4.9 KiB
Лабораторная работа №2
ПИбд-42 Машкова Маргарита (Вариант 19)
Задание
Выполнить ранжирование признаков с помощью указанных по варианту моделей. Отобразить получившиеся значения\оценки каждого признака каждым методом\моделью и среднюю оценку. Провести анализ получившихся результатов. Какие четыре признака оказались самыми важными по среднему значению?
Модели:
- Линейная регрессия (LinearRegression)
- Гребневая регрессия (Ridge)
- Лассо (Lasso)
- Случайное Лассо (RandomizedLasso)
Note
Модель
RandomizedLassoбыла признана устаревшей в scikit-learn 0.19 и удалена в 0.21. Вместо нее будет использоваться регрессор случайного лесаRandomForestRegressor.
Запуск программы
Для запуска программы необходимо запустить файл main.py
Используемые технологии
Язык программирования: python
Библиотеки:
numpy- используется для работы с массивами.sklearn- предоставляет широкий спектр инструментов для машинного обучения, статистики и анализа данных.
Описание работы программы
Для начала необходимо сгенерировать исходные данные (Х) - 750 строк-наблюдений и 14 столбцов-признаков. Затем задать функцию-выход (Y): регрессионную проблему Фридмана, когда на вход моделей подается 14 факторов, выход рассчитывается по формуле, использующей только пять факторов, но факторы 11-14 зависят от факторов 1-4. Соотвественно, далее добавляется зависимость для признаков (факторов) х11, х12, х13, х14 от х1, х2, х3, х4.
Далее создаются модели, указанные в варианте задания, и выполняется их обучение.
После чего в единый массив размера 4×14 (количество_моделей и количество_признаков) выгружаются все оценки
моделей по признакам. Находятся средние оценки и выводится результат в формате списка пар {номер_признака – средняя_оценка},
отсортированном по убыванию. Оценки признаков получаются через поле coef_ у моделей LinearRegression, Ridge и Lasso.
У модели RandomForestRegressor - через поле feature_importances_.
Для удобства отображения данных оценки помещаются в конструкцию вида:
[имя_модели : [{имя_признака : оценка},{имя_признака : оценка}...]].
Таким образом, получаем словарь, в котором располагаются 4 записи из четырнадцати пар каждая.
Ключом является имя модели.
Тесты
Оценки важности признаков моделями

Оценки важности признаков моделями, отсортированные по убыванию

Средние оценки важности признаков
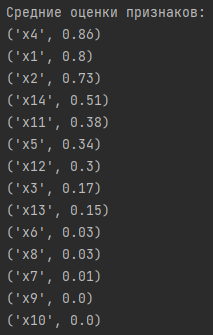
Вывод: основываясь на средних оценках, четырьмя наиболее важными празнаками оказались:
x4 (0.86), x1 (0.8), x2 (0.73), x14 (0.51).
Все модели оценили как наиболее важные признаки x1, x2, x4, и четвертым важным признаком выбрали зависимые признаки:
LinearRegression - х11, Ridge - х14, RandomForestRegressor - х14. Модель Lasso включила также независимый признак - х5.