| .. | ||
| 1_linear_regression.png | ||
| 2_perceptron.png | ||
| 3_poly_ridge.png | ||
| lab1.py | ||
| README.md | ||
{kind=link}
{kind=link}
{kind=link}
Лабораторная работа №1. Работа с типовыми наборами данных и различными моделями
12 вариант
Задание:
Используя код из пункта «Регуляризация и сеть прямого распространения», сгенерируйте определенный тип данных и сравните на нем 3 модели (по варианту). Постройте графики, отобразите качество моделей, объясните полученные результаты.
Данные по варианту:
- make_classification (n_samples=500, n_features=2, n_redundant=0, n_informative=2, random_state=rs, n_clusters_per_class=1)
Модели по варианту:
- Линейная регрессия
- Персептрон
- Гребневая полиномиальная регрессия (со степенью 4, alpha = 1.0)
Запуск
- Запустить файл lab1.py
Используемые технологии
- Язык программирования Python
- Среда разработки PyCharm
- Библиотеки:
- numpy
- sklearn
- matplotlib
Описание программы
Программа генерирует набор данных с помощью функции make_classification() с заданными по варианту параметрами. После этого происходит вывод в консоль качества данных моделей по варианту и построение графикиков для этих моделей.
Оценка точности происходит при помощи встроенного в модели метода метода .score(), который вычисляет правильность модели для набора данных.
Пример работы
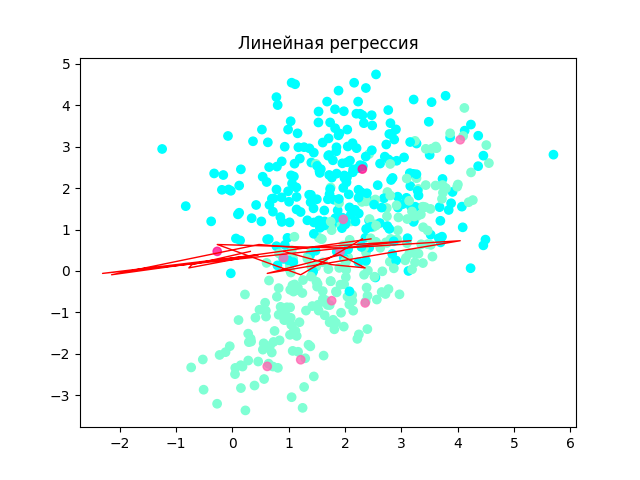
===> Линейная регрессия <===
Оценка точности: 0.4513003751817972
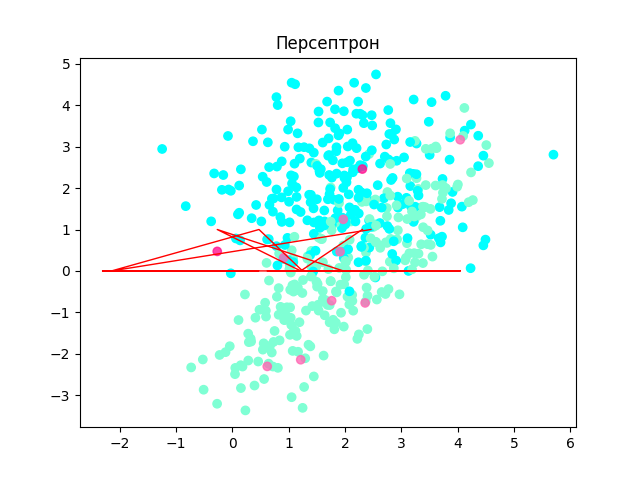
===> Персептрон <===
Оценка точности: 0.7591836734693878
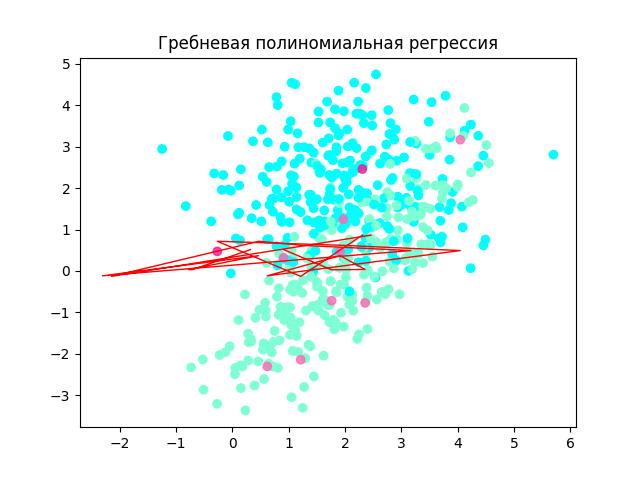
===> Гребневая полиномиальная регрессия <===
Оценка точности: 0.5312017992195672
Вывод
Согласно выводу в консоль оценок точности, лучший результат показала модель персептрона