size; i++) {
|
||||
BigDecimal rowSum = BigDecimal.ZERO;
|
||||
for (int j = 0; j < size; j++) {
|
||||
matrix[i][j] = BigDecimal.valueOf(Math.random() * 10);
|
||||
if (i != j) {
|
||||
rowSum = rowSum.add(matrix[i][j]);
|
||||
}
|
||||
}
|
||||
matrix[i][i] = rowSum.add(BigDecimal.valueOf(Math.random() * 10 + 1));
|
||||
}
|
||||
return matrix;
|
||||
}
|
||||
|
||||
public static BigDecimal calculateDeterminant(BigDecimal[][] matrix, int threadCount) {
|
||||
int size = matrix.length;
|
||||
BigDecimal[][] lu = new BigDecimal[size][size];
|
||||
int[] permutations = new int[size];
|
||||
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
|
||||
|
||||
if (!luDecomposition(matrix, lu, permutations, executor)) {
|
||||
executor.shutdown();
|
||||
return BigDecimal.ZERO; // Матрица вырожденная
|
||||
}
|
||||
|
||||
executor.shutdown();
|
||||
|
||||
BigDecimal determinant = BigDecimal.ONE;
|
||||
for (int i = 0; i < size; i++) {
|
||||
determinant = determinant.multiply(lu[i][i]);
|
||||
if (permutations[i] != i) {
|
||||
determinant = determinant.negate(); // Меняем знак при перестановке
|
||||
}
|
||||
}
|
||||
return determinant;
|
||||
}
|
||||
|
||||
public static boolean luDecomposition(BigDecimal[][] matrix, BigDecimal[][] lu, int[] permutations, ExecutorService executor) {
|
||||
int size = matrix.length;
|
||||
|
||||
for (int i = 0; i < size; i++) {
|
||||
System.arraycopy(matrix[i], 0, lu[i], 0, size);
|
||||
permutations[i] = i;
|
||||
}
|
||||
|
||||
for (int k = 0; k < size; k++) {
|
||||
int pivot = k;
|
||||
for (int i = k + 1; i < size; i++) {
|
||||
if (lu[i][k].abs().compareTo(lu[pivot][k].abs()) > 0) {
|
||||
pivot = i;
|
||||
}
|
||||
}
|
||||
|
||||
if (lu[pivot][k].abs().compareTo(BigDecimal.valueOf(1e-10)) < 0) {
|
||||
return false;
|
||||
}
|
||||
|
||||
if (pivot != k) {
|
||||
BigDecimal[] temp = lu[k];
|
||||
lu[k] = lu[pivot];
|
||||
lu[pivot] = temp;
|
||||
|
||||
int tempPerm = permutations[k];
|
||||
permutations[k] = permutations[pivot];
|
||||
permutations[pivot] = tempPerm;
|
||||
}
|
||||
|
||||
CountDownLatch latch = new CountDownLatch(size - k - 1);
|
||||
for (int i = k + 1; i < size; i++) {
|
||||
int row = i;
|
||||
int finalK = k;
|
||||
executor.submit(() -> {
|
||||
MathContext mc = new MathContext(20, RoundingMode.HALF_UP);
|
||||
lu[row][finalK] = lu[row][finalK].divide(lu[finalK][finalK], mc);
|
||||
for (int j = finalK + 1; j < size; j++) {
|
||||
lu[row][j] = lu[row][j].subtract(lu[row][finalK].multiply(lu[finalK][j], mc));
|
||||
}
|
||||
latch.countDown();
|
||||
});
|
||||
}
|
||||
|
||||
try {
|
||||
latch.await();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
}
|
||||
31
afanasev_dmitry_lab_6/README.md
Normal file
31
afanasev_dmitry_lab_6/README.md
Normal file
@ -0,0 +1,31 @@
|
||||
# Лабораторная работа 6
|
||||
|
||||
## Описание
|
||||
Задание заключается в реализации алгоритмов нахождения детерминанта квадратной матрицы. Необходимо разработать два алгоритма: последовательный и параллельный. А также провести бенчмарки, а затем описать результаты в отчете.
|
||||
|
||||
**100x100 матрица**:
|
||||
- **8 потоков** — наилучший результат.
|
||||
- **10 потоков** — результат немного хуже.
|
||||
- **4 потока** — примерно такой же результат как на 10 потоках.
|
||||
- **1 поток** — наихудший результат.
|
||||
|
||||
**300x300 матрица**:
|
||||
- **10 потока** — лучший результат.
|
||||
- **8 потоков** — чуть хуже.
|
||||
- **4 потока** — ещё медленее.
|
||||
- **1 поток** — наихудший результат.
|
||||
|
||||
**500x500 матрица**:
|
||||
- **10 потока** — лучший результат.
|
||||
- **8 потоков** — чуть хуже.
|
||||
- **4 потока** — ещё медленее.
|
||||
- **1 поток** — наихудший результат.
|
||||
|
||||
**Ссылка на демонстрацию работы программы**: https://vkvideo.ru/video215756667_456239456?list=ln-W6TTsYuIRdX8ft7ADr
|
||||
|
||||
**Вывод**:
|
||||
- Если операция сложнее, рост производительности происходит с увеличением числа потоков.
|
||||
- Слишком много потоков увеличивает накладные расходы (замтено только на неочень сложных операциях). Это может быть связано, например, с:
|
||||
1. **Переключением контекстов**: Когда потоков больше, чем ядер процессора, операционная система часто переключает контексты, что занимает время.
|
||||
2. **Конкуренцией за ресурсы**: Много потоков конкурируют за ограниченные ресурсы, такие как процессорное время и кэш.
|
||||
3. **Управлением потоками**: С увеличением числа потоков растёт нагрузка на систему, связанную с их созданием, управлением и завершением.
|
||||
13
afanasev_dmitry_lab_7/README.md
Normal file
13
afanasev_dmitry_lab_7/README.md
Normal file
@ -0,0 +1,13 @@
|
||||
|
||||
Балансировка нагрузки — это способ распределения запросов между серверами для предотвращения их перегрузки и обеспечения быстродействия системы.
|
||||
Для этого используются алгоритмы, такие как Round Robin, Least Connections, IP Hash.
|
||||
|
||||
Среди популярных открытых технологий — Nginx, HAProxy и Traefik. Nginx часто работает как реверс-прокси,
|
||||
распределяя запросы и обрабатывая SSL. HAProxy подходит для высоконагруженных систем, а Traefik автоматически
|
||||
настраивает маршрутизацию в облачных кластерах.
|
||||
|
||||
В базах данных балансировка нагрузки позволяет направлять запросы на чтение к репликам, а на запись — к основному узлу.
|
||||
Инструменты, такие как ProxySQL, помогают автоматизировать этот процесс.
|
||||
|
||||
Реверс-прокси не только распределяет нагрузку, но и повышает безопасность системы, скрывая её внутреннюю архитектуру.
|
||||
Таким образом, открытые технологии играют ключевую роль в создании масштабируемых и надёжных систем.
|
||||
15
afanasev_dmitry_lab_8/README.md
Normal file
15
afanasev_dmitry_lab_8/README.md
Normal file
@ -0,0 +1,15 @@
|
||||
Распределённые системы являются основой современных сервисов, включая социальные сети. Их устройство предполагает разделение задач на микросервисы,
|
||||
где каждый компонент выполняет узкоспециализированную функцию. Это упрощает разработку, позволяет масштабировать только необходимые части системы и
|
||||
делает её более устойчивой к сбоям.
|
||||
|
||||
Для управления такими системами используются инструменты оркестрации, например, Kubernetes и Docker Swarm. Они автоматизируют развёртывание,
|
||||
масштабирование и обновление сервисов, упрощая сопровождение. Однако их использование требует опыта и может осложнить отладку.
|
||||
|
||||
Очереди сообщений, такие как RabbitMQ или Kafka, помогают асинхронно передавать данные между сервисами. Это снижает нагрузку и обеспечивает надёжное взаимодействие,
|
||||
передавая запросы, уведомления или данные для обработки.
|
||||
|
||||
Распределённые системы обладают преимуществами в виде масштабируемости, устойчивости и гибкости разработки.
|
||||
Однако их сложность может стать серьёзным вызовом при проектировании и сопровождении.
|
||||
|
||||
Параллельные вычисления полезны, например, для обработки больших объёмов данных или машинного обучения,
|
||||
но в некоторых случаях последовательная обработка более предпочтительна. Такой подход требует анализа задач, чтобы избежать излишней сложности.
|
||||
30
aleikin_artem_lab_4/Consumer1/.dockerignore
Normal file
30
aleikin_artem_lab_4/Consumer1/.dockerignore
Normal file
@ -0,0 +1,30 @@
|
||||
**/.classpath
|
||||
**/.dockerignore
|
||||
**/.env
|
||||
**/.git
|
||||
**/.gitignore
|
||||
**/.project
|
||||
**/.settings
|
||||
**/.toolstarget
|
||||
**/.vs
|
||||
**/.vscode
|
||||
**/*.*proj.user
|
||||
**/*.dbmdl
|
||||
**/*.jfm
|
||||
**/azds.yaml
|
||||
**/bin
|
||||
**/charts
|
||||
**/docker-compose*
|
||||
**/Dockerfile*
|
||||
**/node_modules
|
||||
**/npm-debug.log
|
||||
**/obj
|
||||
**/secrets.dev.yaml
|
||||
**/values.dev.yaml
|
||||
LICENSE
|
||||
README.md
|
||||
!**/.gitignore
|
||||
!.git/HEAD
|
||||
!.git/config
|
||||
!.git/packed-refs
|
||||
!.git/refs/heads/**
|
||||
17
aleikin_artem_lab_4/Consumer1/Consumer1.csproj
Normal file
17
aleikin_artem_lab_4/Consumer1/Consumer1.csproj
Normal file
@ -0,0 +1,17 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk">
|
||||
|
||||
<PropertyGroup>
|
||||
<OutputType>Exe</OutputType>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<Nullable>enable</Nullable>
|
||||
<DockerDefaultTargetOS>Linux</DockerDefaultTargetOS>
|
||||
<DockerfileContext>.</DockerfileContext>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="Microsoft.VisualStudio.Azure.Containers.Tools.Targets" Version="1.21.0" />
|
||||
<PackageReference Include="RabbitMQ.Client" Version="7.0.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
6
aleikin_artem_lab_4/Consumer1/Consumer1.csproj.user
Normal file
6
aleikin_artem_lab_4/Consumer1/Consumer1.csproj.user
Normal file
@ -0,0 +1,6 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<Project ToolsVersion="Current" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
|
||||
<PropertyGroup>
|
||||
<ActiveDebugProfile>Container (Dockerfile)</ActiveDebugProfile>
|
||||
</PropertyGroup>
|
||||
</Project>
|
||||
28
aleikin_artem_lab_4/Consumer1/Dockerfile
Normal file
28
aleikin_artem_lab_4/Consumer1/Dockerfile
Normal file
@ -0,0 +1,28 @@
|
||||
# См. статью по ссылке https://aka.ms/customizecontainer, чтобы узнать как настроить контейнер отладки и как Visual Studio использует этот Dockerfile для создания образов для ускорения отладки.
|
||||
|
||||
# Этот этап используется при запуске из VS в быстром режиме (по умолчанию для конфигурации отладки)
|
||||
FROM mcr.microsoft.com/dotnet/runtime:8.0 AS base
|
||||
USER app
|
||||
WORKDIR /app
|
||||
|
||||
|
||||
# Этот этап используется для сборки проекта службы
|
||||
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
WORKDIR /src
|
||||
COPY ["Consumer1.csproj", "."]
|
||||
RUN dotnet restore "./Consumer1.csproj"
|
||||
COPY . .
|
||||
WORKDIR "/src/."
|
||||
RUN dotnet build "./Consumer1.csproj" -c $BUILD_CONFIGURATION -o /app/build
|
||||
|
||||
# Этот этап используется для публикации проекта службы, который будет скопирован на последний этап
|
||||
FROM build AS publish
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
RUN dotnet publish "./Consumer1.csproj" -c $BUILD_CONFIGURATION -o /app/publish /p:UseAppHost=false
|
||||
|
||||
# Этот этап используется в рабочей среде или при запуске из VS в обычном режиме (по умолчанию, когда конфигурация отладки не используется)
|
||||
FROM base AS final
|
||||
WORKDIR /app
|
||||
COPY --from=publish /app/publish .
|
||||
ENTRYPOINT ["dotnet", "Consumer1.dll"]
|
||||
39
aleikin_artem_lab_4/Consumer1/Program.cs
Normal file
39
aleikin_artem_lab_4/Consumer1/Program.cs
Normal file
@ -0,0 +1,39 @@
|
||||
using RabbitMQ.Client;
|
||||
using RabbitMQ.Client.Events;
|
||||
using System.Text;
|
||||
|
||||
var factory = new ConnectionFactory
|
||||
{
|
||||
HostName = "rabbitmq",
|
||||
UserName = "admin",
|
||||
Password = "admin"
|
||||
};
|
||||
using var connection = await factory.CreateConnectionAsync();
|
||||
using var channel = await connection.CreateChannelAsync();
|
||||
|
||||
var queueName = "slow_queue";
|
||||
var exchangeName = "logs_exchange";
|
||||
await channel.QueueDeclareAsync(queue: queueName, durable: true, exclusive: false, autoDelete: false, arguments: null);
|
||||
|
||||
await channel.QueueBindAsync(queue: queueName, exchange: exchangeName, routingKey: "");
|
||||
|
||||
Console.WriteLine("[Consumer1] Waiting for messages...");
|
||||
|
||||
while (true)
|
||||
{
|
||||
var consumer = new AsyncEventingBasicConsumer(channel);
|
||||
consumer.ReceivedAsync += (model, ea) =>
|
||||
{
|
||||
var body = ea.Body.ToArray();
|
||||
var message = Encoding.UTF8.GetString(body);
|
||||
Console.WriteLine($"[Consumer1] Received: {message}");
|
||||
|
||||
Thread.Sleep(new Random().Next(2000, 3000));
|
||||
|
||||
Console.WriteLine("[Consumer1] Done processing");
|
||||
channel.BasicAckAsync(deliveryTag: ea.DeliveryTag, multiple: false);
|
||||
return Task.CompletedTask;
|
||||
};
|
||||
|
||||
await channel.BasicConsumeAsync(queue: queueName, autoAck: false, consumer: consumer);
|
||||
}
|
||||
10
aleikin_artem_lab_4/Consumer1/Properties/launchSettings.json
Normal file
10
aleikin_artem_lab_4/Consumer1/Properties/launchSettings.json
Normal file
@ -0,0 +1,10 @@
|
||||
{
|
||||
"profiles": {
|
||||
"Consumer1": {
|
||||
"commandName": "Project"
|
||||
},
|
||||
"Container (Dockerfile)": {
|
||||
"commandName": "Docker"
|
||||
}
|
||||
}
|
||||
}
|
||||
30
aleikin_artem_lab_4/Consumer2/.dockerignore
Normal file
30
aleikin_artem_lab_4/Consumer2/.dockerignore
Normal file
@ -0,0 +1,30 @@
|
||||
**/.classpath
|
||||
**/.dockerignore
|
||||
**/.env
|
||||
**/.git
|
||||
**/.gitignore
|
||||
**/.project
|
||||
**/.settings
|
||||
**/.toolstarget
|
||||
**/.vs
|
||||
**/.vscode
|
||||
**/*.*proj.user
|
||||
**/*.dbmdl
|
||||
**/*.jfm
|
||||
**/azds.yaml
|
||||
**/bin
|
||||
**/charts
|
||||
**/docker-compose*
|
||||
**/Dockerfile*
|
||||
**/node_modules
|
||||
**/npm-debug.log
|
||||
**/obj
|
||||
**/secrets.dev.yaml
|
||||
**/values.dev.yaml
|
||||
LICENSE
|
||||
README.md
|
||||
!**/.gitignore
|
||||
!.git/HEAD
|
||||
!.git/config
|
||||
!.git/packed-refs
|
||||
!.git/refs/heads/**
|
||||
17
aleikin_artem_lab_4/Consumer2/Consumer2.csproj
Normal file
17
aleikin_artem_lab_4/Consumer2/Consumer2.csproj
Normal file
@ -0,0 +1,17 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk">
|
||||
|
||||
<PropertyGroup>
|
||||
<OutputType>Exe</OutputType>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<Nullable>enable</Nullable>
|
||||
<DockerDefaultTargetOS>Linux</DockerDefaultTargetOS>
|
||||
<DockerfileContext>.</DockerfileContext>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="Microsoft.VisualStudio.Azure.Containers.Tools.Targets" Version="1.21.0" />
|
||||
<PackageReference Include="RabbitMQ.Client" Version="7.0.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
6
aleikin_artem_lab_4/Consumer2/Consumer2.csproj.user
Normal file
6
aleikin_artem_lab_4/Consumer2/Consumer2.csproj.user
Normal file
@ -0,0 +1,6 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<Project ToolsVersion="Current" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
|
||||
<PropertyGroup>
|
||||
<ActiveDebugProfile>Container (Dockerfile)</ActiveDebugProfile>
|
||||
</PropertyGroup>
|
||||
</Project>
|
||||
28
aleikin_artem_lab_4/Consumer2/Dockerfile
Normal file
28
aleikin_artem_lab_4/Consumer2/Dockerfile
Normal file
@ -0,0 +1,28 @@
|
||||
# См. статью по ссылке https://aka.ms/customizecontainer, чтобы узнать как настроить контейнер отладки и как Visual Studio использует этот Dockerfile для создания образов для ускорения отладки.
|
||||
|
||||
# Этот этап используется при запуске из VS в быстром режиме (по умолчанию для конфигурации отладки)
|
||||
FROM mcr.microsoft.com/dotnet/runtime:8.0 AS base
|
||||
USER app
|
||||
WORKDIR /app
|
||||
|
||||
|
||||
# Этот этап используется для сборки проекта службы
|
||||
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
WORKDIR /src
|
||||
COPY ["Consumer2.csproj", "."]
|
||||
RUN dotnet restore "./Consumer2.csproj"
|
||||
COPY . .
|
||||
WORKDIR "/src/."
|
||||
RUN dotnet build "./Consumer2.csproj" -c $BUILD_CONFIGURATION -o /app/build
|
||||
|
||||
# Этот этап используется для публикации проекта службы, который будет скопирован на последний этап
|
||||
FROM build AS publish
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
RUN dotnet publish "./Consumer2.csproj" -c $BUILD_CONFIGURATION -o /app/publish /p:UseAppHost=false
|
||||
|
||||
# Этот этап используется в рабочей среде или при запуске из VS в обычном режиме (по умолчанию, когда конфигурация отладки не используется)
|
||||
FROM base AS final
|
||||
WORKDIR /app
|
||||
COPY --from=publish /app/publish .
|
||||
ENTRYPOINT ["dotnet", "Consumer2.dll"]
|
||||
40
aleikin_artem_lab_4/Consumer2/Program.cs
Normal file
40
aleikin_artem_lab_4/Consumer2/Program.cs
Normal file
@ -0,0 +1,40 @@
|
||||
using RabbitMQ.Client;
|
||||
using RabbitMQ.Client.Events;
|
||||
using System.Data.Common;
|
||||
using System.Text;
|
||||
using System.Threading.Channels;
|
||||
|
||||
var factory = new ConnectionFactory
|
||||
{
|
||||
HostName = "rabbitmq",
|
||||
UserName = "admin",
|
||||
Password = "admin"
|
||||
};
|
||||
using var connection = await factory.CreateConnectionAsync();
|
||||
using var channel = await connection.CreateChannelAsync();
|
||||
|
||||
var queueName = "fast_queue";
|
||||
var exchangeName = "logs_exchange";
|
||||
await channel.QueueDeclareAsync(queue: queueName, durable: true, exclusive: false, autoDelete: false, arguments: null);
|
||||
|
||||
await channel.QueueBindAsync(queue: queueName, exchange: exchangeName, routingKey: "");
|
||||
|
||||
Console.WriteLine("[Consumer2] Waiting for messages...");
|
||||
|
||||
while (true)
|
||||
{
|
||||
var consumer = new AsyncEventingBasicConsumer(channel);
|
||||
consumer.ReceivedAsync += (model, ea) =>
|
||||
{
|
||||
var body = ea.Body.ToArray();
|
||||
var message = Encoding.UTF8.GetString(body);
|
||||
Console.WriteLine($"[Consumer2] Received: {message}");
|
||||
|
||||
Console.WriteLine("[Consumer2] Done processing");
|
||||
channel.BasicAckAsync(deliveryTag: ea.DeliveryTag, multiple: false);
|
||||
return Task.CompletedTask;
|
||||
};
|
||||
|
||||
await channel.BasicConsumeAsync(queue: queueName, autoAck: false, consumer: consumer);
|
||||
}
|
||||
|
||||
10
aleikin_artem_lab_4/Consumer2/Properties/launchSettings.json
Normal file
10
aleikin_artem_lab_4/Consumer2/Properties/launchSettings.json
Normal file
@ -0,0 +1,10 @@
|
||||
{
|
||||
"profiles": {
|
||||
"Consumer2": {
|
||||
"commandName": "Project"
|
||||
},
|
||||
"Container (Dockerfile)": {
|
||||
"commandName": "Docker"
|
||||
}
|
||||
}
|
||||
}
|
||||
26
aleikin_artem_lab_4/FirstTutorial/Receive/Receive.cs
Normal file
26
aleikin_artem_lab_4/FirstTutorial/Receive/Receive.cs
Normal file
@ -0,0 +1,26 @@
|
||||
using RabbitMQ.Client;
|
||||
using RabbitMQ.Client.Events;
|
||||
using System.Text;
|
||||
|
||||
var factory = new ConnectionFactory { HostName = "localhost" };
|
||||
using var connection = await factory.CreateConnectionAsync();
|
||||
using var channel = await connection.CreateChannelAsync();
|
||||
|
||||
await channel.QueueDeclareAsync(queue: "hello", durable: false,
|
||||
exclusive: false, autoDelete: false,arguments: null);
|
||||
|
||||
Console.WriteLine("[*] Waiting for messages...");
|
||||
|
||||
var consumer = new AsyncEventingBasicConsumer(channel);
|
||||
consumer.ReceivedAsync += (model, ea) =>
|
||||
{
|
||||
var body = ea.Body.ToArray();
|
||||
var message = Encoding.UTF8.GetString(body);
|
||||
Console.WriteLine($" [*] Received {message}");
|
||||
return Task.CompletedTask;
|
||||
};
|
||||
|
||||
await channel.BasicConsumeAsync("hello", autoAck: true, consumer: consumer);
|
||||
|
||||
Console.WriteLine(" Press [enter] to exit.");
|
||||
Console.ReadLine();
|
||||
14
aleikin_artem_lab_4/FirstTutorial/Receive/Receive.csproj
Normal file
14
aleikin_artem_lab_4/FirstTutorial/Receive/Receive.csproj
Normal file
@ -0,0 +1,14 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk">
|
||||
|
||||
<PropertyGroup>
|
||||
<OutputType>Exe</OutputType>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<Nullable>enable</Nullable>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="RabbitMQ.Client" Version="7.0.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
18
aleikin_artem_lab_4/FirstTutorial/Send/Send.cs
Normal file
18
aleikin_artem_lab_4/FirstTutorial/Send/Send.cs
Normal file
@ -0,0 +1,18 @@
|
||||
using RabbitMQ.Client;
|
||||
using System.Text;
|
||||
|
||||
var factory = new ConnectionFactory { HostName = "localhost" };
|
||||
using var connection = await factory.CreateConnectionAsync();
|
||||
using var channel = await connection.CreateChannelAsync();
|
||||
|
||||
await channel.QueueDeclareAsync(queue: "hello", durable: false,
|
||||
exclusive: false, autoDelete: false, arguments: null);
|
||||
|
||||
const string message = "Hello, World! ~from Artem";
|
||||
var body = Encoding.UTF8.GetBytes(message);
|
||||
|
||||
await channel.BasicPublishAsync(exchange: string.Empty, routingKey: "hello", body: body);
|
||||
Console.WriteLine($" [x] Sent {message}");
|
||||
|
||||
Console.WriteLine(" Press [enter] to exit.");
|
||||
Console.ReadLine();
|
||||
14
aleikin_artem_lab_4/FirstTutorial/Send/Send.csproj
Normal file
14
aleikin_artem_lab_4/FirstTutorial/Send/Send.csproj
Normal file
@ -0,0 +1,14 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk">
|
||||
|
||||
<PropertyGroup>
|
||||
<OutputType>Exe</OutputType>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<Nullable>enable</Nullable>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="RabbitMQ.Client" Version="7.0.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
BIN
aleikin_artem_lab_4/Images/Лаба_Отчет1.png
Normal file
BIN
aleikin_artem_lab_4/Images/Лаба_Отчет1.png
Normal file
{kind=link}
Binary file not shown.
|
After 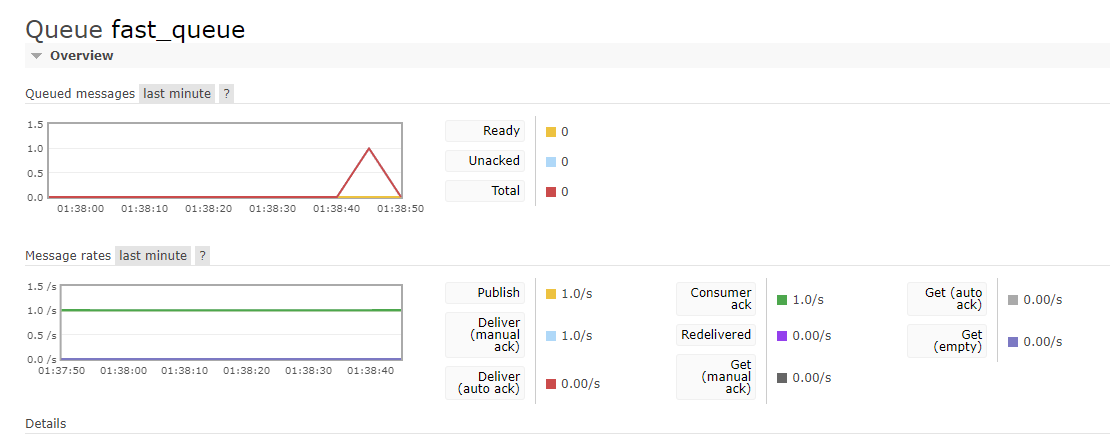
(image error) Size: 31 KiB |
BIN
aleikin_artem_lab_4/Images/Лаба_Отчет2.png
Normal file
BIN
aleikin_artem_lab_4/Images/Лаба_Отчет2.png
Normal file
{kind=link}
Binary file not shown.
|
After 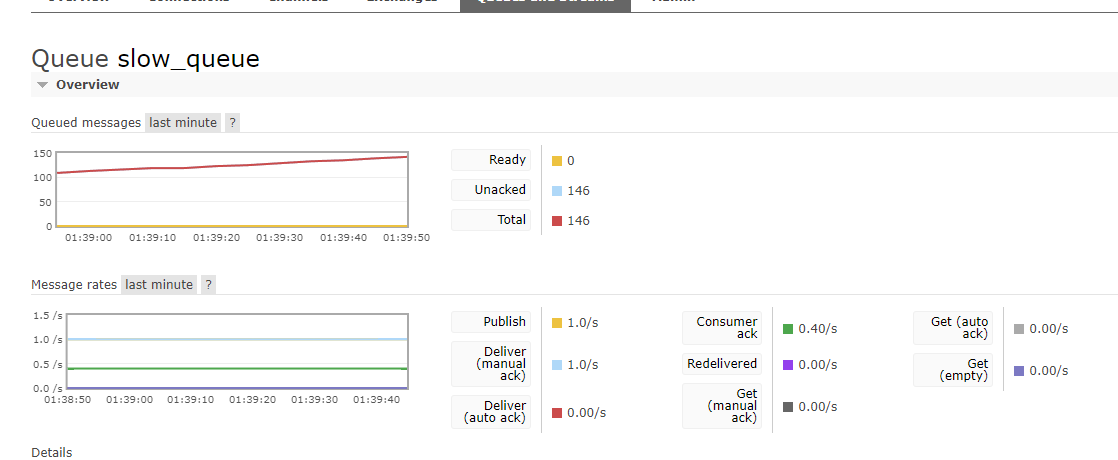
(image error) Size: 32 KiB |
BIN
aleikin_artem_lab_4/Images/Лаба_Отчет3.png
Normal file
BIN
aleikin_artem_lab_4/Images/Лаба_Отчет3.png
Normal file
{kind=link}
Binary file not shown.
|
After 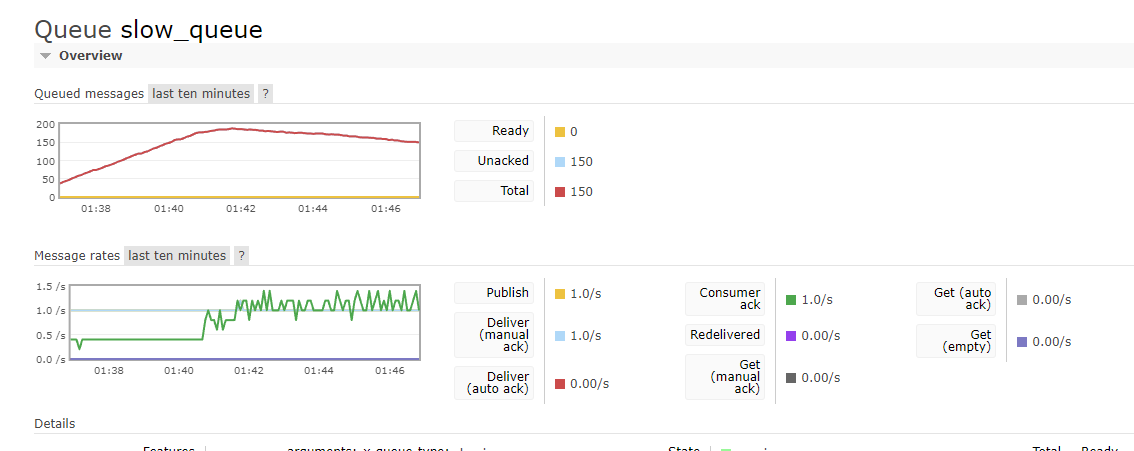
(image error) Size: 38 KiB |
BIN
aleikin_artem_lab_4/Images/Лаба_Отчет4.png
Normal file
BIN
aleikin_artem_lab_4/Images/Лаба_Отчет4.png
Normal file
{kind=link}
Binary file not shown.
|
After 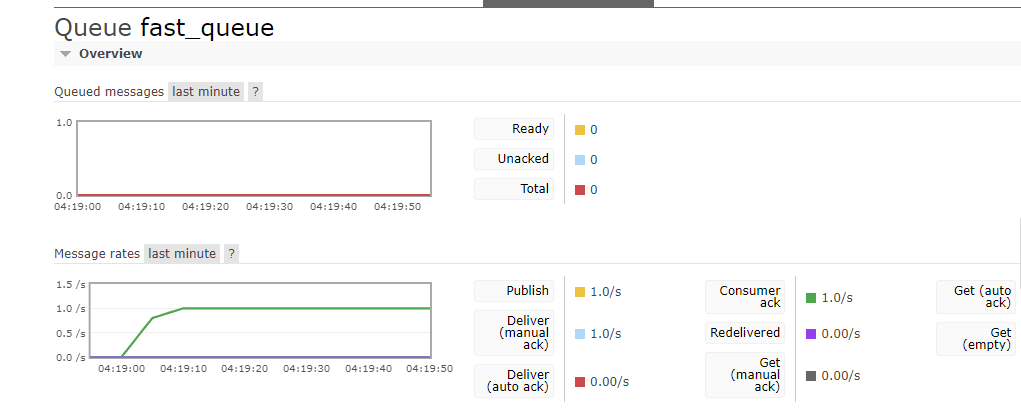
(image error) Size: 29 KiB |
BIN
aleikin_artem_lab_4/Images/Туториал_1.png
Normal file
BIN
aleikin_artem_lab_4/Images/Туториал_1.png
Normal file
{kind=link}
Binary file not shown.
|
After 
(image error) Size: 60 KiB |
BIN
aleikin_artem_lab_4/Images/Туториал_2.png
Normal file
BIN
aleikin_artem_lab_4/Images/Туториал_2.png
Normal file
{kind=link}
Binary file not shown.
|
After 
(image error) Size: 147 KiB |
BIN
aleikin_artem_lab_4/Images/Туториал_3.png
Normal file
BIN
aleikin_artem_lab_4/Images/Туториал_3.png
Normal file
{kind=link}
Binary file not shown.
|
After 
(image error) Size: 69 KiB |
30
aleikin_artem_lab_4/Publisher/.dockerignore
Normal file
30
aleikin_artem_lab_4/Publisher/.dockerignore
Normal file
@ -0,0 +1,30 @@
|
||||
**/.classpath
|
||||
**/.dockerignore
|
||||
**/.env
|
||||
**/.git
|
||||
**/.gitignore
|
||||
**/.project
|
||||
**/.settings
|
||||
**/.toolstarget
|
||||
**/.vs
|
||||
**/.vscode
|
||||
**/*.*proj.user
|
||||
**/*.dbmdl
|
||||
**/*.jfm
|
||||
**/azds.yaml
|
||||
**/bin
|
||||
**/charts
|
||||
**/docker-compose*
|
||||
**/Dockerfile*
|
||||
**/node_modules
|
||||
**/npm-debug.log
|
||||
**/obj
|
||||
**/secrets.dev.yaml
|
||||
**/values.dev.yaml
|
||||
LICENSE
|
||||
README.md
|
||||
!**/.gitignore
|
||||
!.git/HEAD
|
||||
!.git/config
|
||||
!.git/packed-refs
|
||||
!.git/refs/heads/**
|
||||
28
aleikin_artem_lab_4/Publisher/Dockerfile
Normal file
28
aleikin_artem_lab_4/Publisher/Dockerfile
Normal file
@ -0,0 +1,28 @@
|
||||
# См. статью по ссылке https://aka.ms/customizecontainer, чтобы узнать как настроить контейнер отладки и как Visual Studio использует этот Dockerfile для создания образов для ускорения отладки.
|
||||
|
||||
# Этот этап используется при запуске из VS в быстром режиме (по умолчанию для конфигурации отладки)
|
||||
FROM mcr.microsoft.com/dotnet/runtime:8.0 AS base
|
||||
USER app
|
||||
WORKDIR /app
|
||||
|
||||
|
||||
# Этот этап используется для сборки проекта службы
|
||||
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
WORKDIR /src
|
||||
COPY ["Publisher.csproj", "."]
|
||||
RUN dotnet restore "./Publisher.csproj"
|
||||
COPY . .
|
||||
WORKDIR "/src/."
|
||||
RUN dotnet build "./Publisher.csproj" -c $BUILD_CONFIGURATION -o /app/build
|
||||
|
||||
# Этот этап используется для публикации проекта службы, который будет скопирован на последний этап
|
||||
FROM build AS publish
|
||||
ARG BUILD_CONFIGURATION=Release
|
||||
RUN dotnet publish "./Publisher.csproj" -c $BUILD_CONFIGURATION -o /app/publish /p:UseAppHost=false
|
||||
|
||||
# Этот этап используется в рабочей среде или при запуске из VS в обычном режиме (по умолчанию, когда конфигурация отладки не используется)
|
||||
FROM base AS final
|
||||
WORKDIR /app
|
||||
COPY --from=publish /app/publish .
|
||||
ENTRYPOINT ["dotnet", "Publisher.dll"]
|
||||
10
aleikin_artem_lab_4/Publisher/Properties/launchSettings.json
Normal file
10
aleikin_artem_lab_4/Publisher/Properties/launchSettings.json
Normal file
@ -0,0 +1,10 @@
|
||||
{
|
||||
"profiles": {
|
||||
"Publisher": {
|
||||
"commandName": "Project"
|
||||
},
|
||||
"Container (Dockerfile)": {
|
||||
"commandName": "Docker"
|
||||
}
|
||||
}
|
||||
}
|
||||
31
aleikin_artem_lab_4/Publisher/Publisher.cs
Normal file
31
aleikin_artem_lab_4/Publisher/Publisher.cs
Normal file
@ -0,0 +1,31 @@
|
||||
using RabbitMQ.Client;
|
||||
using System.Text;
|
||||
|
||||
var factory = new ConnectionFactory
|
||||
{
|
||||
HostName = "rabbitmq",
|
||||
UserName = "admin",
|
||||
Password = "admin"
|
||||
};
|
||||
using var connection = await factory.CreateConnectionAsync();
|
||||
Console.WriteLine("Connection established.");
|
||||
using var channel = await connection.CreateChannelAsync();
|
||||
Console.WriteLine("Channel created.");
|
||||
|
||||
await channel.ExchangeDeclareAsync(exchange: "logs_exchange", type: ExchangeType.Fanout);
|
||||
|
||||
while (true)
|
||||
{
|
||||
var message = $"Event: {GenerateRandomEvent()}";
|
||||
var body = Encoding.UTF8.GetBytes(message);
|
||||
|
||||
await channel.BasicPublishAsync(exchange: "logs_exchange", routingKey: string.Empty, body: body);
|
||||
Console.WriteLine($"[Publisher] Sent: {message}");
|
||||
await Task.Delay(1000);
|
||||
}
|
||||
|
||||
static string GenerateRandomEvent()
|
||||
{
|
||||
var events = new[] { "Order Received", "User Message", "Create Report" };
|
||||
return events[new Random().Next(events.Length)] + " #" + new Random().Next(0, 99);
|
||||
}
|
||||
17
aleikin_artem_lab_4/Publisher/Publisher.csproj
Normal file
17
aleikin_artem_lab_4/Publisher/Publisher.csproj
Normal file
@ -0,0 +1,17 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk">
|
||||
|
||||
<PropertyGroup>
|
||||
<OutputType>Exe</OutputType>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<Nullable>enable</Nullable>
|
||||
<DockerDefaultTargetOS>Linux</DockerDefaultTargetOS>
|
||||
<DockerfileContext>.</DockerfileContext>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="Microsoft.VisualStudio.Azure.Containers.Tools.Targets" Version="1.21.0" />
|
||||
<PackageReference Include="RabbitMQ.Client" Version="7.0.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
6
aleikin_artem_lab_4/Publisher/Publisher.csproj.user
Normal file
6
aleikin_artem_lab_4/Publisher/Publisher.csproj.user
Normal file
@ -0,0 +1,6 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<Project ToolsVersion="Current" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
|
||||
<PropertyGroup>
|
||||
<ActiveDebugProfile>Container (Dockerfile)</ActiveDebugProfile>
|
||||
</PropertyGroup>
|
||||
</Project>
|
||||
14
aleikin_artem_lab_4/SecondTutorial/NewTask/NewTask.csproj
Normal file
14
aleikin_artem_lab_4/SecondTutorial/NewTask/NewTask.csproj
Normal file
@ -0,0 +1,14 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk">
|
||||
|
||||
<PropertyGroup>
|
||||
<OutputType>Exe</OutputType>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<Nullable>enable</Nullable>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="RabbitMQ.Client" Version="7.0.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
26
aleikin_artem_lab_4/SecondTutorial/NewTask/Program.cs
Normal file
26
aleikin_artem_lab_4/SecondTutorial/NewTask/Program.cs
Normal file
@ -0,0 +1,26 @@
|
||||
using RabbitMQ.Client;
|
||||
using System.Text;
|
||||
|
||||
var factory = new ConnectionFactory { HostName = "localhost" };
|
||||
using var connection = await factory.CreateConnectionAsync();
|
||||
using var channel = await connection.CreateChannelAsync();
|
||||
|
||||
await channel.QueueDeclareAsync(queue: "task_queue", durable: true, exclusive: false,
|
||||
autoDelete: false, arguments: null);
|
||||
|
||||
var message = GetMessage(args);
|
||||
var body = Encoding.UTF8.GetBytes(message);
|
||||
|
||||
var properties = new BasicProperties
|
||||
{
|
||||
Persistent = true
|
||||
};
|
||||
|
||||
await channel.BasicPublishAsync(exchange: string.Empty, routingKey: "task_queue", mandatory: true,
|
||||
basicProperties: properties, body: body);
|
||||
Console.WriteLine($" [x] Sent {message}");
|
||||
|
||||
static string GetMessage(string[] args)
|
||||
{
|
||||
return ((args.Length > 0) ? string.Join(" ", args) : "Hello World!");
|
||||
}
|
||||
35
aleikin_artem_lab_4/SecondTutorial/Worker/Program.cs
Normal file
35
aleikin_artem_lab_4/SecondTutorial/Worker/Program.cs
Normal file
@ -0,0 +1,35 @@
|
||||
using RabbitMQ.Client;
|
||||
using RabbitMQ.Client.Events;
|
||||
using System.Text;
|
||||
|
||||
var factory = new ConnectionFactory { HostName = "localhost" };
|
||||
using var connection = await factory.CreateConnectionAsync();
|
||||
using var channel = await connection.CreateChannelAsync();
|
||||
|
||||
await channel.QueueDeclareAsync(queue: "task_queue", durable: true, exclusive: false,
|
||||
autoDelete: false, arguments: null);
|
||||
|
||||
await channel.BasicQosAsync(prefetchSize: 0, prefetchCount: 1, global: false);
|
||||
|
||||
Console.WriteLine(" [*] Waiting for messages.");
|
||||
|
||||
var consumer = new AsyncEventingBasicConsumer(channel);
|
||||
consumer.ReceivedAsync += async (model, ea) =>
|
||||
{
|
||||
byte[] body = ea.Body.ToArray();
|
||||
var message = Encoding.UTF8.GetString(body);
|
||||
Console.WriteLine($" [x] Received {message}");
|
||||
|
||||
int dots = message.Split('.').Length - 1;
|
||||
await Task.Delay(dots * 1000);
|
||||
|
||||
Console.WriteLine(" [x] Done");
|
||||
|
||||
// here channel could also be accessed as ((AsyncEventingBasicConsumer)sender).Channel
|
||||
await channel.BasicAckAsync(deliveryTag: ea.DeliveryTag, multiple: false);
|
||||
};
|
||||
|
||||
await channel.BasicConsumeAsync("task_queue", autoAck: false, consumer: consumer);
|
||||
|
||||
Console.WriteLine(" Press [enter] to exit.");
|
||||
Console.ReadLine();
|
||||
14
aleikin_artem_lab_4/SecondTutorial/Worker/Worker.csproj
Normal file
14
aleikin_artem_lab_4/SecondTutorial/Worker/Worker.csproj
Normal file
@ -0,0 +1,14 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk">
|
||||
|
||||
<PropertyGroup>
|
||||
<OutputType>Exe</OutputType>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<Nullable>enable</Nullable>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="RabbitMQ.Client" Version="7.0.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
21
aleikin_artem_lab_4/ThirdTutorial/EmitLog/EmitLog.cs
Normal file
21
aleikin_artem_lab_4/ThirdTutorial/EmitLog/EmitLog.cs
Normal file
@ -0,0 +1,21 @@
|
||||
using RabbitMQ.Client;
|
||||
using System.Text;
|
||||
|
||||
var factory = new ConnectionFactory { HostName = "localhost" };
|
||||
using var connection = await factory.CreateConnectionAsync();
|
||||
using var channel = await connection.CreateChannelAsync();
|
||||
|
||||
await channel.ExchangeDeclareAsync(exchange: "logs", type: ExchangeType.Fanout);
|
||||
|
||||
var message = GetMessage(args);
|
||||
var body = Encoding.UTF8.GetBytes(message);
|
||||
await channel.BasicPublishAsync(exchange: "logs", routingKey: string.Empty, body: body);
|
||||
Console.WriteLine($" [x] Sent {message}");
|
||||
|
||||
Console.WriteLine(" Press [enter] to exit.");
|
||||
Console.ReadLine();
|
||||
|
||||
static string GetMessage(string[] args)
|
||||
{
|
||||
return ((args.Length > 0) ? string.Join(" ", args) : "info: Hello World!");
|
||||
}
|
||||
14
aleikin_artem_lab_4/ThirdTutorial/EmitLog/EmitLog.csproj
Normal file
14
aleikin_artem_lab_4/ThirdTutorial/EmitLog/EmitLog.csproj
Normal file
@ -0,0 +1,14 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk">
|
||||
|
||||
<PropertyGroup>
|
||||
<OutputType>Exe</OutputType>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<Nullable>enable</Nullable>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="RabbitMQ.Client" Version="7.0.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
31
aleikin_artem_lab_4/ThirdTutorial/ReceiveLogs/ReceiveLogs.cs
Normal file
31
aleikin_artem_lab_4/ThirdTutorial/ReceiveLogs/ReceiveLogs.cs
Normal file
@ -0,0 +1,31 @@
|
||||
using RabbitMQ.Client;
|
||||
using RabbitMQ.Client.Events;
|
||||
using System.Text;
|
||||
|
||||
var factory = new ConnectionFactory { HostName = "localhost" };
|
||||
using var connection = await factory.CreateConnectionAsync();
|
||||
using var channel = await connection.CreateChannelAsync();
|
||||
|
||||
await channel.ExchangeDeclareAsync(exchange: "logs",
|
||||
type: ExchangeType.Fanout);
|
||||
|
||||
// declare a server-named queue
|
||||
QueueDeclareOk queueDeclareResult = await channel.QueueDeclareAsync();
|
||||
string queueName = queueDeclareResult.QueueName;
|
||||
await channel.QueueBindAsync(queue: queueName, exchange: "logs", routingKey: string.Empty);
|
||||
|
||||
Console.WriteLine(" [*] Waiting for logs.");
|
||||
|
||||
var consumer = new AsyncEventingBasicConsumer(channel);
|
||||
consumer.ReceivedAsync += (model, ea) =>
|
||||
{
|
||||
byte[] body = ea.Body.ToArray();
|
||||
var message = Encoding.UTF8.GetString(body);
|
||||
Console.WriteLine($" [x] {message}");
|
||||
return Task.CompletedTask;
|
||||
};
|
||||
|
||||
await channel.BasicConsumeAsync(queueName, autoAck: true, consumer: consumer);
|
||||
|
||||
Console.WriteLine(" Press [enter] to exit.");
|
||||
Console.ReadLine();
|
||||
@ -0,0 +1,14 @@
|
||||
<Project Sdk="Microsoft.NET.Sdk">
|
||||
|
||||
<PropertyGroup>
|
||||
<OutputType>Exe</OutputType>
|
||||
<TargetFramework>net8.0</TargetFramework>
|
||||
<ImplicitUsings>enable</ImplicitUsings>
|
||||
<Nullable>enable</Nullable>
|
||||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="RabbitMQ.Client" Version="7.0.0" />
|
||||
</ItemGroup>
|
||||
|
||||
</Project>
|
||||
61
aleikin_artem_lab_4/docker-compose.yml
Normal file
61
aleikin_artem_lab_4/docker-compose.yml
Normal file
@ -0,0 +1,61 @@
|
||||
services:
|
||||
rabbitmq:
|
||||
image: rabbitmq:management
|
||||
container_name: rabbitmq
|
||||
restart: always
|
||||
ports:
|
||||
- "5672:5672"
|
||||
- "15672:15672"
|
||||
environment:
|
||||
RABBITMQ_DEFAULT_USER: admin
|
||||
RABBITMQ_DEFAULT_PASS: admin
|
||||
networks:
|
||||
- my_network
|
||||
|
||||
publisher:
|
||||
build:
|
||||
context: ./Publisher
|
||||
restart: always
|
||||
depends_on:
|
||||
- rabbitmq
|
||||
environment:
|
||||
RABBITMQ_HOST: rabbitmq
|
||||
RABBIT_USERNAME: admin
|
||||
RABBIT_PASSWORD: admin
|
||||
RABBIT_EXCHANGE: 'logs_exchange'
|
||||
networks:
|
||||
- my_network
|
||||
|
||||
consumer1:
|
||||
build:
|
||||
context: ./Consumer1
|
||||
restart: always
|
||||
depends_on:
|
||||
- rabbitmq
|
||||
environment:
|
||||
RABBITMQ_HOST: rabbitmq
|
||||
RABBIT_USERNAME: admin
|
||||
RABBIT_PASSWORD: admin
|
||||
RABBIT_EXCHANGE: 'logs_exchange'
|
||||
RABBIT_QUEUE: 'slow_queue'
|
||||
networks:
|
||||
- my_network
|
||||
|
||||
consumer2:
|
||||
build:
|
||||
context: ./Consumer2
|
||||
restart: always
|
||||
depends_on:
|
||||
- rabbitmq
|
||||
environment:
|
||||
RABBITMQ_HOST: rabbitmq
|
||||
RABBIT_USERNAME: admin
|
||||
RABBIT_PASSWORD: admin
|
||||
RABBIT_EXCHANGE: 'logs_exchange'
|
||||
RABBIT_QUEUE: 'fast_queue'
|
||||
networks:
|
||||
- my_network
|
||||
|
||||
networks:
|
||||
my_network:
|
||||
driver: bridge
|
||||
37
aleikin_artem_lab_4/readme.md
Normal file
37
aleikin_artem_lab_4/readme.md
Normal file
@ -0,0 +1,37 @@
|
||||
# Лабораторная работа 4 - Работа с брокером сообщений
|
||||
## ПИбд-42 || Алейкин Артем
|
||||
|
||||
### Описание
|
||||
В данной лабораторной работе мы познакомились с такой утилитой как RabbitMQ.
|
||||
|
||||
### Туториалы
|
||||
1. HelloWorld - Tutorial
|
||||

|
||||
|
||||
2. Work Queues - Tutorial
|
||||

|
||||
|
||||
3. Publish/Subscribe - Tutorial
|
||||

|
||||
|
||||
### Основное задание
|
||||
Было разработано 3 приложения: Publisher, Consumer1 и Consumer2.
|
||||
Первое отвечало за доставку сообщений в очереди. Оно генерирует одно сообщение раз в секунду.
|
||||
Второе и Третье за обработку этих сообщений из очередей, но Consumer1 имел искусственную задержку в 2-3 секунды, в то время как Consumer2 таких ограничений не имел и работу.
|
||||
|
||||
### Шаги для запуска:
|
||||
1. Запуск контейнеров:
|
||||
```
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
В результате мы можем посмотреть графики по этой ссылке http://localhost:15672/
|
||||

|
||||

|
||||
|
||||
После этого было добавлено еще 3 клиента типа Consumer1 и только после этого их суммарной производительности стало хватать для обработки сообщений.
|
||||

|
||||

|
||||
|
||||
|
||||
Видео демонстрации работы: https://vk.com/video248424990_456239611?list=ln-v0VkWDOiRBxdctENzV
|
||||
10
alkin_ivan_lab_2/.gitignore
vendored
Normal file
10
alkin_ivan_lab_2/.gitignore
vendored
Normal file
@ -0,0 +1,10 @@
|
||||
# .gitignore
|
||||
__pycache__/
|
||||
*.pyc
|
||||
*.pyo
|
||||
*.pyd
|
||||
*.db
|
||||
*.log
|
||||
*.bak
|
||||
*.swp
|
||||
*.swo
|
||||
89
alkin_ivan_lab_2/README.md
Normal file
89
alkin_ivan_lab_2/README.md
Normal file
@ -0,0 +1,89 @@
|
||||
Для выполнения второй лабораторной работы по созданию распределённого приложения с использованием Docker и Docker Compose, давайте разберем все этапы, шаг за шагом. Я предлагаю реализовать вариант программы 1 и программу 2 следующим образом:
|
||||
|
||||
### 1. Вариант программы 1
|
||||
Программа будет искать в каталоге `/var/data` файл с наибольшим количеством строк и перекладывать его в `/var/result/data.txt`.
|
||||
|
||||
### 2. Вариант программы 2
|
||||
Программа будет искать наименьшее число из файла `/var/data/data.txt` и сохранять его третью степень в файл `/var/result/result.txt`.
|
||||
|
||||
### Структура проекта
|
||||
|
||||
1. `moiseev-vv-lab_2/worker-1`: Программа для нахождения файла с наибольшим количеством строк.
|
||||
2. `moiseev-vv-lab_2/worker-2`: Программа для нахождения минимального числа в файле и записи его третьей степени.
|
||||
|
||||
### Шаги реализации:
|
||||
|
||||
#### 1. Реализация программы 1
|
||||
```python
|
||||
|
||||
|
||||
#### 2. Реализация программы 2
|
||||
```python
|
||||
|
||||
|
||||
|
||||
Для обоих приложений создадим Dockerfile. Вот пример для **worker-1**:
|
||||
|
||||
|
||||
|
||||
Пояснение:
|
||||
- **Stage 1**: Мы используем `python:3.10-slim` как образ для сборки, где копируем файл `main.py` и устанавливаем зависимости, если это необходимо.
|
||||
- **Stage 2**: В этом слое мы копируем скомпилированные файлы из предыдущего этапа и определяем команду для запуска приложения.
|
||||
|
||||
Аналогичный Dockerfile будет для **worker-2**.
|
||||
|
||||
### Docker Compose файл
|
||||
|
||||
Теперь нужно настроить файл `docker-compose.yml`, который позволит запустить оба приложения:
|
||||
|
||||
|
||||
|
||||
Пояснение:
|
||||
- **services**: Мы объявляем два сервиса — `worker-1` и `worker-2`.
|
||||
- **build**: Указываем контекст сборки для каждого сервиса (директории, где находятся Dockerfile и код).
|
||||
- **volumes**: Монтируем локальные директории `./data` и `./result` в контейнеры, чтобы обмениваться файлами между сервисами.
|
||||
- **depends_on**: Задаем зависимость `worker-2` от `worker-1`, чтобы второй сервис запускался только после первого.
|
||||
|
||||
### .gitignore
|
||||
|
||||
Для предотвращения попадания ненужных файлов в репозиторий, добавляем файл `.gitignore`. Пример для Python проектов:
|
||||
|
||||
```
|
||||
# .gitignore
|
||||
__pycache__/
|
||||
*.pyc
|
||||
*.pyo
|
||||
*.pyd
|
||||
*.db
|
||||
*.log
|
||||
*.bak
|
||||
*.swp
|
||||
*.swo
|
||||
```
|
||||
|
||||
### Шаги для сборки и запуска
|
||||
|
||||
1. Склонировать репозиторий и перейти в директорию с лабораторной работой:
|
||||
```bash
|
||||
git clone <репозиторий>
|
||||
cd moiseev-vv-lab_2
|
||||
```
|
||||
|
||||
2. Скопировать файлы для `worker-1` и `worker-2` в соответствующие папки.
|
||||
|
||||
3. Создать файл `docker-compose.yml`.
|
||||
|
||||
4. Запустить приложение с помощью команды:
|
||||
```bash
|
||||
docker-compose up --build
|
||||
```
|
||||
|
||||
5. Проверить вывод, результаты должны быть в директориях `./data` и `./result`.
|
||||
|
||||
### Заключение
|
||||
|
||||
Это пример, как можно реализовать простейшее распределённое приложение с использованием Docker. Первое приложение генерирует данные для второго, который обрабатывает их и записывает результат в файл. Docker и Docker Compose позволяют легко управлять и изолировать каждое приложение.ker Compose для запуска двух программ, обрабатывающих данные в контейнерах.
|
||||
|
||||
## Видео ВК
|
||||
|
||||
https://vkvideo.ru/video150882239_456240341
|
||||
7
alkin_ivan_lab_2/data_generator/Dockerfile
Normal file
7
alkin_ivan_lab_2/data_generator/Dockerfile
Normal file
@ -0,0 +1,7 @@
|
||||
FROM python:3.9-slim
|
||||
|
||||
WORKDIR /app
|
||||
|
||||
COPY . /app
|
||||
|
||||
CMD ["python", "generate_data.py"]
|
||||
29
alkin_ivan_lab_2/data_generator/generate_data.py
Normal file
29
alkin_ivan_lab_2/data_generator/generate_data.py
Normal file
@ -0,0 +1,29 @@
|
||||
import os
|
||||
import random
|
||||
|
||||
|
||||
def generate_random_files(directory, num_files, num_lines_per_file, min_value, max_value):
|
||||
os.makedirs(directory, exist_ok=True)
|
||||
|
||||
for i in range(num_files):
|
||||
file_path = os.path.join(directory, f"file_{i + 1}.txt")
|
||||
with open(file_path, 'w') as f:
|
||||
for _ in range(num_lines_per_file):
|
||||
random_number = random.randint(min_value, max_value)
|
||||
f.write(f"{random_number}\n")
|
||||
print(f"Generated file: {file_path}")
|
||||
|
||||
|
||||
def main():
|
||||
data_directory = '/var/data'
|
||||
num_files = 10
|
||||
num_lines_per_file = 12
|
||||
min_value = 1
|
||||
max_value = 100
|
||||
|
||||
generate_random_files(data_directory, num_files, num_lines_per_file, min_value, max_value)
|
||||
print(f"Generated {num_files} files in {data_directory}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
18
alkin_ivan_lab_2/docker-compose.yml
Normal file
18
alkin_ivan_lab_2/docker-compose.yml
Normal file
@ -0,0 +1,18 @@
|
||||
# docker-compose.yml
|
||||
|
||||
services:
|
||||
worker-1:
|
||||
build:
|
||||
context: ./worker-1
|
||||
volumes:
|
||||
- ./data:/var/data
|
||||
- ./result:/var/result
|
||||
depends_on:
|
||||
- worker-2
|
||||
|
||||
worker-2:
|
||||
build:
|
||||
context: ./worker-2
|
||||
volumes:
|
||||
- ./data:/var/data
|
||||
- ./result:/var/result
|
||||
14
alkin_ivan_lab_2/worker-1/Dockerfile
Normal file
14
alkin_ivan_lab_2/worker-1/Dockerfile
Normal file
@ -0,0 +1,14 @@
|
||||
# worker-1/Dockerfile
|
||||
# Stage 1: Build the application
|
||||
FROM python:3.10-slim as builder
|
||||
|
||||
WORKDIR /app
|
||||
COPY ./main.py .
|
||||
|
||||
# Stage 2: Set up the runtime environment
|
||||
FROM python:3.10-slim
|
||||
|
||||
WORKDIR /app
|
||||
COPY --from=builder /app/main.py .
|
||||
|
||||
CMD ["python", "main.py"]
|
||||
35
alkin_ivan_lab_2/worker-1/main.py
Normal file
35
alkin_ivan_lab_2/worker-1/main.py
Normal file
@ -0,0 +1,35 @@
|
||||
# worker-1/main.py
|
||||
import os
|
||||
|
||||
|
||||
def find_file_with_most_lines(directory):
|
||||
files = os.listdir(directory)
|
||||
max_lines = 0
|
||||
target_file = None
|
||||
for filename in files:
|
||||
filepath = os.path.join(directory, filename)
|
||||
if os.path.isfile(filepath):
|
||||
with open(filepath, 'r') as file:
|
||||
lines = file.readlines()
|
||||
if len(lines) > max_lines:
|
||||
max_lines = len(lines)
|
||||
target_file = filepath
|
||||
return target_file
|
||||
|
||||
|
||||
def main():
|
||||
source_directory = '/var/data'
|
||||
result_file = '/var/result/data.txt'
|
||||
|
||||
file_to_copy = find_file_with_most_lines(source_directory)
|
||||
|
||||
if file_to_copy:
|
||||
with open(file_to_copy, 'r') as source, open(result_file, 'w') as dest:
|
||||
dest.writelines(source.readlines())
|
||||
print(f"File with the most lines: {file_to_copy} copied to {result_file}")
|
||||
else:
|
||||
print("No files found in the source directory.")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
14
alkin_ivan_lab_2/worker-2/Dockerfile
Normal file
14
alkin_ivan_lab_2/worker-2/Dockerfile
Normal file
@ -0,0 +1,14 @@
|
||||
# worker-1/Dockerfile
|
||||
# Stage 1: Build the application
|
||||
FROM python:3.10-slim as builder
|
||||
|
||||
WORKDIR /app
|
||||
COPY ./main.py .
|
||||
|
||||
# Stage 2: Set up the runtime environment
|
||||
FROM python:3.10-slim
|
||||
|
||||
WORKDIR /app
|
||||
COPY --from=builder /app/main.py .
|
||||
|
||||
CMD ["python", "main.py"]
|
||||
23
alkin_ivan_lab_2/worker-2/main.py
Normal file
23
alkin_ivan_lab_2/worker-2/main.py
Normal file
@ -0,0 +1,23 @@
|
||||
# worker-2/main.py
|
||||
def find_min_number(filename):
|
||||
with open(filename, 'r') as file:
|
||||
numbers = [int(line.strip()) for line in file.readlines()]
|
||||
min_number = min(numbers)
|
||||
return min_number
|
||||
|
||||
|
||||
def main():
|
||||
input_file = '/var/data/data.txt'
|
||||
output_file = '/var/result/result.txt'
|
||||
|
||||
min_number = find_min_number(input_file)
|
||||
result = min_number ** 3 # Cube of the minimum number
|
||||
|
||||
with open(output_file, 'w') as file:
|
||||
file.write(str(result))
|
||||
|
||||
print(f"Minimum number's cube: {result} written to {output_file}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
42
alkin_ivan_lab_3/README.md
Normal file
42
alkin_ivan_lab_3/README.md
Normal file
@ -0,0 +1,42 @@
|
||||
# Лабораторная работа №3: REST API, шлюз и синхронный обмен данными между микросервисами
|
||||
|
||||
## Задание
|
||||
|
||||
### Цель
|
||||
Изучение принципов проектирования на основе паттерна шлюза, организации синхронного взаимодействия микросервисов и использования RESTful API.
|
||||
|
||||
### Основные задачи
|
||||
1. Разработка двух микросервисов с поддержкой CRUD-операций для связанных сущностей.
|
||||
2. Организация синхронного обмена данными между микросервисами.
|
||||
3. Настройка шлюза на базе Nginx, выступающего в роли прозрачного прокси-сервера.
|
||||
|
||||
### Микросервисы
|
||||
1. **hero_service** — микросервис для управления информацией о героях.
|
||||
2. **item_service** — микросервис для обработки данных о предметах, принадлежащих героям.
|
||||
|
||||
### Связь между микросервисами
|
||||
- Один герой (**hero**) может иметь множество связанных предметов (**items**) (соотношение 1:многие).
|
||||
|
||||
## Инструкция по запуску
|
||||
Для запуска проекта выполните команду:
|
||||
```bash
|
||||
docker-compose up
|
||||
```
|
||||
|
||||
## Описание работы
|
||||
|
||||
### Разработка микросервисов
|
||||
Микросервисы разработаны с использованием языка программирования Python.
|
||||
|
||||
### Синхронное взаимодействие
|
||||
`hero_service` обращается к `item_service` через HTTP-запросы для выполнения операций CRUD. Это позволяет получать актуальные данные о предметах, связанных с героями.
|
||||
|
||||
### Docker Compose
|
||||
Файл `docker-compose.yml` описывает многоконтейнерное приложение, включающее три сервиса: `hero_service`, `item_service` и `nginx`. Nginx выполняет маршрутизацию запросов между сервисами.
|
||||
|
||||
### Nginx
|
||||
Конфигурация Nginx задает параметры веб-сервера и обратного прокси, который принимает входящие запросы и направляет их к соответствующим микросервисам.
|
||||
|
||||
### Видеоматериал
|
||||
Подробнее ознакомиться с проектом можно в видео:
|
||||
https://vkvideo.ru/video150882239_456240342
|
||||
26
alkin_ivan_lab_3/docker-compose.yml
Normal file
26
alkin_ivan_lab_3/docker-compose.yml
Normal file
@ -0,0 +1,26 @@
|
||||
version: '3.8'
|
||||
|
||||
services:
|
||||
hero_service:
|
||||
build:
|
||||
context: ./hero_service
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- "5000:5000"
|
||||
|
||||
item_service:
|
||||
build:
|
||||
context: ./item_service
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- "5001:5001"
|
||||
|
||||
nginx:
|
||||
image: nginx:latest
|
||||
volumes:
|
||||
- ./nginx/nginx.conf:/etc/nginx/conf.d/default.conf
|
||||
ports:
|
||||
- "80:80"
|
||||
depends_on:
|
||||
- hero_service
|
||||
- item_service
|
||||
10
alkin_ivan_lab_3/hero_service/Dockerfile
Normal file
10
alkin_ivan_lab_3/hero_service/Dockerfile
Normal file
@ -0,0 +1,10 @@
|
||||
FROM python:3.11
|
||||
|
||||
WORKDIR /app
|
||||
|
||||
COPY requirements.txt .
|
||||
RUN pip install --no-cache-dir -r requirements.txt
|
||||
|
||||
COPY . .
|
||||
|
||||
CMD ["python", "main.py"]
|
||||
51
alkin_ivan_lab_3/hero_service/main.py
Normal file
51
alkin_ivan_lab_3/hero_service/main.py
Normal file
@ -0,0 +1,51 @@
|
||||
from flask import Flask, jsonify, request
|
||||
import uuid
|
||||
|
||||
app = Flask(__name__)
|
||||
|
||||
heroes = {}
|
||||
|
||||
@app.route('/heroes', methods=['GET'])
|
||||
def get_heroes():
|
||||
return jsonify(list(heroes.values()))
|
||||
|
||||
@app.route('/heroes/<uuid:hero_uuid>', methods=['GET'])
|
||||
def get_hero(hero_uuid):
|
||||
hero = heroes.get(str(hero_uuid))
|
||||
if hero:
|
||||
return jsonify(hero)
|
||||
return jsonify({'error': 'Not found'}), 404
|
||||
|
||||
@app.route('/heroes', methods=['POST'])
|
||||
def create_hero():
|
||||
data = request.get_json()
|
||||
hero_uuid = str(uuid.uuid4())
|
||||
hero = {
|
||||
'uuid': hero_uuid,
|
||||
'name': data['name'],
|
||||
'role': data['role'],
|
||||
'strength': data['strength']
|
||||
}
|
||||
heroes[hero_uuid] = hero
|
||||
return jsonify(hero), 201
|
||||
|
||||
@app.route('/heroes/<uuid:hero_uuid>', methods=['PUT'])
|
||||
def update_hero(hero_uuid):
|
||||
hero = heroes.get(str(hero_uuid))
|
||||
if not hero:
|
||||
return jsonify({'error': 'Not found'}), 404
|
||||
data = request.get_json()
|
||||
hero['name'] = data['name']
|
||||
hero['role'] = data['role']
|
||||
hero['strength'] = data['strength']
|
||||
return jsonify(hero)
|
||||
|
||||
@app.route('/heroes/<uuid:hero_uuid>', methods=['DELETE'])
|
||||
def delete_hero(hero_uuid):
|
||||
if str(hero_uuid) in heroes:
|
||||
del heroes[str(hero_uuid)]
|
||||
return '', 204
|
||||
return jsonify({'error': 'Not found'}), 404
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
1
alkin_ivan_lab_3/hero_service/requirements.txt
Normal file
1
alkin_ivan_lab_3/hero_service/requirements.txt
Normal file
@ -0,0 +1 @@
|
||||
Flask
|
||||
10
alkin_ivan_lab_3/item_service/Dockerfile
Normal file
10
alkin_ivan_lab_3/item_service/Dockerfile
Normal file
@ -0,0 +1,10 @@
|
||||
FROM python:3.11
|
||||
|
||||
WORKDIR /app
|
||||
|
||||
COPY requirements.txt .
|
||||
RUN pip install --no-cache-dir -r requirements.txt
|
||||
|
||||
COPY . .
|
||||
|
||||
CMD ["python", "main.py"]
|
||||
51
alkin_ivan_lab_3/item_service/main.py
Normal file
51
alkin_ivan_lab_3/item_service/main.py
Normal file
@ -0,0 +1,51 @@
|
||||
from flask import Flask, jsonify, request
|
||||
import uuid
|
||||
|
||||
app = Flask(__name__)
|
||||
|
||||
items = {}
|
||||
|
||||
@app.route('/items', methods=['GET'])
|
||||
def get_items():
|
||||
return jsonify(list(items.values()))
|
||||
|
||||
@app.route('/items/<uuid:item_uuid>', methods=['GET'])
|
||||
def get_item(item_uuid):
|
||||
item = items.get(str(item_uuid))
|
||||
if item:
|
||||
return jsonify(item)
|
||||
return jsonify({'error': 'Not found'}), 404
|
||||
|
||||
@app.route('/items', methods=['POST'])
|
||||
def create_item():
|
||||
data = request.json
|
||||
item_uuid = str(uuid.uuid4())
|
||||
item = {
|
||||
'uuid': item_uuid,
|
||||
'name': data['name'],
|
||||
'type': data['type'],
|
||||
'hero_uuid': data['hero_uuid']
|
||||
}
|
||||
items[item_uuid] = item
|
||||
return jsonify(item), 201
|
||||
|
||||
@app.route('/items/<uuid:item_uuid>', methods=['PUT'])
|
||||
def update_item(item_uuid):
|
||||
item = items.get(str(item_uuid))
|
||||
if not item:
|
||||
return jsonify({'error': 'Not found'}), 404
|
||||
data = request.json
|
||||
item['name'] = data['name']
|
||||
item['type'] = data['type']
|
||||
item['hero_uuid'] = data['hero_uuid']
|
||||
return jsonify(item)
|
||||
|
||||
@app.route('/items/<uuid:item_uuid>', methods=['DELETE'])
|
||||
def delete_item(item_uuid):
|
||||
if str(item_uuid) in items:
|
||||
del items[str(item_uuid)]
|
||||
return '', 204
|
||||
return jsonify({'error': 'Not found'}), 404
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(host='0.0.0.0', port=5001)
|
||||
1
alkin_ivan_lab_3/item_service/requirements.txt
Normal file
1
alkin_ivan_lab_3/item_service/requirements.txt
Normal file
@ -0,0 +1 @@
|
||||
Flask
|
||||
11
alkin_ivan_lab_3/nginx/nginx.conf
Normal file
11
alkin_ivan_lab_3/nginx/nginx.conf
Normal file
@ -0,0 +1,11 @@
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
location /heroes {
|
||||
proxy_pass http://hero_service:5000;
|
||||
}
|
||||
|
||||
location /items {
|
||||
proxy_pass http://item_service:5001;
|
||||
}
|
||||
}
|
||||
36
artamonova_tatyana_lab_5/README.md
Normal file
36
artamonova_tatyana_lab_5/README.md
Normal file
@ -0,0 +1,36 @@
|
||||
|
||||
# Лабораторная работа №5 ПИбд-42 Артамоновой Татьяны
|
||||
|
||||
## Запуск лабораторной работы
|
||||
|
||||
1. Установить библиотеки Python и NumPy
|
||||
3. Запустить скрипт matrix.py с помощью команды: *python matrix.py*
|
||||
|
||||
## Используемые технологии
|
||||
|
||||
- Язык программирования: Python
|
||||
- Библиотеки:
|
||||
* numpy: Для работы с массивами и матрицами
|
||||
* multiprocessing: Для параллельного выполнения кода
|
||||
* time: Для измерения времени выполнения
|
||||
|
||||
## Задание на лабораторную работу
|
||||
|
||||
**Кратко:** реализовать умножение двух больших квадратных матриц.
|
||||
|
||||
**Подробно:** в лабораторной работе требуется сделать два алгоритма: обычный и параллельный (задание со * -
|
||||
реализовать это в рамках одного алгоритма). В параллельном алгоритме предусмотреть ручное задание количества
|
||||
потоков (число потоков = 1 как раз и реализует задание со *), каждый из которых будет выполнять умножение
|
||||
элементов матрицы в рамках своей зоны ответственности.
|
||||
|
||||
## Результаты
|
||||
|
||||

|
||||
|
||||
## Вывод
|
||||
|
||||
Результаты показывают, что для маленьких матриц последовательное умножение быстрее.
|
||||
Оптимальное количество потоков близко к количеству ядер процессора. Увеличение количества потоков сверх
|
||||
оптимального значения не всегда ускоряет вычисления. Параллелизм эффективнее для больших матриц.
|
||||
|
||||
### [Видео](https://vk.com/video212084908_456239362)
|
||||
BIN
artamonova_tatyana_lab_5/images/results.png
Normal file
BIN
artamonova_tatyana_lab_5/images/results.png
Normal file
{kind=link}
Binary file not shown.
|
After 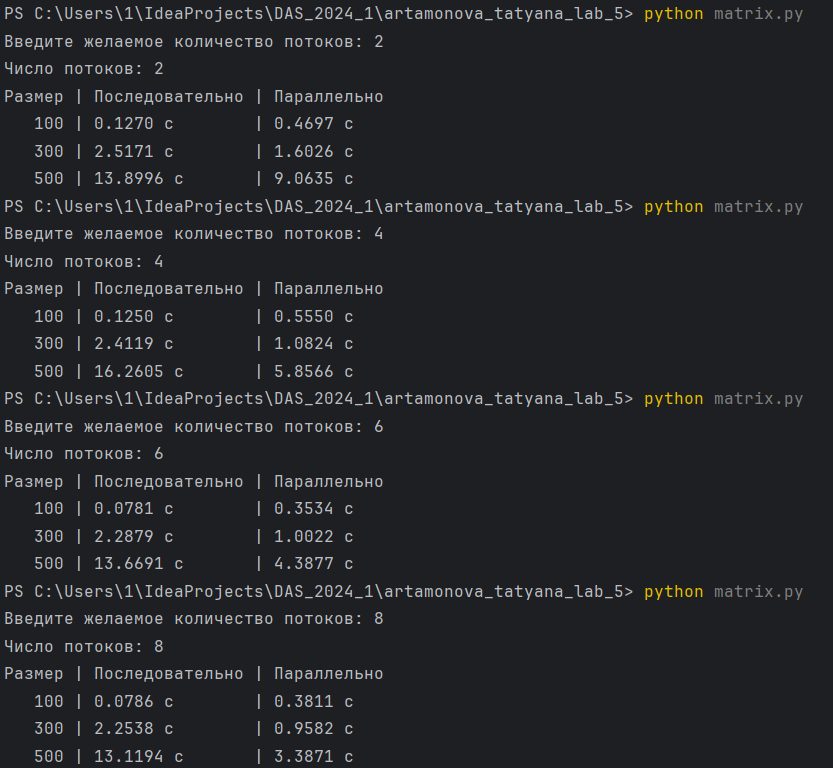
(image error) Size: 107 KiB |
93
artamonova_tatyana_lab_5/matrix.py
Normal file
93
artamonova_tatyana_lab_5/matrix.py
Normal file
@ -0,0 +1,93 @@
|
||||
import time
|
||||
import multiprocessing
|
||||
import numpy as np
|
||||
|
||||
def multiply_matrices_sequential(matrix1, matrix2):
|
||||
rows1 = len(matrix1)
|
||||
cols1 = len(matrix1[0])
|
||||
rows2 = len(matrix2)
|
||||
cols2 = len(matrix2[0])
|
||||
|
||||
if cols1 != rows2:
|
||||
raise ValueError("Число столбцов первой матрицы должно быть равно числу строк второй матрицы.")
|
||||
|
||||
result = [[0 for _ in range(cols2)] for _ in range(rows1)]
|
||||
for i in range(rows1):
|
||||
for j in range(cols2):
|
||||
for k in range(cols1):
|
||||
result[i][j] += matrix1[i][k] * matrix2[k][j]
|
||||
return result
|
||||
|
||||
def multiply_matrices_parallel(matrix1, matrix2, num_processes):
|
||||
rows1 = len(matrix1)
|
||||
cols1 = len(matrix1[0])
|
||||
rows2 = len(matrix2)
|
||||
cols2 = len(matrix2[0])
|
||||
|
||||
if cols1 != rows2:
|
||||
raise ValueError("Число столбцов первой матрицы должно быть равно числу строк второй матрицы.")
|
||||
|
||||
chunk_size = rows1 // num_processes
|
||||
processes = []
|
||||
results = []
|
||||
|
||||
with multiprocessing.Pool(processes=num_processes) as pool:
|
||||
for i in range(num_processes):
|
||||
start_row = i * chunk_size
|
||||
end_row = (i + 1) * chunk_size if i < num_processes - 1 else rows1
|
||||
p = pool.apply_async(multiply_matrix_chunk, (matrix1, matrix2, start_row, end_row))
|
||||
processes.append(p)
|
||||
|
||||
for p in processes:
|
||||
results.append(p.get())
|
||||
|
||||
result = [[0 for _ in range(cols2)] for _ in range(rows1)]
|
||||
row_index = 0
|
||||
for sub_result in results:
|
||||
for row in sub_result:
|
||||
result[row_index] = row
|
||||
row_index += 1
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def multiply_matrix_chunk(matrix1, matrix2, start_row, end_row):
|
||||
rows2 = len(matrix2)
|
||||
cols2 = len(matrix2[0])
|
||||
cols1 = len(matrix1[0])
|
||||
result = [[0 for _ in range(cols2)] for _ in range(end_row - start_row)]
|
||||
for i in range(end_row - start_row):
|
||||
for j in range(cols2):
|
||||
for k in range(cols1):
|
||||
result[i][j] += matrix1[i + start_row][k] * matrix2[k][j]
|
||||
return result
|
||||
|
||||
|
||||
def benchmark(matrix_size, num_processes):
|
||||
matrix1 = np.random.rand(matrix_size, matrix_size).tolist()
|
||||
matrix2 = np.random.rand(matrix_size, matrix_size).tolist()
|
||||
|
||||
try:
|
||||
start_time = time.time()
|
||||
sequential_result = multiply_matrices_sequential(matrix1, matrix2)
|
||||
end_time = time.time()
|
||||
sequential_time = end_time - start_time
|
||||
|
||||
start_time = time.time()
|
||||
parallel_result = multiply_matrices_parallel(matrix1, matrix2, num_processes)
|
||||
end_time = time.time()
|
||||
parallel_time = end_time - start_time
|
||||
return sequential_time, parallel_time
|
||||
except ValueError as e:
|
||||
print(f"Ошибка бенчмарка с размером матрицы {matrix_size} и {num_processes} процессов: {e}")
|
||||
return float('inf'), float('inf')
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
sizes = [100, 300, 500]
|
||||
num_processes = int(input("Введите количество потоков: "))
|
||||
print("Размер | Последовательно | Параллельно")
|
||||
|
||||
for size in sizes:
|
||||
sequential_time, parallel_time = benchmark(size, num_processes)
|
||||
print(f"{size:6} | {sequential_time:.4f} с \t | {parallel_time:.4f} с")
|
||||
50
artamonova_tatyana_lab_6/README.md
Normal file
50
artamonova_tatyana_lab_6/README.md
Normal file
@ -0,0 +1,50 @@
|
||||
# Лабораторная работа №6 ПИбд-42 Артамоновой Татьяны
|
||||
|
||||
## Цель работы
|
||||
|
||||
Разработать и сравнить эффективность последовательного и
|
||||
параллельного алгоритмов вычисления определителя квадратной матрицы.
|
||||
|
||||
## Методика
|
||||
|
||||
Для вычисления определителя использовался рекурсивный алгоритм, основанный
|
||||
на разложении по первой строке. Параллельная версия алгоритма реализована
|
||||
с помощью библиотеки multiprocessing, разделяя вычисление алгебраических
|
||||
дополнений между несколькими процессами. Время выполнения каждого алгоритма
|
||||
замерялось для матриц различных размеров (100x100, 300x300, 500x500).
|
||||
Эксперименты проводились с различным количеством потоков (1, 2, 4).
|
||||
|
||||
## Результаты
|
||||
|
||||
Результаты бенчмарка представлены на изображении:
|
||||
[Фото](images/result.png)
|
||||
|
||||
## Анализ результатов
|
||||
|
||||
Результаты демонстрируют неоднозначную эффективность параллельного подхода.
|
||||
Для матрицы 100x100 параллельные версии работают медленнее, чем последовательная.
|
||||
Это объясняется значительными накладными расходами на создание и синхронизацию
|
||||
процессов, которые преобладают над выигрышем от распараллеливания для небольших
|
||||
задач.
|
||||
|
||||
Для матриц 300x300 и 500x500 наблюдается неожиданное поведение: параллельные
|
||||
версии работают значительно медленнее, чем последовательная. Это указывает на
|
||||
наличие проблем в реализации параллельного алгоритма. Скорее всего, проблема
|
||||
связана с неэффективным использованием multiprocessing и значительными накладными
|
||||
расходами на межпроцессное взаимодействие, которые перевешивают выигрыш от
|
||||
распараллеливания. Рекурсивный алгоритм вычисления детерминанта плохо
|
||||
масштабируется при распараллеливании, так как большая часть времени тратится
|
||||
на рекурсивные вызовы, которые не могут быть эффективно распределены между
|
||||
процессами.
|
||||
|
||||
## Выводы
|
||||
|
||||
Полученные результаты показывают, что для выбранного рекурсивного
|
||||
алгоритма и способа распараллеливания, параллельная реализация не эффективна.
|
||||
Для эффективного использования параллельных вычислений необходимы более
|
||||
подходящие алгоритмы вычисления определителя, например, алгоритмы, основанные
|
||||
на LU-разложении, а также более тщательная оптимизация распараллеливания с
|
||||
учетом накладных расходов. В данном случае, последовательный алгоритм оказался
|
||||
быстрее для всех размеров матриц, кроме 100х100, где разница незначительна.
|
||||
|
||||
### [Видео](https://vk.com/video212084908_456239363)
|
||||
BIN
artamonova_tatyana_lab_6/images/result.png
Normal file
BIN
artamonova_tatyana_lab_6/images/result.png
Normal file
{kind=link}
Binary file not shown.
|
After 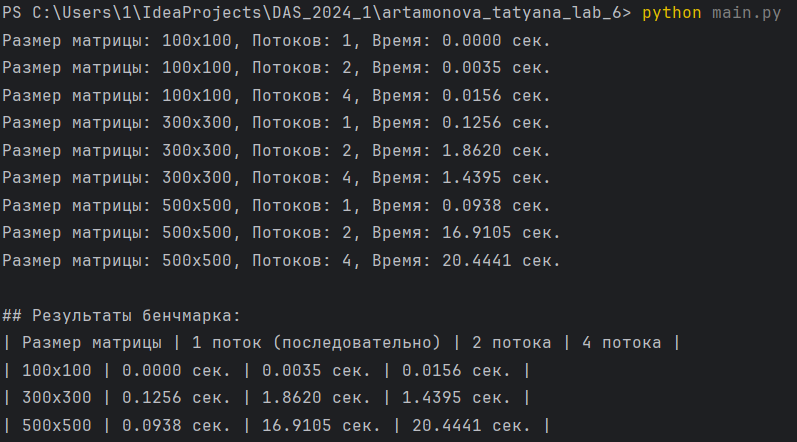
(image error) Size: 79 KiB |
62
artamonova_tatyana_lab_6/main.py
Normal file
62
artamonova_tatyana_lab_6/main.py
Normal file
@ -0,0 +1,62 @@
|
||||
import numpy as np
|
||||
import time
|
||||
import threading
|
||||
|
||||
def determinant_sequential(matrix):
|
||||
return np.linalg.det(matrix)
|
||||
|
||||
def determinant_parallel(matrix, num_threads):
|
||||
n = len(matrix)
|
||||
if n == 1:
|
||||
return matrix[0][0]
|
||||
if n == 2:
|
||||
return matrix[0][0] * matrix[1][1] - matrix[0][1] * matrix[1][0]
|
||||
|
||||
threads = []
|
||||
results = [0] * num_threads
|
||||
chunk_size = n // num_threads
|
||||
|
||||
def worker(thread_id):
|
||||
start_index = thread_id * chunk_size
|
||||
end_index = min((thread_id + 1) * chunk_size, n)
|
||||
det_sum = 0
|
||||
for i in range(start_index, end_index):
|
||||
submatrix = np.delete(matrix, i, 0)
|
||||
submatrix = np.delete(submatrix, 0, 1)
|
||||
det_sum += (-1)**i * matrix[i][0] * determinant_sequential(submatrix)
|
||||
results[thread_id] = det_sum
|
||||
|
||||
for i in range(num_threads):
|
||||
thread = threading.Thread(target=worker, args=(i,))
|
||||
threads.append(thread)
|
||||
thread.start()
|
||||
|
||||
for thread in threads:
|
||||
thread.join()
|
||||
|
||||
return sum(results)
|
||||
|
||||
sizes = [100, 300, 500]
|
||||
num_threads = [1, 2, 4]
|
||||
|
||||
results = {}
|
||||
|
||||
for size in sizes:
|
||||
matrix = np.random.rand(size, size)
|
||||
results[size] = {}
|
||||
for n_threads in num_threads:
|
||||
start_time = time.time()
|
||||
if n_threads == 1:
|
||||
det = determinant_sequential(matrix)
|
||||
else:
|
||||
det = determinant_parallel(matrix, n_threads)
|
||||
end_time = time.time()
|
||||
results[size][n_threads] = end_time - start_time
|
||||
print(f"Размер матрицы: {size}x{size}, Потоков: {n_threads}, Время: {end_time - start_time:.4f} сек.")
|
||||
|
||||
|
||||
print("\n## Результаты бенчмарка:")
|
||||
print("| Размер матрицы | 1 поток (последовательно) | 2 потока | 4 потока |")
|
||||
for size, timings in results.items():
|
||||
print(f"| {size}x{size} | {timings [1] :.4f} сек. | {timings.get(2, 'N/A'):.4f} сек. | {timings.get(4, 'N/A'):.4f} сек. |")
|
||||
|
||||
66
artamonova_tatyana_lab_7/README.md
Normal file
66
artamonova_tatyana_lab_7/README.md
Normal file
@ -0,0 +1,66 @@
|
||||
## Лабораторная работа №7
|
||||
|
||||
### Эссе на тему "Балансировка нагрузки в распределённых системах при помощи открытых технологий на примерах"
|
||||
|
||||
При масштабировании приложения появляется необходимость в
|
||||
добавлении новых серверов. В таком случае нужно пользоваться
|
||||
балансировщиком нагрузок для распределения запросов.
|
||||
|
||||
А что делать, если серверов больше сотни или тысячи?
|
||||
|
||||
Балансировка нагрузки позволяет обеспечить равномерное распределение
|
||||
нагрузки между несколькими серверами. Без неё один сервер может
|
||||
перегрузиться, а другой простаивать. Это приводит к неэффективной
|
||||
работе системы.
|
||||
|
||||
Для решения этой проблемы используют различные алгоритмы.
|
||||
|
||||
1. **"Round-robin"** - балансировка нагрузок циклическим перебором.
|
||||
Алгоритм можно описать так: балансировщик нагрузок отправляет
|
||||
запрос каждому серверу по очереди. Это решает проблему "отбрасывания"
|
||||
входящих запросов, когда предыдущий запрос еще не был обработан.
|
||||
Такой алгоритм подойдет для серверов с одинаковой мощностью и
|
||||
одинаково затратных запросов.
|
||||
|
||||
2. **Очереди запросов** - балансировка нагрузок с помощью создания очередей
|
||||
запросов.
|
||||
Редко встречаются ситуации, когда все запросы одинаково обрабатываются.
|
||||
Очереди запросов позволяют справиться с этой проблемой, но со своими
|
||||
недостатками.
|
||||
"Отбрасываться" будет меньше запросов, но некоторые из них будут иметь
|
||||
задержку при обработке (так как будут ожидать в очереди)
|
||||
|
||||
3. **"Weighted round-robin"** - взвешенный цикличный перебор.
|
||||
Алгоритм заключается в назначении веса каждому серверу. Вес определяет,
|
||||
сколько запросов сможет обработать сервер. Это нужно, для подстраивания
|
||||
к мощности каждого сервера.
|
||||
|
||||
В качестве открытых технологий для балансировки нагрузки используются **HAProxy** и **Nginx**.
|
||||
Они выступают в роли обратного прокси-сервера: принимают запросы от клиентов
|
||||
и перенаправляют их на один из доступных серверов. Они предлагают
|
||||
гибкую настройку алгоритмов балансировки и отслеживания состояния серверов.
|
||||
Кроме того, существуют решения на основе Kubernetes или других
|
||||
оркестраторов контейнеров, которые управляют распределением нагрузки
|
||||
по микросервисам.
|
||||
|
||||
Балансировка нагрузки на базах данных — специфическая задача, решаемая
|
||||
с помощью механизмов репликации и кластеризации.
|
||||
|
||||
**Репликация** создает копии данных на нескольких серверах. Это обеспечивает
|
||||
отказоустойчивость и повышение производительности за счет распределения
|
||||
нагрузки чтения.
|
||||
|
||||
**Кластеризация** объединяет несколько баз данных в единую систему. Это позволяет
|
||||
распределять нагрузку записи и чтения между несколькими базами.
|
||||
Выбор оптимального подхода зависит от специфики приложения
|
||||
и требований к доступности и производительности.
|
||||
|
||||
**Реверс-прокси** играет ключевую роль в балансировке нагрузки.
|
||||
Он принимает все входящие запросы, контролирует доступность серверов
|
||||
на бэке и перенаправляет запросы на доступные и наименее загруженные сервера.
|
||||
Кроме распределения нагрузки, реверс-прокси выполняет другие важные функции:
|
||||
кэширование, SSL-терминирование и защита от атак. Благодаря своей гибкости
|
||||
и функциональности, реверс-прокси является важным компонентом
|
||||
высокопроизводительных и отказоустойчивых распределенных систем.
|
||||
|
||||
|
||||
37
artamonova_tatyana_lab_8/README.md
Normal file
37
artamonova_tatyana_lab_8/README.md
Normal file
@ -0,0 +1,37 @@
|
||||
## Лабораторная работа №8 ПИбд-42 Артамоновой Татьяны
|
||||
|
||||
### Эссе на тему "Устройство распределенных систем"
|
||||
|
||||
Сложные системы строятся по принципу распределенных приложений,
|
||||
где каждый сервис отвечает за свою узкую специализацию. Это повышает масштабируемость,
|
||||
надежность и удобство разработки. Разделение на отдельные сервисы позволяет независимо
|
||||
масштабировать отдельные компоненты системы. Это упростит их обновление, замену и
|
||||
повышает отказоустойчивость: выход из строя одного сервиса не обязательно
|
||||
парализует всю систему.
|
||||
|
||||
Системы оркестрации, такие, как Kubernetes, были созданы для упрощения управления и
|
||||
масштабирования распределенных систем. Они автоматизируют развертывание, масштабирование и
|
||||
мониторинг приложений, работающих в контейнерах. С одной стороны, оркестраторы значительно
|
||||
упрощают разработку, предоставляя готовые инструменты для управления инфраструктурой.
|
||||
С другой стороны, они добавляют сложность – требуется освоение новых инструментов и концепций,
|
||||
а сама система оркестрации может стать узким местом.
|
||||
|
||||
Очереди сообщений (RabbitMQ, Kafka) используются для асинхронной передачи данных
|
||||
между сервисами. Сообщения могут представлять собой любые данные: запросы на выполнение
|
||||
действия, уведомления о событиях, результаты обработки. Асинхронная обработка позволяет
|
||||
повысить производительность и отказоустойчивость, так как сервисы не зависят от мгновенного
|
||||
ответа друг друга. Если один сервис временно недоступен, сообщения накапливаются в очереди и
|
||||
обрабатываются позже.
|
||||
|
||||
Преимущества распределенных приложений очевидны: масштабируемость, отказоустойчивость,
|
||||
гибкость разработки. Но есть и недостатки. Распределенная система гораздо сложнее в разработке,
|
||||
тестировании и отладке, чем монолитная. Возникают проблемы с согласованностью данных,
|
||||
распределёнными транзакциями и мониторингом.
|
||||
|
||||
Внедрение параллельных вычислений в сложную распределенную систему имеет смысл,
|
||||
если есть задачи, которые можно разбить на независимые подзадачи, решаемые параллельно.
|
||||
Например, обработка больших объемов данных или выполнение ресурсоемких
|
||||
вычислений. Однако, если система ограничена I/O операциями,
|
||||
параллельные вычисления могут не дать значительного выигрыша
|
||||
в производительности из-за "узких мест" в других частях системы. В таких случаях,
|
||||
оптимизация I/O операций может быть эффективнее, чем добавление параллелизма.
|
||||
56
bazunov_andrew_lab_7/README.md
Normal file
56
bazunov_andrew_lab_7/README.md
Normal file
@ -0,0 +1,56 @@
|
||||
## Эссе на тему "Балансировка нагрузки в распределённых системах при помощи открытых технологий на примерах"
|
||||
|
||||
# Балансировка нагрузки: алгоритмы, методы и технологии
|
||||
|
||||
Балансировка нагрузки — это процесс распределения входящего трафика или вычислительных задач между несколькими серверами, чтобы обеспечить равномерное использование ресурсов, минимизировать задержки и повысить отказоустойчивость системы.
|
||||
|
||||
---
|
||||
|
||||
## Алгоритмы и методы
|
||||
Для реализации балансировки нагрузки используются различные алгоритмы:
|
||||
|
||||
- **Round Robin** — циклическое распределение запросов между серверами.
|
||||
- **Least Connections** — запрос направляется на сервер с наименьшим количеством активных соединений.
|
||||
- **Weighted Round Robin** — циклическое распределение с учётом веса серверов.
|
||||
- **Dynamic Load Balancing** — алгоритмы, учитывающие текущую нагрузку и производительность серверов.
|
||||
|
||||
---
|
||||
|
||||
## Открытые технологии
|
||||
Существует множество технологий, поддерживающих балансировку нагрузки:
|
||||
|
||||
- **Nginx** и **HAProxy** — мощные и популярные инструменты для HTTP и TCP трафика.
|
||||
- **Kubernetes Ingress Controller** — автоматическая балансировка нагрузки в контейнерных средах.
|
||||
- **AWS Elastic Load Balancer** и **Google Cloud Load Balancer** — решения для облачных инфраструктур.
|
||||
|
||||
---
|
||||
|
||||
## Балансировка нагрузки на базах данных
|
||||
Балансировка базы данных требует специальных подходов:
|
||||
|
||||
- **Репликация**: создание копий базы данных для чтения, чтобы распределить запросы.
|
||||
- **Шардинг**: разделение данных на сегменты, хранящиеся на разных серверах.
|
||||
- Использование инструментов:
|
||||
- **ProxySQL** для MySQL
|
||||
- **pgpool-II** для PostgreSQL
|
||||
|
||||
---
|
||||
|
||||
## Реверс-прокси как элемент балансировки
|
||||
Реверс-прокси выполняет роль промежуточного сервера:
|
||||
|
||||
- Принимает запросы от клиентов и перенаправляет их на бэкэнд-сервера.
|
||||
- Обеспечивает:
|
||||
- Распределение нагрузки
|
||||
- Кеширование
|
||||
- Шифрование (SSL/TLS)
|
||||
- Мониторинг и анализ трафика
|
||||
|
||||
Популярные решения:
|
||||
- **Nginx**
|
||||
- **Traefik**
|
||||
|
||||
---
|
||||
|
||||
## Заключение
|
||||
Балансировка нагрузки — это не только необходимая мера для обеспечения стабильности высоконагруженных систем, но и мощный инструмент для их масштабирования и оптимизации. Выбор алгоритмов и технологий зависит от особенностей проекта и его требований.
|
||||
66
bazunov_andrew_lab_8/README.md
Normal file
66
bazunov_andrew_lab_8/README.md
Normal file
@ -0,0 +1,66 @@
|
||||
# Как Вы поняли, что называется распределенной системой и как она устроена?
|
||||
|
||||
# Распределенные системы: принципы, инструменты и подходы
|
||||
|
||||
Современные сложные системы, такие как социальные сети и крупные веб-приложения, часто строятся как распределенные. Это позволяет обеспечить их масштабируемость, отказоустойчивость и эффективность. В этом README рассматриваются основные аспекты распределённых систем.
|
||||
|
||||
---
|
||||
|
||||
## Зачем системы пишутся в распределенном стиле?
|
||||
В распределённых системах каждое приложение (или сервис) выполняет ограниченный спектр задач. Это позволяет:
|
||||
- **Разделить ответственность**: каждый сервис фокусируется на своей задаче, что упрощает разработку и сопровождение.
|
||||
- **Обеспечить масштабируемость**: можно увеличивать мощность отдельных сервисов без необходимости модификации всей системы.
|
||||
- **Повысить отказоустойчивость**: сбой одного сервиса не приводит к остановке всей системы.
|
||||
- Пример: в социальной сети ВКонтакте отдельные сервисы отвечают за отправку сообщений, хранение медиафайлов, обработку запросов API и рекламу.
|
||||
|
||||
---
|
||||
|
||||
## Для чего нужны системы оркестрации?
|
||||
Системы оркестрации, такие как **Kubernetes** или **Docker Swarm**, были созданы для управления контейнеризированными приложениями. Они:
|
||||
- **Упрощают разработку**: обеспечивают автоматическое масштабирование, балансировку нагрузки и перезапуск сервисов.
|
||||
- **Упрощают сопровождение**: помогают управлять зависимостями, обеспечивать резервное копирование и отслеживать состояние системы.
|
||||
- **Усложняют начальную настройку**: требуют знания инфраструктуры и инструментов, но окупаются на стадии эксплуатации.
|
||||
Пример: в крупной системе оркестрация позволяет автоматически перераспределять ресурсы между сервисами в зависимости от их нагрузки.
|
||||
|
||||
---
|
||||
|
||||
## Зачем нужны очереди обработки сообщений?
|
||||
Очереди сообщений (например, **RabbitMQ**, **Kafka**) используются для обмена данными между сервисами. Под сообщениями могут подразумеваться:
|
||||
- Запросы на выполнение задач.
|
||||
- Уведомления об изменении состояния.
|
||||
- Данные для обработки (например, лог-файлы или транзакции).
|
||||
|
||||
Очереди:
|
||||
- **Развязывают взаимодействие сервисов**: отправитель и получатель могут работать независимо.
|
||||
- **Обеспечивают устойчивость**: сохраняют сообщения до их обработки.
|
||||
|
||||
---
|
||||
|
||||
## Преимущества и недостатки распределённых приложений
|
||||
|
||||
### Преимущества:
|
||||
- Масштабируемость.
|
||||
- Устойчивость к сбоям.
|
||||
- Локализация изменений (меньше шансов нарушить работу всей системы).
|
||||
|
||||
### Недостатки:
|
||||
- Увеличенная сложность разработки.
|
||||
- Зависимость от сетевой инфраструктуры (задержки, потеря данных).
|
||||
- Требуются дополнительные инструменты для мониторинга и управления.
|
||||
|
||||
---
|
||||
|
||||
## Параллельные вычисления в распределенных системах
|
||||
|
||||
### Когда это необходимо:
|
||||
- **Обработка больших данных**: анализ логов, машинное обучение, трансляции видео.
|
||||
- **Высоконагруженные системы**: расчёт рекомендаций, обновление новостных лент в реальном времени.
|
||||
|
||||
### Когда это избыточно:
|
||||
- Малые системы с низкой нагрузкой.
|
||||
- Простые веб-приложения, где вычисления не требуют значительных ресурсов.
|
||||
|
||||
---
|
||||
|
||||
## Заключение
|
||||
Распределенные системы и связанные с ними инструменты играют важную роль в построении современных приложений. Однако их применение оправдано только там, где есть высокая нагрузка или необходимость в масштабировании. Успех разработки таких систем зависит от правильного выбора архитектуры, инструментов и методов разработки.
|
||||
2
bondarenko_max_lab_2/.gitignore
vendored
Normal file
2
bondarenko_max_lab_2/.gitignore
vendored
Normal file
@ -0,0 +1,2 @@
|
||||
node_modules/
|
||||
*.log
|
||||
55
bondarenko_max_lab_2/README.md
Normal file
55
bondarenko_max_lab_2/README.md
Normal file
@ -0,0 +1,55 @@
|
||||
# Лабораторная работа 2 - Разработка простейшего распределённого приложения
|
||||
### ПИбд-42 || Бондаренко Максим
|
||||
|
||||
# Описание работы
|
||||
|
||||
> Задача:
|
||||
В данной лабораторной работе изучить способы создания и развертывания простого распределённого приложения.
|
||||
|
||||
### Первая программа лабораторной работы.
|
||||
```
|
||||
Вариант - 2: Формирует файл /var/result/data.txt из первых строк всех файлов каталога /var/data.
|
||||
Для реализации программы я буду использовать JavaScript с Node.js
|
||||
```
|
||||
|
||||
### Вторая программа лабораторной работы.
|
||||
```
|
||||
Вариант - 2: Ищет наименьшее число из файла /var/data/data.txt и сохраняет его третью степень в /var/result/result.txt.
|
||||
Для реализации программы я буду использовать JavaScript с Node.js
|
||||
```
|
||||
|
||||
> Инструкция по запуску
|
||||
1. Запуск Docker - Desktop
|
||||
2. Открыть консоль в папке с docker-compose.yml
|
||||
3. Ввести команду:
|
||||
```
|
||||
docker-compose up --build
|
||||
```
|
||||
|
||||
> Docker-compose.yml
|
||||
```
|
||||
version: '3'
|
||||
services:
|
||||
app1:
|
||||
build:
|
||||
context: ./app-1
|
||||
volumes:
|
||||
- ./data:/var/data # Монтируем локальную папку data в /var/data
|
||||
- ./result:/var/result # Монтируем локальную папку result в /var/result
|
||||
container_name: app1
|
||||
|
||||
app2:
|
||||
build:
|
||||
context: ./app-2
|
||||
depends_on:
|
||||
- app1
|
||||
volumes:
|
||||
- ./result:/var/result # Монтируем ту же папку result
|
||||
container_name: app2
|
||||
```
|
||||
#### В результате в папке result создаётся два текстовых документа:
|
||||
1. data - результат работы первого проекта
|
||||
2. result - результат работы второго проекта
|
||||
|
||||
> Видео демонстрация работы
|
||||
https://cloud.mail.ru/public/FyyE/LTkRXBQXN
|
||||
14
bondarenko_max_lab_2/app-1/Dockerfile
Normal file
14
bondarenko_max_lab_2/app-1/Dockerfile
Normal file
@ -0,0 +1,14 @@
|
||||
# Образ с Node.js версии 18
|
||||
FROM node:18
|
||||
|
||||
# Создание директории
|
||||
WORKDIR /app
|
||||
|
||||
# Добавление кода в контейнер из index.js
|
||||
COPY index.js .
|
||||
|
||||
# Установка рабочей папки для вводных данных и результата
|
||||
RUN mkdir -p /var/data /var/result
|
||||
|
||||
# Запуск index.js с помощью среды выполнения Node.js
|
||||
CMD ["node", "index.js"]
|
||||
33
bondarenko_max_lab_2/app-1/index.js
Normal file
33
bondarenko_max_lab_2/app-1/index.js
Normal file
@ -0,0 +1,33 @@
|
||||
// Первая программа лабораторной работы.
|
||||
// Вариант - 2: Формирует файл /var/result/data.txt из первых строк всех файлов каталога /var/data.
|
||||
// Для реализации программы я буду использовать JavaScript с Node.js
|
||||
|
||||
// Импорт модулей
|
||||
const fs = require('fs');
|
||||
const path = require('path');
|
||||
|
||||
// Добавляем пути к папкам
|
||||
const dataDir = '/var/data';
|
||||
const resultFile = '/var/result/data.txt';
|
||||
|
||||
// Функция для извлечения первых строк всех файлов в data и записи резултата в result
|
||||
const gatherFirstLines = () => {
|
||||
// Обёртываю в try/catch
|
||||
try {
|
||||
const files = fs.readdirSync(dataDir); // Считывание название файлов из data
|
||||
// Проходимся по файлам
|
||||
// Добовляем первые строчки
|
||||
const firstLines = files.map((file) => {
|
||||
const filePath = path.join(dataDir, file);
|
||||
const content = fs.readFileSync(filePath, 'utf-8');
|
||||
return content.split('\n')[0];
|
||||
});
|
||||
|
||||
fs.writeFileSync(resultFile, firstLines.join('\n')); // Записываем первые строки в `data.txt`
|
||||
console.log('First lines have been successfully written to', resultFile); // Логирую в терминал результат
|
||||
} catch (error) {
|
||||
console.error('Error processing files:', error); // Перехватываю ошибку
|
||||
}
|
||||
};
|
||||
|
||||
gatherFirstLines(); // Вызываю функцию
|
||||
14
bondarenko_max_lab_2/app-2/Dockerfile
Normal file
14
bondarenko_max_lab_2/app-2/Dockerfile
Normal file
@ -0,0 +1,14 @@
|
||||
# Образ с Node.js версии 18
|
||||
FROM node:18
|
||||
|
||||
# Создание директории
|
||||
WORKDIR /app
|
||||
|
||||
# Добавление кода в контейнер из index.js
|
||||
COPY index.js .
|
||||
|
||||
# Установка рабочей папки для вводных данных и результата
|
||||
RUN mkdir -p /var/data /var/result
|
||||
|
||||
# Запуск index.js с помощью среды выполнения Node.js
|
||||
CMD ["node", "index.js"]
|
||||
30
bondarenko_max_lab_2/app-2/index.js
Normal file
30
bondarenko_max_lab_2/app-2/index.js
Normal file
@ -0,0 +1,30 @@
|
||||
// Вторая программа лабораторной работы.
|
||||
// Вариант - 2: Ищет наименьшее число из файла /var/data/data.txt и сохраняет его третью степень в /var/result/result.txt.
|
||||
// Для реализации программы я буду использовать JavaScript с Node.js
|
||||
|
||||
// Импорт модулей
|
||||
const fs = require('fs');
|
||||
const path = require('path');
|
||||
|
||||
// Добавляем пути к папкам
|
||||
const dataFile = '/var/result/data.txt';
|
||||
const resultFile = '/var/result/result.txt';
|
||||
|
||||
// Функция для запаси наименьшего числа в кубе из data в result
|
||||
const calculateMinCubed = () => {
|
||||
// Обёртываю в try/catch
|
||||
try {
|
||||
const content = fs.readFileSync(dataFile, 'utf-8'); // Открытие файла с кодировкой UTF-8
|
||||
const numbers = content.split('\n').map(Number).filter(Boolean); // Преобразую в числа
|
||||
|
||||
const minNumber = Math.min(...numbers); // Ищу минимальное число
|
||||
const result = Math.pow(minNumber, 3); // Возвожу в 3-тью степень
|
||||
|
||||
fs.writeFileSync(resultFile, result.toString()); // Записываю результат в файл
|
||||
console.log(`Cubed minimum number (${minNumber}^3) saved to`, resultFile); // Логирую в терминал результат
|
||||
} catch (error) {
|
||||
console.error('Error processing file:', error); // Перехватываю ошибку
|
||||
}
|
||||
};
|
||||
|
||||
calculateMinCubed(); // Вызываю функцию
|
||||
10
bondarenko_max_lab_2/data/file1.txt
Normal file
10
bondarenko_max_lab_2/data/file1.txt
Normal file
@ -0,0 +1,10 @@
|
||||
25
|
||||
91
|
||||
77
|
||||
63
|
||||
45
|
||||
25
|
||||
21
|
||||
89
|
||||
6
|
||||
18
|
||||
10
bondarenko_max_lab_2/data/file2.txt
Normal file
10
bondarenko_max_lab_2/data/file2.txt
Normal file
@ -0,0 +1,10 @@
|
||||
98
|
||||
62
|
||||
45
|
||||
77
|
||||
65
|
||||
45
|
||||
61
|
||||
62
|
||||
10
|
||||
76
|
||||
10
bondarenko_max_lab_2/data/file3.txt
Normal file
10
bondarenko_max_lab_2/data/file3.txt
Normal file
@ -0,0 +1,10 @@
|
||||
37
|
||||
54
|
||||
100
|
||||
34
|
||||
1
|
||||
77
|
||||
55
|
||||
10
|
||||
30
|
||||
28
|
||||
18
bondarenko_max_lab_2/docker-compose.yml
Normal file
18
bondarenko_max_lab_2/docker-compose.yml
Normal file
@ -0,0 +1,18 @@
|
||||
version: '3'
|
||||
services:
|
||||
app1:
|
||||
build:
|
||||
context: ./app-1
|
||||
volumes:
|
||||
- ./data:/var/data # Монтируем локальную папку data в /var/data
|
||||
- ./result:/var/result # Монтируем локальную папку result в /var/result
|
||||
container_name: app1
|
||||
|
||||
app2:
|
||||
build:
|
||||
context: ./app-2
|
||||
depends_on:
|
||||
- app1
|
||||
volumes:
|
||||
- ./result:/var/result # Монтируем ту же папку result
|
||||
container_name: app2
|
||||
108
bondarenko_max_lab_3/README.md
Normal file
108
bondarenko_max_lab_3/README.md
Normal file
@ -0,0 +1,108 @@
|
||||
# Лабораторная работа 3 - REST API, Gateway и синхронный обмен между микросервисами
|
||||
### ПИбд-42 || Бондаренко Максим
|
||||
|
||||
> Цель:
|
||||
Изучение шаблона проектирования gateway, построения синхронного обмена между микросервисами и архитектурного стиля RESTful API.
|
||||
|
||||
> Задачи:
|
||||
1. Создать 2 микросервиса, реализующих CRUD на связанных сущностях.
|
||||
2. Реализовать механизм синхронного обмена сообщениями между микросервисами.
|
||||
3. Реализовать шлюз на основе прозрачного прокси-сервера nginx.
|
||||
|
||||
> Описание
|
||||
В данной лабораторной работе мы разворачиваем два микросервиса:
|
||||
|
||||
1. Authors - микросервис для управления авторами.
|
||||
2. Books - микросервис для управления книгами.
|
||||
|
||||
> Файлы-конфигурации
|
||||
1. docker-compose.yml
|
||||
```
|
||||
version: '3.7'
|
||||
|
||||
services:
|
||||
authors:
|
||||
build:
|
||||
context: ./authors
|
||||
ports:
|
||||
- "3000:3000"
|
||||
networks:
|
||||
- app-network
|
||||
|
||||
books:
|
||||
build:
|
||||
context: ./books
|
||||
ports:
|
||||
- "3001:3001"
|
||||
networks:
|
||||
- app-network
|
||||
depends_on:
|
||||
- authors
|
||||
|
||||
nginx:
|
||||
image: nginx:latest
|
||||
ports:
|
||||
- "80:80"
|
||||
volumes:
|
||||
- ./nginx.conf:/etc/nginx/nginx.conf
|
||||
depends_on:
|
||||
- authors
|
||||
- books
|
||||
networks:
|
||||
- app-network
|
||||
|
||||
networks:
|
||||
app-network:
|
||||
driver: bridge
|
||||
```
|
||||
|
||||
authors: Микросервис, отвечающий за управление данными об авторах, доступный на порту 3000.
|
||||
books: Микросервис, отвечающий за управление данными о книгах, доступный на порту 3001. Зависит от микросервиса authors.
|
||||
nginx: Сервис, работающий как обратный прокси-сервер, маршрутизирующий запросы к другим сервисам authors и books, слушая на порту 80.
|
||||
|
||||
2. nginx.conf
|
||||
```
|
||||
events {
|
||||
worker_connections 1024;
|
||||
}
|
||||
|
||||
http {
|
||||
upstream authors_service {
|
||||
server authors:3000;
|
||||
}
|
||||
|
||||
upstream books_service {
|
||||
server books:3001;
|
||||
}
|
||||
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
location /authors {
|
||||
proxy_pass http://authors_service;
|
||||
proxy_set_header Host $host;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
proxy_set_header X-Forwarded-Proto $scheme;
|
||||
}
|
||||
|
||||
location /books {
|
||||
proxy_pass http://books_service;
|
||||
proxy_set_header Host $host;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
proxy_set_header X-Forwarded-Proto $scheme;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
location /authors: Все запросы, начинающиеся с /authors, будут проксироваться к микросервису authors, который работает на порту 3000.
|
||||
location /books: Все запросы, начинающиеся с /books, будут проксироваться к микросервису books, который работает на порту 3001.
|
||||
|
||||
### Шаги для запуска:
|
||||
Переходим в корневую папку всего решения и пишем команду:
|
||||
```
|
||||
docker-compose up --build
|
||||
```
|
||||
|
||||
> Видео демонстрация работы
|
||||
https://cloud.mail.ru/public/hLWs/iuqweU92e
|
||||
1
bondarenko_max_lab_3/authors/.env
Normal file
1
bondarenko_max_lab_3/authors/.env
Normal file
@ -0,0 +1 @@
|
||||
PORT=3000
|
||||
20
bondarenko_max_lab_3/authors/Dockerfile
Normal file
20
bondarenko_max_lab_3/authors/Dockerfile
Normal file
@ -0,0 +1,20 @@
|
||||
# Используем базовый образ Node.js
|
||||
FROM node:14
|
||||
|
||||
# Создаем рабочую директорию в контейнере
|
||||
WORKDIR /app
|
||||
|
||||
# Копируем package.json и package-lock.json
|
||||
COPY package*.json ./
|
||||
|
||||
# Устанавливаем зависимости
|
||||
RUN npm install
|
||||
|
||||
# Копируем исходный код
|
||||
COPY . .
|
||||
|
||||
# Указываем порт, который будет слушать приложение
|
||||
EXPOSE 3000
|
||||
|
||||
# Команда для запуска приложения
|
||||
CMD ["npm", "start"]
|
||||
14
bondarenko_max_lab_3/authors/package.json
Normal file
14
bondarenko_max_lab_3/authors/package.json
Normal file
@ -0,0 +1,14 @@
|
||||
{
|
||||
"name": "authors",
|
||||
"version": "1.0.0",
|
||||
"main": "src/index.js",
|
||||
"scripts": {
|
||||
"start": "node src/index.js"
|
||||
},
|
||||
"dependencies": {
|
||||
"express": "^4.17.1",
|
||||
"swagger-jsdoc": "^6.1.0",
|
||||
"swagger-ui-express": "^4.3.0",
|
||||
"uuid": "^8.3.2"
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,50 @@
|
||||
const { Author, authors } = require('../models/authorModel');
|
||||
|
||||
const getAuthors = (req, res) => {
|
||||
res.json(authors);
|
||||
};
|
||||
|
||||
const getAuthorById = (req, res) => {
|
||||
const author = authors.find(a => a.uuid === req.params.uuid);
|
||||
if (author) {
|
||||
res.json(author);
|
||||
} else {
|
||||
res.status(404).send('Author not found');
|
||||
}
|
||||
};
|
||||
|
||||
const createAuthor = (req, res) => {
|
||||
const { name, birthdate } = req.body;
|
||||
const newAuthor = new Author(name, birthdate);
|
||||
authors.push(newAuthor);
|
||||
res.status(201).json(newAuthor);
|
||||
};
|
||||
|
||||
const updateAuthor = (req, res) => {
|
||||
const author = authors.find(a => a.uuid === req.params.uuid);
|
||||
if (author) {
|
||||
author.name = req.body.name || author.name;
|
||||
author.birthdate = req.body.birthdate || author.birthdate;
|
||||
res.json(author);
|
||||
} else {
|
||||
res.status(404).send('Author not found');
|
||||
}
|
||||
};
|
||||
|
||||
const deleteAuthor = (req, res) => {
|
||||
const authorIndex = authors.findIndex(a => a.uuid === req.params.uuid);
|
||||
if (authorIndex !== -1) {
|
||||
authors.splice(authorIndex, 1);
|
||||
res.status(204).send();
|
||||
} else {
|
||||
res.status(404).send('Author not found');
|
||||
}
|
||||
};
|
||||
|
||||
module.exports = {
|
||||
getAuthors,
|
||||
getAuthorById,
|
||||
createAuthor,
|
||||
updateAuthor,
|
||||
deleteAuthor
|
||||
};
|
||||
15
bondarenko_max_lab_3/authors/src/index.js
Normal file
15
bondarenko_max_lab_3/authors/src/index.js
Normal file
@ -0,0 +1,15 @@
|
||||
const express = require('express');
|
||||
const bodyParser = require('body-parser');
|
||||
const authorRoutes = require('./routes/authorRoutes');
|
||||
const setupSwagger = require('./swagger');
|
||||
|
||||
const app = express();
|
||||
const port = process.env.PORT || 3000;
|
||||
|
||||
app.use(bodyParser.json());
|
||||
app.use('/authors', authorRoutes);
|
||||
setupSwagger(app);
|
||||
|
||||
app.listen(port, () => {
|
||||
console.log(`Authors service is running on port ${port}`);
|
||||
});
|
||||
16
bondarenko_max_lab_3/authors/src/models/authorModel.js
Normal file
16
bondarenko_max_lab_3/authors/src/models/authorModel.js
Normal file
@ -0,0 +1,16 @@
|
||||
const { v4: uuidv4 } = require('uuid');
|
||||
|
||||
class Author {
|
||||
constructor(name, birthdate) {
|
||||
this.uuid = uuidv4();
|
||||
this.name = name;
|
||||
this.birthdate = birthdate;
|
||||
}
|
||||
}
|
||||
|
||||
const authors = [];
|
||||
|
||||
module.exports = {
|
||||
Author,
|
||||
authors
|
||||
};
|
||||
166
bondarenko_max_lab_3/authors/src/routes/authorRoutes.js
Normal file
166
bondarenko_max_lab_3/authors/src/routes/authorRoutes.js
Normal file
@ -0,0 +1,166 @@
|
||||
const express = require('express');
|
||||
const {
|
||||
getAuthors,
|
||||
getAuthorById,
|
||||
createAuthor,
|
||||
updateAuthor,
|
||||
deleteAuthor
|
||||
} = require('../controllers/authorController');
|
||||
|
||||
const router = express.Router();
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* components:
|
||||
* schemas:
|
||||
* Author:
|
||||
* type: object
|
||||
* required:
|
||||
* - name
|
||||
* - birthdate
|
||||
* properties:
|
||||
* uuid:
|
||||
* type: string
|
||||
* description: The auto-generated UUID of the author
|
||||
* name:
|
||||
* type: string
|
||||
* description: The name of the author
|
||||
* birthdate:
|
||||
* type: string
|
||||
* format: date
|
||||
* description: The birthdate of the author
|
||||
* example:
|
||||
* uuid: d5fE_asz
|
||||
* name: J.K. Rowling
|
||||
* birthdate: 1965-07-31
|
||||
*/
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* tags:
|
||||
* name: Authors
|
||||
* description: The authors managing API
|
||||
*/
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* /authors:
|
||||
* get:
|
||||
* summary: Returns the list of all the authors
|
||||
* tags: [Authors]
|
||||
* responses:
|
||||
* 200:
|
||||
* description: The list of the authors
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* type: array
|
||||
* items:
|
||||
* $ref: '#/components/schemas/Author'
|
||||
*/
|
||||
router.get('/', getAuthors);
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* /authors/{uuid}:
|
||||
* get:
|
||||
* summary: Get the author by id
|
||||
* tags: [Authors]
|
||||
* parameters:
|
||||
* - in: path
|
||||
* name: uuid
|
||||
* schema:
|
||||
* type: string
|
||||
* required: true
|
||||
* description: The author id
|
||||
* responses:
|
||||
* 200:
|
||||
* description: The author description by id
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* $ref: '#/components/schemas/Author'
|
||||
* 404:
|
||||
* description: The author was not found
|
||||
*/
|
||||
router.get('/:uuid', getAuthorById);
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* /authors:
|
||||
* post:
|
||||
* summary: Create a new author
|
||||
* tags: [Authors]
|
||||
* requestBody:
|
||||
* required: true
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* $ref: '#/components/schemas/Author'
|
||||
* responses:
|
||||
* 201:
|
||||
* description: The author was successfully created
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* $ref: '#/components/schemas/Author'
|
||||
* 500:
|
||||
* description: Some server error
|
||||
*/
|
||||
router.post('/', createAuthor);
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* /authors/{uuid}:
|
||||
* put:
|
||||
* summary: Update the author by the id
|
||||
* tags: [Authors]
|
||||
* parameters:
|
||||
* - in: path
|
||||
* name: uuid
|
||||
* schema:
|
||||
* type: string
|
||||
* required: true
|
||||
* description: The author id
|
||||
* requestBody:
|
||||
* required: true
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* $ref: '#/components/schemas/Author'
|
||||
* responses:
|
||||
* 200:
|
||||
* description: The author was updated
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* $ref: '#/components/schemas/Author'
|
||||
* 404:
|
||||
* description: The author was not found
|
||||
* 500:
|
||||
* description: Some error happened
|
||||
*/
|
||||
router.put('/:uuid', updateAuthor);
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* /authors/{uuid}:
|
||||
* delete:
|
||||
* summary: Remove the author by id
|
||||
* tags: [Authors]
|
||||
* parameters:
|
||||
* - in: path
|
||||
* name: uuid
|
||||
* schema:
|
||||
* type: string
|
||||
* required: true
|
||||
* description: The author id
|
||||
* responses:
|
||||
* 204:
|
||||
* description: The author was deleted
|
||||
* 404:
|
||||
* description: The author was not found
|
||||
*/
|
||||
router.delete('/:uuid', deleteAuthor);
|
||||
|
||||
module.exports = router;
|
||||
22
bondarenko_max_lab_3/authors/src/swagger.js
Normal file
22
bondarenko_max_lab_3/authors/src/swagger.js
Normal file
@ -0,0 +1,22 @@
|
||||
const swaggerJSDoc = require('swagger-jsdoc');
|
||||
const swaggerUi = require('swagger-ui-express');
|
||||
|
||||
const options = {
|
||||
definition: {
|
||||
openapi: '3.0.0',
|
||||
info: {
|
||||
title: 'Authors API',
|
||||
version: '1.0.0',
|
||||
description: 'API for managing authors',
|
||||
},
|
||||
},
|
||||
apis: ['./src/routes/*.js'],
|
||||
};
|
||||
|
||||
const swaggerSpec = swaggerJSDoc(options);
|
||||
|
||||
const setupSwagger = (app) => {
|
||||
app.use('/api-docs', swaggerUi.serve, swaggerUi.setup(swaggerSpec));
|
||||
};
|
||||
|
||||
module.exports = setupSwagger;
|
||||
1
bondarenko_max_lab_3/books/.env
Normal file
1
bondarenko_max_lab_3/books/.env
Normal file
@ -0,0 +1 @@
|
||||
PORT=3001
|
||||
20
bondarenko_max_lab_3/books/Dockerfile
Normal file
20
bondarenko_max_lab_3/books/Dockerfile
Normal file
@ -0,0 +1,20 @@
|
||||
# Используем базовый образ Node.js
|
||||
FROM node:14
|
||||
|
||||
# Создаем рабочую директорию в контейнере
|
||||
WORKDIR /app
|
||||
|
||||
# Копируем package.json и package-lock.json
|
||||
COPY package*.json ./
|
||||
|
||||
# Устанавливаем зависимости
|
||||
RUN npm install
|
||||
|
||||
# Копируем исходный код
|
||||
COPY . .
|
||||
|
||||
# Указываем порт, который будет слушать приложение
|
||||
EXPOSE 3001
|
||||
|
||||
# Команда для запуска приложения
|
||||
CMD ["npm", "start"]
|
||||
16
bondarenko_max_lab_3/books/package.json
Normal file
16
bondarenko_max_lab_3/books/package.json
Normal file
@ -0,0 +1,16 @@
|
||||
{
|
||||
"name": "books",
|
||||
"version": "1.0.0",
|
||||
"main": "src/index.js",
|
||||
"scripts": {
|
||||
"start": "node src/index.js"
|
||||
},
|
||||
"dependencies": {
|
||||
"express": "^4.17.1",
|
||||
"swagger-jsdoc": "^6.1.0",
|
||||
"swagger-ui-express": "^4.3.0",
|
||||
"axios": "^0.21.1",
|
||||
"uuid": "^8.3.2"
|
||||
}
|
||||
}
|
||||
|
||||
72
bondarenko_max_lab_3/books/src/controllers/bookController.js
Normal file
72
bondarenko_max_lab_3/books/src/controllers/bookController.js
Normal file
@ -0,0 +1,72 @@
|
||||
const axios = require('axios');
|
||||
const { Book, books } = require('../models/bookModel');
|
||||
|
||||
const getBooks = (req, res) => {
|
||||
res.json(books);
|
||||
};
|
||||
|
||||
const getBookById = async (req, res) => {
|
||||
const book = books.find(b => b.uuid === req.params.uuid);
|
||||
if (book) {
|
||||
try {
|
||||
const authorResponse = await axios.get(`http://authors:3000/authors/${book.authorUuid}`);
|
||||
book.authorInfo = authorResponse.data;
|
||||
res.json(book);
|
||||
} catch (error) {
|
||||
res.status(500).send('Error fetching author information');
|
||||
}
|
||||
} else {
|
||||
res.status(404).send('Book not found');
|
||||
}
|
||||
};
|
||||
|
||||
const createBook = async (req, res) => {
|
||||
const { author, title, year, authorUuid } = req.body;
|
||||
|
||||
try {
|
||||
const authorResponse = await axios.get(`http://authors:3000/authors/${authorUuid}`);
|
||||
if (!authorResponse.data) {
|
||||
return res.status(404).send('Author not found');
|
||||
}
|
||||
const newBook = new Book(author, title, year, authorUuid);
|
||||
books.push(newBook);
|
||||
res.status(201).json(newBook);
|
||||
} catch (error) {
|
||||
if (error.response && error.response.status === 404) {
|
||||
res.status(404).send('Author not found');
|
||||
} else {
|
||||
res.status(500).send('Error creating book');
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
const updateBook = (req, res) => {
|
||||
const book = books.find(b => b.uuid === req.params.uuid);
|
||||
if (book) {
|
||||
book.author = req.body.author || book.author;
|
||||
book.title = req.body.title || book.title;
|
||||
book.year = req.body.year || book.year;
|
||||
book.authorUuid = req.body.authorUuid || book.authorUuid;
|
||||
res.json(book);
|
||||
} else {
|
||||
res.status(404).send('Book not found');
|
||||
}
|
||||
};
|
||||
|
||||
const deleteBook = (req, res) => {
|
||||
const bookIndex = books.findIndex(b => b.uuid === req.params.uuid);
|
||||
if (bookIndex !== -1) {
|
||||
books.splice(bookIndex, 1);
|
||||
res.status(204).send();
|
||||
} else {
|
||||
res.status(404).send('Book not found');
|
||||
}
|
||||
};
|
||||
|
||||
module.exports = {
|
||||
getBooks,
|
||||
getBookById,
|
||||
createBook,
|
||||
updateBook,
|
||||
deleteBook
|
||||
};
|
||||
15
bondarenko_max_lab_3/books/src/index.js
Normal file
15
bondarenko_max_lab_3/books/src/index.js
Normal file
@ -0,0 +1,15 @@
|
||||
const express = require('express');
|
||||
const bodyParser = require('body-parser');
|
||||
const bookRoutes = require('./routes/bookRoutes');
|
||||
const setupSwagger = require('./swagger');
|
||||
|
||||
const app = express();
|
||||
const port = process.env.PORT || 3001;
|
||||
|
||||
app.use(bodyParser.json());
|
||||
app.use('/books', bookRoutes);
|
||||
setupSwagger(app);
|
||||
|
||||
app.listen(port, () => {
|
||||
console.log(`Books service is running on port ${port}`);
|
||||
});
|
||||
18
bondarenko_max_lab_3/books/src/models/bookModel.js
Normal file
18
bondarenko_max_lab_3/books/src/models/bookModel.js
Normal file
@ -0,0 +1,18 @@
|
||||
const { v4: uuidv4 } = require('uuid');
|
||||
|
||||
class Book {
|
||||
constructor(author, title, year, authorUuid) {
|
||||
this.uuid = uuidv4();
|
||||
this.author = author;
|
||||
this.title = title;
|
||||
this.year = year;
|
||||
this.authorUuid = authorUuid;
|
||||
}
|
||||
}
|
||||
|
||||
const books = [];
|
||||
|
||||
module.exports = {
|
||||
Book,
|
||||
books
|
||||
};
|
||||
175
bondarenko_max_lab_3/books/src/routes/bookRoutes.js
Normal file
175
bondarenko_max_lab_3/books/src/routes/bookRoutes.js
Normal file
@ -0,0 +1,175 @@
|
||||
const express = require('express');
|
||||
const {
|
||||
getBooks,
|
||||
getBookById,
|
||||
createBook,
|
||||
updateBook,
|
||||
deleteBook
|
||||
} = require('../controllers/bookController');
|
||||
|
||||
const router = express.Router();
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* components:
|
||||
* schemas:
|
||||
* Book:
|
||||
* type: object
|
||||
* required:
|
||||
* - author
|
||||
* - title
|
||||
* - year
|
||||
* - authorUuid
|
||||
* properties:
|
||||
* uuid:
|
||||
* type: string
|
||||
* description: The auto-generated UUID of the book
|
||||
* author:
|
||||
* type: string
|
||||
* description: The author of the book
|
||||
* title:
|
||||
* type: string
|
||||
* description: The title of the book
|
||||
* year:
|
||||
* type: integer
|
||||
* description: The year the book was published
|
||||
* authorUuid:
|
||||
* type: string
|
||||
* description: The UUID of the author
|
||||
* example:
|
||||
* uuid: d5fE_asz
|
||||
* author: J.K. Rowling
|
||||
* title: Harry Potter
|
||||
* year: 1997
|
||||
* authorUuid: d5fE_asz
|
||||
*/
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* tags:
|
||||
* name: Books
|
||||
* description: The books managing API
|
||||
*/
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* /books:
|
||||
* get:
|
||||
* summary: Returns the list of all the books
|
||||
* tags: [Books]
|
||||
* responses:
|
||||
* 200:
|
||||
* description: The list of the books
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* type: array
|
||||
* items:
|
||||
* $ref: '#/components/schemas/Book'
|
||||
*/
|
||||
router.get('/', getBooks);
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* /books/{uuid}:
|
||||
* get:
|
||||
* summary: Get the book by id
|
||||
* tags: [Books]
|
||||
* parameters:
|
||||
* - in: path
|
||||
* name: uuid
|
||||
* schema:
|
||||
* type: string
|
||||
* required: true
|
||||
* description: The book id
|
||||
* responses:
|
||||
* 200:
|
||||
* description: The book description by id
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* $ref: '#/components/schemas/Book'
|
||||
* 404:
|
||||
* description: The book was not found
|
||||
*/
|
||||
router.get('/:uuid', getBookById);
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* /books:
|
||||
* post:
|
||||
* summary: Create a new book
|
||||
* tags: [Books]
|
||||
* requestBody:
|
||||
* required: true
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* $ref: '#/components/schemas/Book'
|
||||
* responses:
|
||||
* 201:
|
||||
* description: The book was successfully created
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* $ref: '#/components/schemas/Book'
|
||||
* 500:
|
||||
* description: Some server error
|
||||
*/
|
||||
router.post('/', createBook);
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* /books/{uuid}:
|
||||
* put:
|
||||
* summary: Update the book by the id
|
||||
* tags: [Books]
|
||||
* parameters:
|
||||
* - in: path
|
||||
* name: uuid
|
||||
* schema:
|
||||
* type: string
|
||||
* required: true
|
||||
* description: The book id
|
||||
* requestBody:
|
||||
* required: true
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* $ref: '#/components/schemas/Book'
|
||||
* responses:
|
||||
* 200:
|
||||
* description: The book was updated
|
||||
* content:
|
||||
* application/json:
|
||||
* schema:
|
||||
* $ref: '#/components/schemas/Book'
|
||||
* 404:
|
||||
* description: The book was not found
|
||||
* 500:
|
||||
* description: Some error happened
|
||||
*/
|
||||
router.put('/:uuid', updateBook);
|
||||
|
||||
/**
|
||||
* @swagger
|
||||
* /books/{uuid}:
|
||||
* delete:
|
||||
* summary: Remove the book by id
|
||||
* tags: [Books]
|
||||
* parameters:
|
||||
* - in: path
|
||||
* name: uuid
|
||||
* schema:
|
||||
* type: string
|
||||
* required: true
|
||||
* description: The book id
|
||||
* responses:
|
||||
* 204:
|
||||
* description: The book was deleted
|
||||
* 404:
|
||||
* description: The book was not found
|
||||
*/
|
||||
router.delete('/:uuid', deleteBook);
|
||||
|
||||
module.exports = router;
|
||||
22
bondarenko_max_lab_3/books/src/swagger.js
Normal file
22
bondarenko_max_lab_3/books/src/swagger.js
Normal file
@ -0,0 +1,22 @@
|
||||
const swaggerJSDoc = require('swagger-jsdoc');
|
||||
const swaggerUi = require('swagger-ui-express');
|
||||
|
||||
const options = {
|
||||
definition: {
|
||||
openapi: '3.0.0',
|
||||
info: {
|
||||
title: 'Books API',
|
||||
version: '1.0.0',
|
||||
description: 'API for managing books',
|
||||
},
|
||||
},
|
||||
apis: ['./src/routes/*.js'],
|
||||
};
|
||||
|
||||
const swaggerSpec = swaggerJSDoc(options);
|
||||
|
||||
const setupSwagger = (app) => {
|
||||
app.use('/api-docs', swaggerUi.serve, swaggerUi.setup(swaggerSpec));
|
||||
};
|
||||
|
||||
module.exports = setupSwagger;
|
||||
36
bondarenko_max_lab_3/docker-compose.yml
Normal file
36
bondarenko_max_lab_3/docker-compose.yml
Normal file
@ -0,0 +1,36 @@
|
||||
version: '3.7'
|
||||
|
||||
services:
|
||||
authors:
|
||||
build:
|
||||
context: ./authors
|
||||
ports:
|
||||
- "3000:3000"
|
||||
networks:
|
||||
- app-network
|
||||
|
||||
books:
|
||||
build:
|
||||
context: ./books
|
||||
ports:
|
||||
- "3001:3001"
|
||||
networks:
|
||||
- app-network
|
||||
depends_on:
|
||||
- authors
|
||||
|
||||
nginx:
|
||||
image: nginx:latest
|
||||
ports:
|
||||
- "80:80"
|
||||
volumes:
|
||||
- ./nginx.conf:/etc/nginx/nginx.conf
|
||||
depends_on:
|
||||
- authors
|
||||
- books
|
||||
networks:
|
||||
- app-network
|
||||
|
||||
networks:
|
||||
app-network:
|
||||
driver: bridge
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user