132 KiB
132 KiB
Работа с NumPy
In [1]:
import numpy as np
matrix = np.array([[4, 5, 0], [9, 9, 9]])
print("matrix = \n", matrix, "\n")
tmatrix = matrix.T
print("tmatrix = \n", tmatrix, "\n")
vector = np.ravel(matrix)
print("vector = \n", vector, "\n")
tvector = np.reshape(vector, (6, 1))
print("tvector = \n", tvector, "\n")
list_matrix = list(matrix)
print("list_matrix = \n", list_matrix, "\n")
str_matrix = str(matrix)
print("matrix as str = \n", str_matrix, "\n")
print("matrix type is", type(matrix), "\n")
print("vector type is", type(vector), "\n")
print("list_matrix type is", type(list_matrix), "\n")
print("str_matrix type is", type(str_matrix), "\n")
formatted_vector = "; ".join(map(str, vector))
print("formatted_vector = \n", formatted_vector, "\n")
Работа с Pandas DataFrame
Работа с данными - чтение и запись CSV
In [2]:
import pandas as pd
df = pd.read_csv("data/world-population-by-country-2020.csv", index_col="no")
df.to_csv("test.csv")
Работа с данными - основные команды
In [3]:
# df.info()
# print(df.describe().transpose())
from click import clear
cleared_df = df.drop(
df.columns.difference([
"Country (or dependency)", "Population 2020", "Yearly Change", "Net Change"
]
),
axis=1,
)
# print(cleared_df.head())
# print(cleared_df.tail())
cleared_df['Population 2020'] = cleared_df['Population 2020'].apply(
lambda x: int("".join(x.split(",")))
)
cleared_df["Net Change"] = cleared_df["Net Change"].apply(
lambda x: int("".join(x.split(",")))
)
cleared_df["Yearly Change"] = cleared_df["Yearly Change"].apply(
lambda x: float("".join(x.rstrip('%')))
)
sorted_df = cleared_df.sort_values(
["Population 2020", "Net Change", "Country (or dependency)"], ascending=[False, False, True]
)
print(sorted_df.head())
print(sorted_df.tail())
Работа с данными - работа с элементами
In [4]:
print(df["Country (or dependency)"])
print(df.loc[100])
print(df.loc[100, "Country (or dependency)"])
print(df.loc[100:200, ["Country (or dependency)", "Population 2020"]])
print(df[0:3])
print(df.iloc[0])
print(df.iloc[2:5, 0:2])
print(df.iloc[[3, 4], [0, 2]])
Работа с данными - отбор и группировка
In [5]:
# s_values = df["Sex"].unique()
# print(s_values)
df2 = pd.read_csv(
"data/countries-continents-capitals.csv", index_col="Country/Territory",
encoding = "ISO-8859-1"
)
# for s_value in s_values:
# count = df[df["Sex"] == s_value].shape[0]
# s_total += count
# print(s_value, "count =", count)
# print("Total count = ", s_total)
extended_df = cleared_df.set_index("Country (or dependency)").join(
df2
)
print(extended_df)
# print(extended_df.groupby(["Continent"]).agg({"population" : ["sum"]}))
Визуализация - Исходные данные
In [6]:
data = extended_df[["Population 2020", "Yearly Change", "Continent"]].copy()
data.dropna(subset=["Population 2020"], inplace=True)
print(data)
Визуализация - Сводка пяти чисел
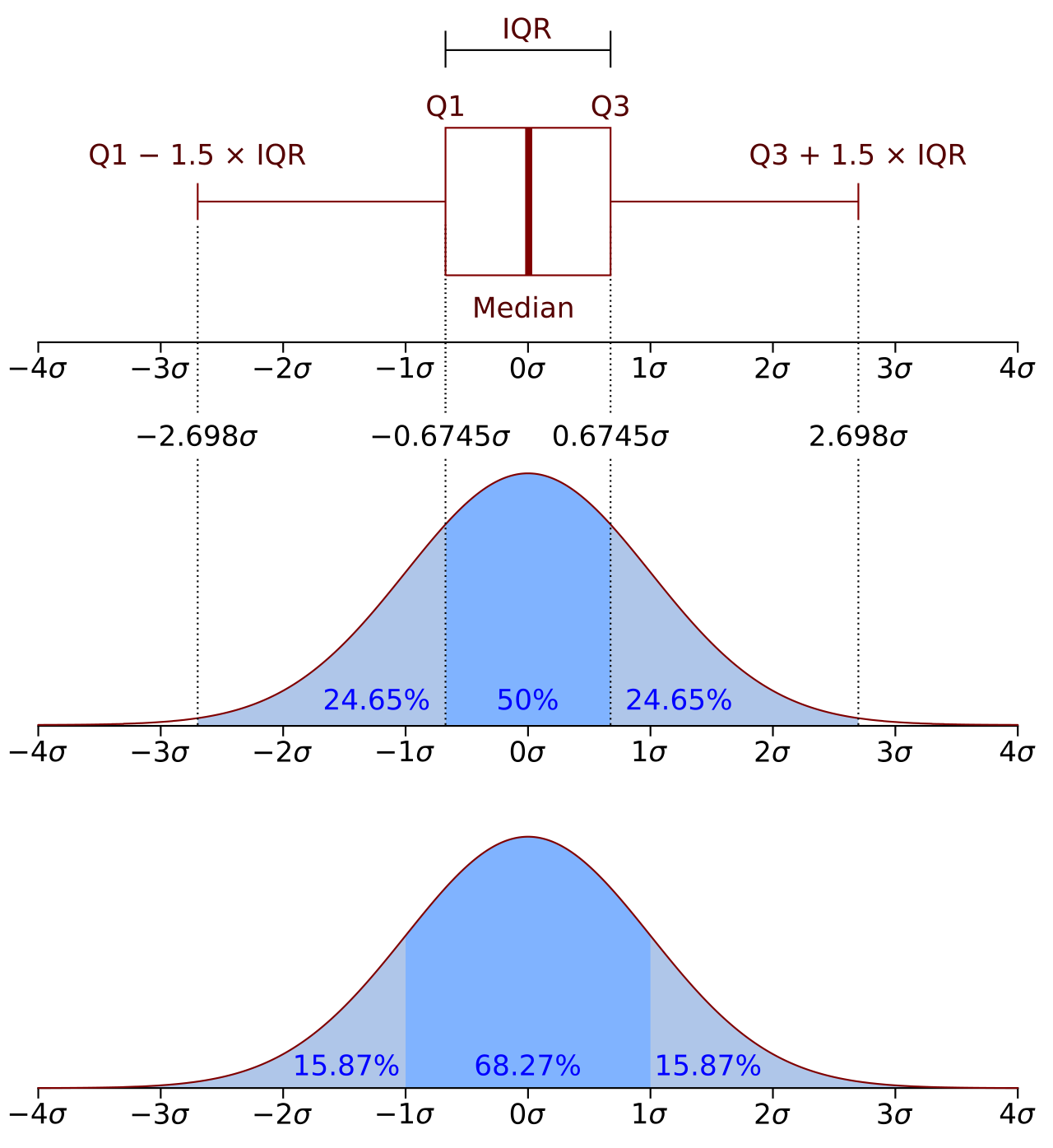
In [7]:
def q1(x):
return x.quantile(0.25)
# median = quantile(0.5)
def q2(x):
return x.quantile(0.5)
def q3(x):
return x.quantile(0.75)
def iqr(x):
return q3(x) - q1(x)
def low_iqr(x):
return max(0, q1(x) - 1.5 * iqr(x))
def high_iqr(x):
return q3(x) + 1.5 * iqr(x)
quantiles = (
data[["Continent", "Population 2020"]]
.groupby(["Continent"])
.aggregate(["min", q1, q2, "median", q3, "max"])
)
print(quantiles)
iqrs = (
data[["Continent", "Population 2020"]]
.groupby(["Continent"])
.aggregate([low_iqr, iqr, high_iqr])
)
print(iqrs)
data.boxplot(column="Population 2020", by="Continent")
Out[7]:

Визуализация - Гистограмма
In [8]:
data.plot.hist(column=["Population 2020"], bins=80)
Out[8]:

Визуализация - Точечная диаграмма
In [9]:
print(cleared_df)
cleared_df.head(5).plot.scatter(x="Country (or dependency)", y="Population 2020")
Out[9]:

Визуализация - Столбчатая диаграмма
In [10]:
# plot = data.groupby(["Pclass", "Survived"]).size().unstack().plot.bar(color=["pink", "green"])
# plot.legend(["Not survived", "Survived"])
Визуализация - Временные ряды
In [11]:
from datetime import datetime
import matplotlib.dates as md
ts = pd.read_csv("data/world-population-forcast-2020-2050.csv", encoding="ISO-8859-1")
print(ts)
ts.iloc[:, 1] = ts.iloc[:, 1].apply(lambda row: int("".join(str(row).split(","))))
ts.info()
print(ts.columns.values)
plot = ts.plot.line(x="Year", y="Population")
