3.3 KiB
Лабораторная работа №1. Работа с типовыми наборами данных и различными моделями
14 вариант
Задание:
Используя код из пункта «Регуляризация и сеть прямого распространения», сгенерируйте определенный тип данных и сравните на нем 3 модели (по варианту). Постройте графики, отобразите качество моделей, объясните полученные результаты.
Данные по варианту:
- make_circles (noise=0.2, factor=0.5, random_state=rs)
Модели по варианту:
- Линейная регрессия
- Персептрон
- Гребневая полиномиальная регрессия (со степенью 4, alpha = 1.0)
Запуск
- Запустить файл lab1.py
Используемые технологии
- Язык программирования Python
- Среда разработки PyCharm
- Библиотеки:
- sklearn
- matplotlib
Описание программы
Программа генерирует набор данных с помощью функции make_circles() с заданными по варианту параметрами. После этого происходит создание и обучение моделй, вывод в консоль качества данных моделей по варианту и построение графикиков для этих моделей.
Оценка точности происходит при помощи MAE (средняя абсолютная ошибка, измеряет среднюю абсолютную разницу между прогнозируемыми значениями модели и фактическими значениями целевой переменной) и MSE (средняя квадратическая ошибка, измеряет среднюю квадратичную разницу между прогнозируемыми значениями модели и фактическими значениями целевой переменной). Модель с наименьшими показателями MSE и MAE считается наиболее приспособленной к задаче предсказания.
Пример работы
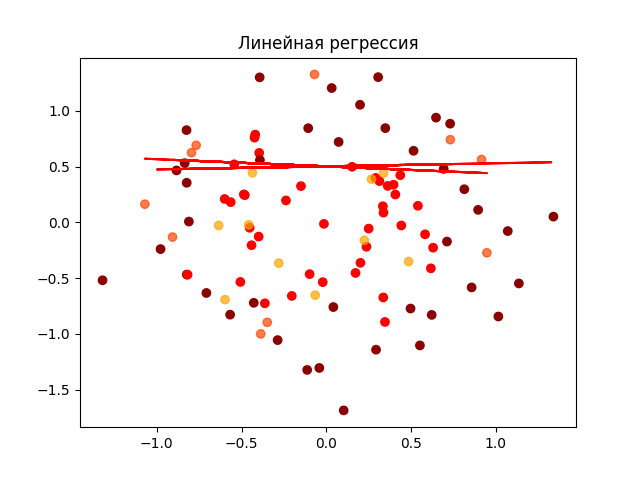
===> Линейная регрессия <===
MAE 0.5039063025033765
MSE 0.254199973993164
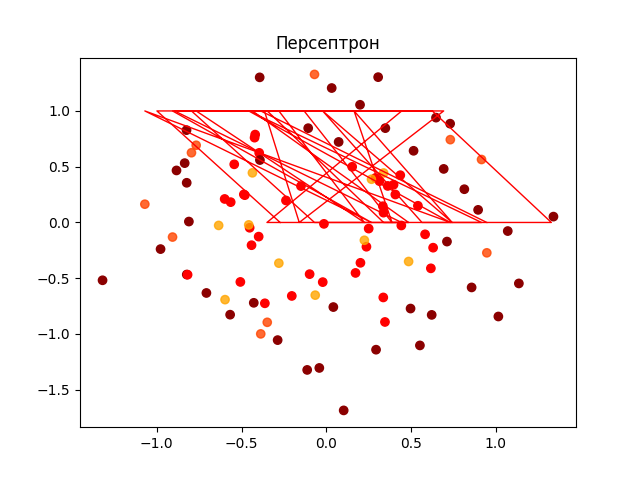
===> Персептрон <===
MAE 0.5
MSE 0.5
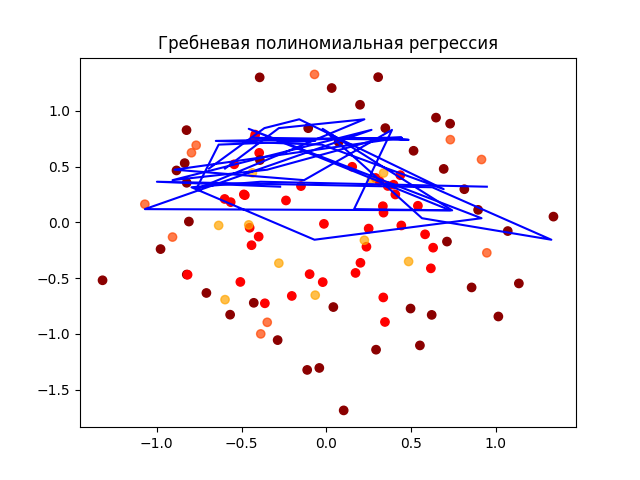
===> Гребневая полиномиальная регрессия <===
MAE 0.24796914724994906
MSE 0.07704666136671298
Вывод
Моделью с наименьшими значениями MAE и MSE оказалась модель гребневой полиномиальной регресссии, следоватьельно ее можно назвать наиболее подходящей для задачи регрессии при данной конфигурации исходных данных.