8.1 KiB
Лабораторная работа №3. Деревья решений
14 вариант
Задание:
Решите с помощью библиотечной реализации дерева решений задачу из лабораторной работы «Веб-сервис «Дерево решений» по предмету «Методы искусственного интеллекта»на 99% ваших данных. Проверьте работу модели на оставшемся проценте, сделайте вывод
Описание используемого набора данных:
Объектом исследования является набор данных, который размещен на платформе Kaggle (https://www.kaggle.com/datasets/nelgiriyewithana/top-spotify-songs-2023/data). Он представляет собой полный список самых известных песен 2023 года, перечисленных на Spotify. Данный набор представлен в виде файла spotify.csv
Столбцами являются:
- track_name – Название композиции
- artist(s)_name – Имя исполнителя/имена исполнителей песни.
- artist_count – Количество исполнителей, участвовавших в со-здании песни
- released_year – Год, когда песня была выпущена
- released_month – Месяц, когда песня была выпущена
- released_day – День месяца, когда песня была выпущена.
- in_spotify_playlists – Количество плейлистов Spotify, в которые песня включена
- in_spotify_charts – Присутствие и рейтинг песни в чартах Spotify.
- streams – Общее количество прослушиваний в Spotify.
- in_apple_playlists – Количество плейлистов Apple Music, в которые песня включена.
- in_apple_charts – Присутствие и рейтинг песни в чартах Apple Music.
- in_deezer_playlists – Количество плейлистов Deezer, в ко-торые песня включена.
- in_deezer_charts – Присутствие и рейтинг песни в чартах Deezer
- in_shazam_charts – Присутствие и рейтинг песни в чартах Shazam.
- bpm – Количество ударов в минуту, показатель темпа песни.
- key – Тональность песни.
- mode – Режим песни (мажорный или минорный).
- danceability_% – Процент, указывающий, насколько песня подходит для танцев.
- valence_% - Позитивность музыкального содержания пес-ни
- energy_% - Воспринимаемый уровень энергии песни
- acousticness_% - Количество акустического звука в песне
- instrumentalness_% - Количество инструментального кон-тента в песне
- liveness_% - Наличие элементов живого исполнения
- speechiness_% - Количество произнесенных слов в песне
Задачей регрессии на данном наборе данных является прогнозирование значения столбца «in_spotify_playlists» по столбцам «streams», «in_apple_playlists», «in_deezer_playlists» и «bpm».
Запуск
- Запустить файл lab6.py
Используемые технологии
- Язык программирования Python
- Среда разработки PyCharm
- Библиотеки:
- sklearn
- numpy
- pandas
Описание программы
Код программы выполняет следующие действия:
-
Импортирует необходимые библиотеки: pandas, numpy, train_test_split из sklearn.model_selection и DecisionTreeClassifier из sklearn.tree.
-
Загружает данные из файла "spotify.csv" в объект DataFrame под названием "data".
-
Удаляет все строки с пропущенными значениями из DataFrame "data".
-
Удаляет столбец "artist(s)_name" из DataFrame "data".
-
Задает список столбцов, которые требуется нормализовать.
-
Проходит по каждому столбцу из списка "columns_to_normalize" и выполнит нормализацию значений в диапазоне от 0 до 1.
-
Удаляет запятые из значений в столбце "in_deezer_playlists".
-
Приводит столбец "in_deezer_playlists" к числовому типу данных (np.int64).
-
Удаляет запятые из значений в столбце "in_shazam_charts".
-
Приводит столбец "in_shazam_charts" к числовому типу данных (np.int64).
-
Создает словарь "track_name_dict" соответствия числовых значений и названий трека.
-
Заменяет значения в столбце "track_name" на числовые значения согласно словарю "track_name_dict".
-
Создает словарь "key_dict" соответствия числовых значений и тональностей.
-
Заменяет значения в столбце "key" на числовые значения согласно словарю "key_dict".
-
Создает словарь "mode_dict" соответствия числовых значений и режимов песни.
-
Заменяет значения в столбце "mode" на числовые значения согласно словарю "mode_dict".
-
Разбивает данные на обучающую и тестовую выборки (X_train, X_test, y_train, y_test) с помощью функции train_test_split.
-
Инициализирует модель DecisionTreeClassifier с параметром random_state=241.
-
Обучает модель на обучающих данных (X_train, y_train) с помощью метода fit.
-
Вычисляет важность каждого признака с помощью атрибута feature_importances_ модели и сохраняет результаты в переменной "importances".
-
Получает список названий столбцов из DataFrame "data" и сохраняет их в переменной "columns".
-
Выводит важность каждого признака по результатам ранжирования в порядке убывания с помощью цикла и функции print. Каждая строка состоит из названия признака и его важности.
Таким образом, данный код выполняет предобработку данных, обучает модель DecisionTreeClassifier и оценивает значимость признаков для предсказания переменной "in_spotify_playlists".
Пример работы
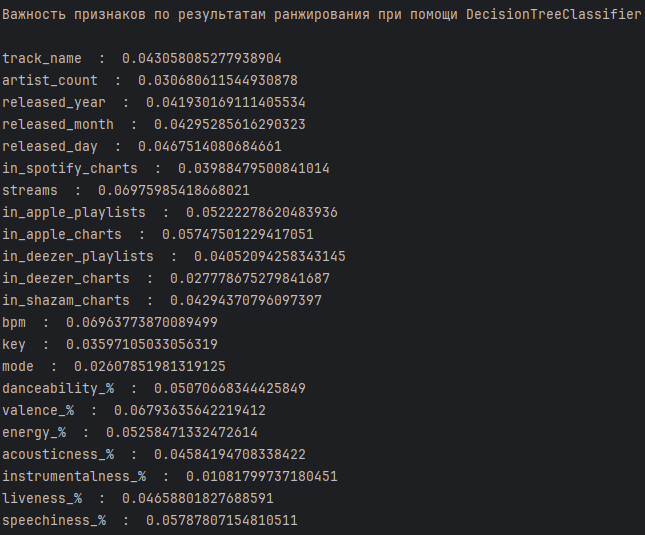
Оценка значимости признаков для предсказания переменной "in_spotify_playlists"
Вывод
На основе выходных данных можно сделать следующий вывод о работе модели:
Наиболее важными признаками для предсказания переменной "in_spotify_playlists" оказались «streams», «in_apple_playlists», «in_deezer_playlists», «bpm».