3.6 KiB
Лабораторная работа №3
ПИбд-41, Курмыза Павел
Датасет по варианту: https://www.kaggle.com/datasets/jessemostipak/hotel-booking-demand.
Данный набор данных содержит информацию о бронировании городской и курортной гостиниц и включает в себя такие сведения, как время бронирования, продолжительность пребывания, количество взрослых, детей и/или младенцев, количество свободных парковочных мест и т.д.
Как запустить ЛР
- Запустить файл main.py
Используемые технологии
- Язык программирования Python
- Библиотеки: sklearn, numpy, pandas, xgboost, matplotlib, seaborn
Что делает программа
Программа решает задачу классификации на выбранном датасете: определение гостиничного класса отеля (городской отель или курортный отель). Решение достигается в несколько этапов:
- Предобработка данных
- Балансировка данных
- Стандартизация данных и приведение их к виду, удобном для работы с моделями ML
- Использование нескольких моделей классификации
- Сравнение оценок и поиск наиболее подходящей модели
- Оценка специфичности наилучшей модели классификации
Тестирование
Для решения задачи классификации были выбраны 3 модели: XGBClassifier, RandomForestClassifier, DecisionTreeClassifier.
Оценка точности моделей:
- XGBClassifier: 0.970565942395149
- RandomForestClassifier: 0.9901465386558869
- DecisionTreeClassifier: 0.9714502273875695
Оцека способности модели RandomForestClassifier предсказывать истинные положительные результаты (TP / (TP + FN)), также известные как коэффициент чувствительности, и истинные отрицательные результаты (TN / (TN + FP)), также известный как коэффициент специфичности через матрицу неточностей:
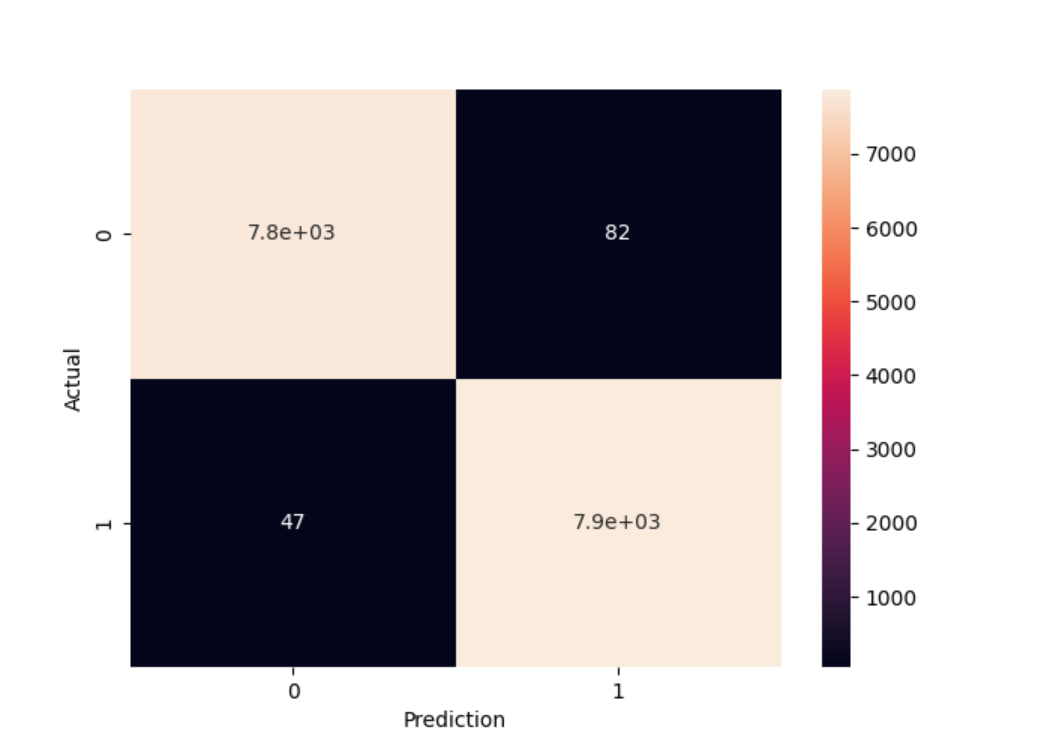
Матрица неточностей подтверждает приведенную ранее оценку модели RandomForestClassifier. Кроме того, она указывает на то, что помимо высокой точности, модель также имеет высокую специфичность.
Вывод
По итогу тестирования было выявлено, что наилучше всего с задачей классификации данного набора данных справляется модель RandomForestClassifier, так как имеет наивысшую оценку точности. Тем не менее, все из выбранных моделей показали высокие результаты. Из этого следует, что задача классификации для данного набора решена.