4.7 KiB
Лабораторная работа №1
ПИбд-42 Машкова Маргарита (Вариант 19)
Задание
Cгенерировать определенный тип данных и сравнить на нем 3 модели по варианту. Построить графики, отобразить качество моделей, объяснить полученные результаты.
Данные:
make_moons (noise=0.3, random_state=rs)
Модели:
- Линейная регрессия
- Полиномиальная регрессия (со степенью 5)
- Гребневая полиномиальная регрессия (со степенью 5, alpha= 1.0)
Запуск программы
Для запуска программы необходимо запустить файл main.py
Используемые технологии
Язык программирования: python
Библиотеки:
matplotlib- пакет для визуализации данных.sklearn- предоставляет широкий спектр инструментов для машинного обучения, статистики и анализа данных.
Описание работы программы
Изначально генерируются синтетические данные Х и у для проведения экспериментов при помощи функции make_moons с заданными параметрами.
Функция train_test_split делит данные так, что тестовая выборка составляет 40% от исходного набора данных.
Разделение происходит случайным образом (т.е. элементы берутся из исходной выборки не последовательно).
После чего для каждой из заданных по варианту моделей выполняются следующие действия:
- Создание модели с заданными параметрами.
- Обучение модели на исходных данных.
- Предсказание модели на тестовых данных.
- Оценка качества модели по 3 метрикам:
-
Коэффициент детерминации: метрика, которая измеряет, насколько хорошо модель соответствует данным. Принимает значения от 0 до 1, где 1 означает идеальное соответствие модели данным, а значения ближе к 0 указывают на то, что модель плохо объясняет вариацию в данных. Для вычисления коэффициента детерминации модели используется метод
scoreбиблиотеки scikit-learn. -
Средняя абсолютная ошибка (MAE): Для вычисления данной метрики используется метод
mean_absolute_errorбиблиотеки scikit-learn. -
Средняя квадратичная ошибка (MSE): Для вычисления данной метрики используется метод
mean_squared_errorбиблиотеки scikit-learn.
Последние 2 метрики измеряют разницу между предсказанными значениями модели и фактическими значениями. Меньшие значения MAE и MSE указывают на лучшую производительность модели.
Вычисленные значения метрик выводятся в консоль.
После чего строятся графики, отображающие работу моделей. На первом графике отображаются ожидаемые результаты предсказания, на остальных - предсказания моделей. Чем меньше прозрачных точек - тем лучше отработала модель.
Тесты
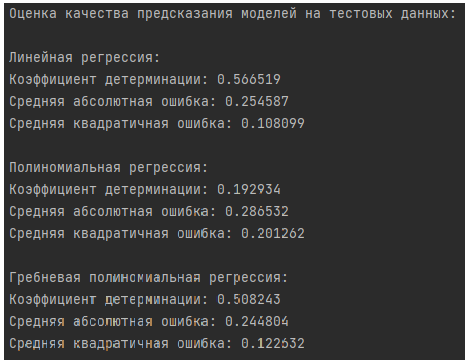
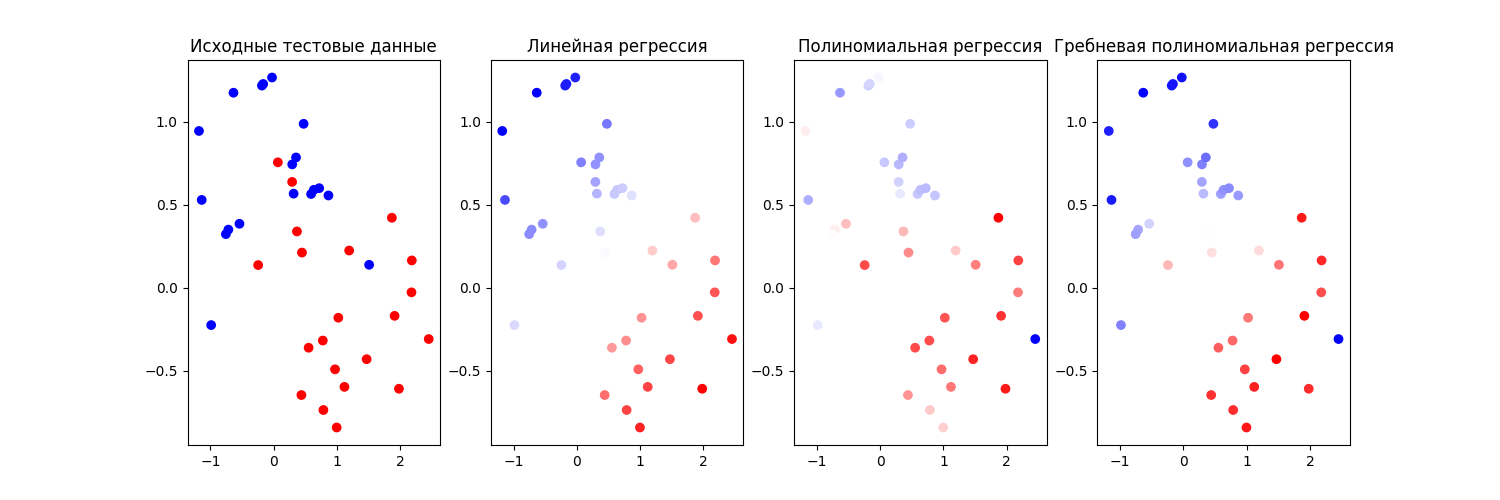
Вывод: исходя из полученных результатов, схожую хорошую производительность имеют линейная регрессия и гребневая полиномиальная регрессия. Самую низкую производительность имеет полиномиальная регрессия.