5.5 KiB
Лабораторная работа №6
Нейронная сеть
ПИбд-41 Арзамаскина Милана
Вариант №2
Задание:
Использовать нейронную сеть для данных из таблицы 1 по варианту, самостоятельно сформулировав задачу. Интерпретировать результаты и оценить, насколько хорошо она подходит для решения сформулированной вами задачи.
Задача по варианту №2: с помощью нейронной сети MLPRegressor.
Формулировка задачи:
Задача: посмотреть, как зависит количество выбросов промышленным производством, от таких признаков как: выбросы от сжигания и газа.
Зависит ли количество выбросов промышленным производством от сжигания (огня) и газа, так как производства могут применять сжигание с целью избавления от промышленных выбросов.
Данные:
Этот набор данных обеспечивает углубленный анализ глобальных выбросов CO2 на уровне страны, позволяя лучше понять, какой вклад каждая страна вносит в глобальное совокупное воздействие человека на климат. Он содержит информацию об общих выбросах, а также от добычи и сжигания угля, нефти, газа, цемента и других источников. Данные также дают разбивку выбросов CO2 на душу населения по странам, показывая, какие страны лидируют по уровням загрязнения, и определяют потенциальные области, где следует сосредоточить усилия по сокращению выбросов. Этот набор данных необходим всем, кто хочет получить информацию о своем воздействии на окружающую среду или провести исследование тенденций международного развития.
Данные организованы с использованием следующих столбцов:
- Country: название страны
- ISO 3166-1 alpha-3: трехбуквенный код страны
- Year: год данных исследования
- Total: общее количество CO2, выброшенное страной в этом году
- Coal: количество CO2, выброшенное углем в этом году
- Oil: количество выбросов нефти
- Gas: количество выбросов газа
- Cement: количество выбросов цемента
- Flaring: выбросы от сжигания
- Other: другие формы, такие как промышленные процессы
- Per Capita: столбец «на душу населения»
Какие технологии использовались:
Используемые библиотеки:
- pandas
- matplotlib
- sklearn
Как запустить:
- установить python, sklearn, pandas, matplotlib
- запустить проект (стартовая точка - main.py)
Что делает программа:
- Загружает набор данных из файла 'CO2.csv', который содержит информацию о выбросах странами CO2 в год от различной промышленной деятельности.
- Очищает набор данных путём удаления строк с нулевыми значениями и глобальными значениями по всем странам (строки 'Global') из набора.
- Выбирает набор признаков (features) из данных, которые будут использоваться.
- Определяет целевую переменную (task) является 'other'.
- Делит данные на обучающий и тестовый наборы для обеих задач с использованием функции train_test_split. Тестовый набор составляет 10% от исходных данных.
- Решает задачу регрессии с помощью нейронной сети MLPRegressor.
- Предсказывает значения целевой переменной на тестовых наборах.
- Выводит коэффициент детерминации для оценки соответствия модели данным.
Результаты работы программы:
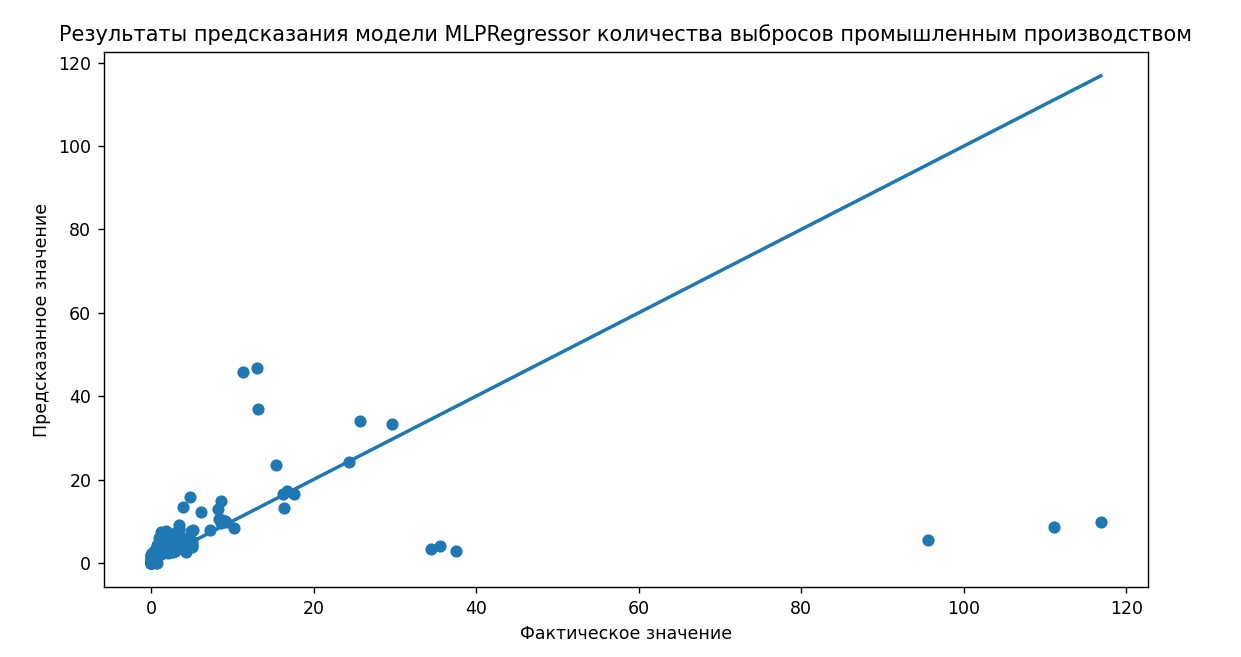

Вывод:
Точность работы модели на выбранных данных достаточно низкая, модель не справилась со своей задачей, возможно, другие методы могут выдать лучшие результаты, либо необходима модификация модели.