5.4 KiB
Задание
- Часть 1. По данным о пассажирах Титаника решите задачу классификации (с помощью дерева решений), в которой по различным характеристикам пассажиров требуется найти у выживших пассажиров два наиболее важных признака из трех рассматриваемых (по варианту). Вариант: Pclass, Sex, Embarked
- Часть 2. Решите с помощью библиотечной реализации дерева решений задачу: Запрограммировать дерево решений как минимум на 99% ваших данных для задачи: Зависимость Мошенничества (fraud_label) от возраста (Age) и пола (gender) . Проверьте работу модели на оставшемся проценте, сделайте вывод.
Как запустить лабораторную работу:
1 часть ЛР запускается в файле zavrazhnova_svetlana_lab_3_1.py через Run, в консоли должны появится вычисления.
2 часть ЛР запускается в файле zavrazhnova_svetlana_lab_3_2.py через Run, в консоли должны появится вычисления.
Технологии
В библиотеке scikit-learn решающие деревья реализованы в классах sklearn.tree.DecisionTreeСlassifier (для классификации) и sklearn.tree.DecisionTreeRegressor (для регрессии).
Что делает лабораторная:
Часть 1:
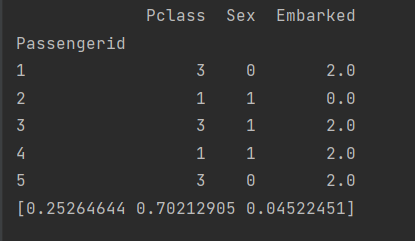
- Загружается выборка из файла titanic.csv с помощью пакета Pandas
- Отбирается в выборку 3 признака: класс пассажира (Pclass), его пол (Sex) и Embarked.
- Определяется целевая переменная (2urvived)
- Обучается решающее дерево с параметром random_state=241 и остальными параметрами по умолчанию (речь идет о параметрах конструктора DecisionTreeСlassifier)
- Выводятся важности признаков
Часть 2:
- Загружается выборка из файла fraud_dataset.csv с помощью пакета Pandas
- Отбирается в выборку 2 признака: возраст жертвы мошенничества (age) и его пол (gender).
- Определяется целевая переменная (fraud_label)
- Резделяются данные на обучающую и тестовую
- Обучается решающее дерево классификацией DecisionTreeСlassifier и регрессией DecisionTreeRegressor
- Выводятся важности признаков, предсказание значений на тестовой выборке и оценка производительности модели
Пример выходных значений:
Часть 1: Выводится список из первых 5 записей в таблице с нужными столбцами и важности признаков по каждому классу
Часть 2:

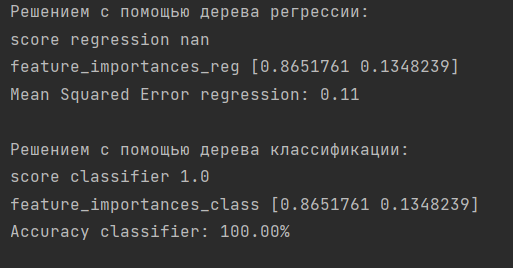
Вывод по 2 части ЛР:
Исходя из этих результатов, можно сделать вывод, что для задачи предсказания мошенничества (fraud_label) на основе возраста (age) и пола (gender) лучше подходит модель дерева классификации. Она показала 100% точность на тестовой выборке, а также позволяет определить важности признаков.
С другой стороны, дерево регрессии показало неопределенный R^2 score и имеет значительно большую среднеквадратичную ошибку, что говорит о том, что эта модель не подходит для данной задачи.
Результат regression score = nan происходит из-за того, что при test_size=0.01 выделенная тестовая выборка содержит меньше двух образцов. Это приводит к неопределенности значения коэффициента детерминации R^2, который вычисляется в случае регрессии. Таким образом, значение score regression становится "nan".
Однако, в случае классификации, где используется DecisionTreeClassifier, в test_size=0.01 попадает достаточное количество образцов для оценки производительности модели. Поэтому значение score classifier равно 1.0.
Таким образом, для задачи классификации мошенничества на основе возраста и пола более предпочтительна модель дерева классификации.