127 KiB
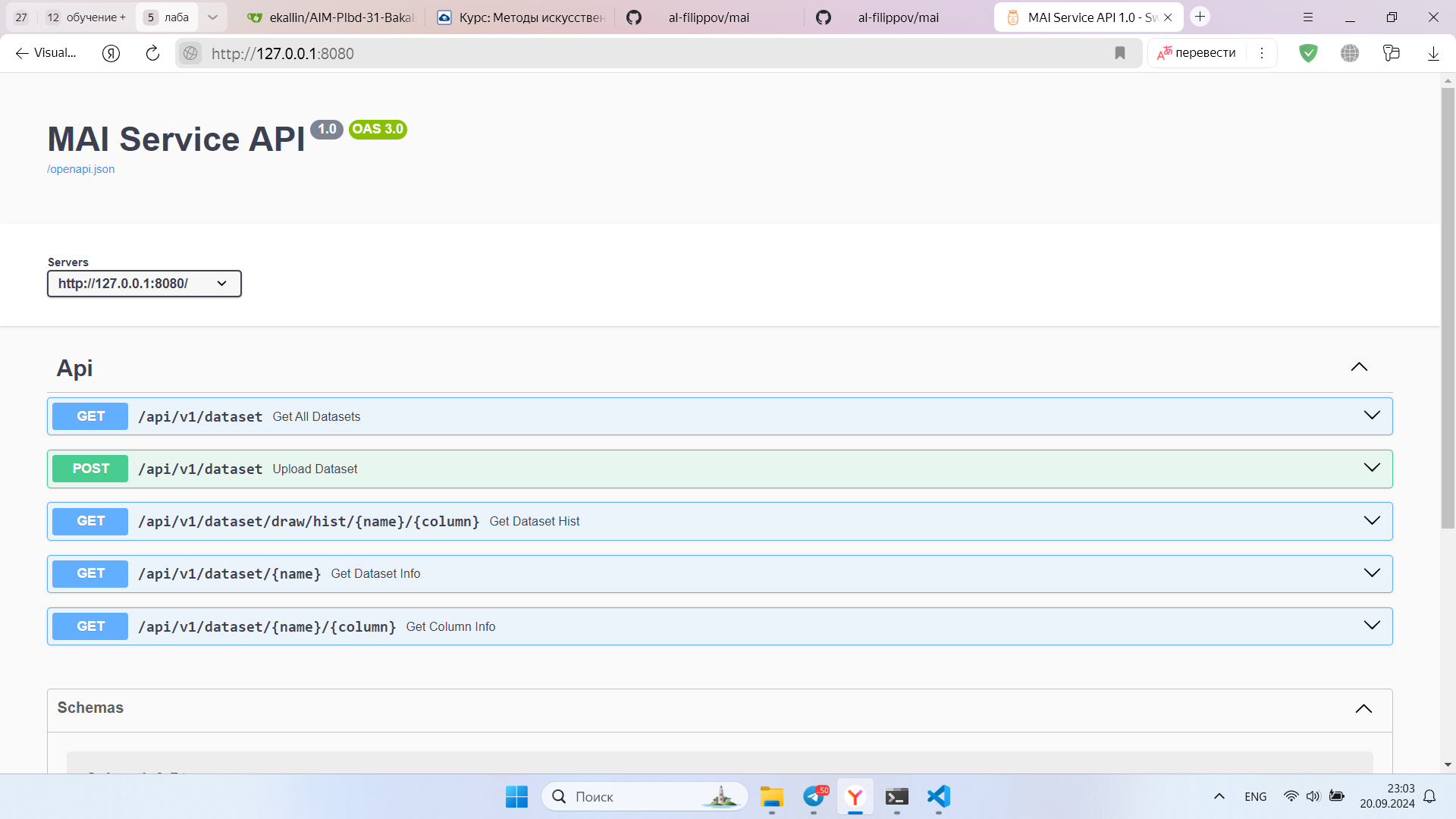
Скриншот запущенного сваггера:
import pandas as pd
import matplotlib.pyplot as plt
data_base = pd.read_csv("csv/option4.csv")
# data_base.info
# print(data_base.describe().transpose())
Вызов функции для удобного просмотра столбцов и их значений во время выполнения лабы
data_base.info
Вызов иной функции для удобного просмотра столбцов и их значений во время выполнения лабы
data_base.columns
Тренируюсь со срезами...
data_base.loc[10:11]
Все еще непонятной фигней занимаюсь...
new_data_base = data_base.sort_values("age")
А тут уже что-то интересное.
Я отбираю количество (сколько раз встречается в таблице) каждое из значений колонки "статус_курильщика" Потом с помощью функции plot отрисовываю круговую диаграмму
smoking_status_count = data_base["smoking_status"].value_counts().plot(kind='pie')
# smoking_status_count.plot(kind='bar')
plt.title("Диаграмма людей с разным статусaми курения")

Здесь я делаю то же самое, только теперь стилизую диаграмму (area) - подписываю x и y оси, добавляю title
data_base["smoking_status"].value_counts().plot(kind='area')
# smoking_status_count.plot(kind='bar')
plt.title("Количество людей с разным статусaми курения")
plt.xlabel("статусы курения")
plt.ylabel("количество людей")

Здесь не особо интересно - делаю гистограмму с разницой в количестве мужчин и женщин испытуемых
data_base["gender"].value_counts().sort_values().plot(kind='bar')

Здесь я беру данные по срезу (с 100-го челобрека по 300-го). И строю точечную диаграмму, которая отображает по иксам - курящий ли и насколько человек, а по игрекам - возраст
data_base.loc[100:300].plot.scatter(x="smoking_status", y="age")
