7.9 KiB
Лабораторная работа №3
Деревья решений
Задание:
-
Задача регресcии: предсказание общего объема выбросов СО2 (Total) страной (Country) за определённый год (Year).
-
Задача классификации: предсказание процента выбросов СО2 от добычи нефти (procent oil) страной (Country) с учётом общего объёма выбросов (Total) за определённый год (Year) (или: какая часть выбросов придётся на добычу нефти).
Данные:
Этот набор данных обеспечивает углубленный анализ глобальных выбросов CO2 на уровне страны, позволяя лучше понять, какой вклад каждая страна вносит в глобальное совокупное воздействие человека на климат. Он содержит информацию об общих выбросах, а также от добычи и сжигания угля, нефти, газа, цемента и других источников. Данные также дают разбивку выбросов CO2 на душу населения по странам, показывая, какие страны лидируют по уровням загрязнения, и определяют потенциальные области, где следует сосредоточить усилия по сокращению выбросов. Этот набор данных необходим всем, кто хочет получить информацию о своем воздействии на окружающую среду или провести исследование тенденций международного развития.
Данные организованы с использованием следующих столбцов:
- Country: название страны
- ISO 3166-1 alpha-3: трехбуквенный код страны
- Year: год данных исследования
- Total: общее количество CO2, выброшенный страной в этом году
- Coal: количество CO2, выброшенное углем в этом году
- Oil: количество выбросов нефти
- Gas: количество выбросов газа
- Cement: количество выбросов цемента
- Flaring: сжигание на факелах уровни выбросов
- Other: другие формы, такие как промышленные процессы
- Per Capita: столбец «на душу населения»
Какие технологии использовались:
Используемые библиотеки:
- math
- pandas
- sklearn
Как запустить:
- установить python, math, pandas, sklearn
- запустить проект (стартовая точка - main.py)
Что делает программа:
- Загружает набор данных из файла 'CO2.csv', который содержит информацию о выбросах странами CO2 в год от различной промышленной деятельности.
- Очищает набор данных путём удаления строк с нулевыми значениями из набора.
- Добавляет в набор столбец с хеш-кодом наименования страны.
- Добавляет в набор столбец 'procent oil' - процент выбросов от добычи нефтепродуктов от общего объема выбросов страны за год (для возможности классификации).
- Выбирает набор признаков (features) из данных, которые будут использоваться для обучения моделей регрессии и классификации.
- Определяет задачу регрессии, где целевой переменной (task) является 'Total', и задачу классификации, где целевой переменной является 'procent oil'.
- Делит данные на обучающий и тестовый наборы для обеих задач с использованием функции train_test_split. Тестовый набор составляет 1% от исходных данных.
- Создает и обучает деревья решений для регрессии и классификации с использованием моделей DecisionTreeRegressor и DecisionTreeClassifier.
- Предсказывает значения целевой переменной на тестовых наборах для обеих задач.
- Оценивает качество моделей с помощью оценки точности (score) для регрессии и классификации.
- Выводит важности признаков для обеих задач.
Результаты работы программы:
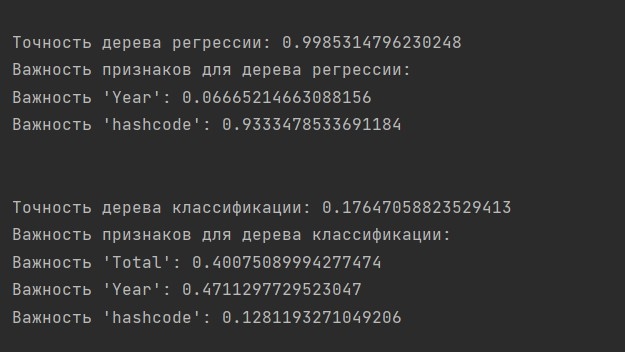
Вывод:
Для задачи регрессии, где целью было предсказание общего объема выбросов СО2 страной за определённый год, модель дерева решений показала оценку точности равную 0.99. Это очень хороший показатель, значит модель вполне приемлемо предсказывает объём выбросов определенной страной в определенный год.
Для задачи классификации, где целью было предсказать какая часть выбросов придётся на добычу нефти, модель дерева решений показала более низкую точность - 18%. Это означает, что модель классификации не справляется с предсказанием доли выбросов от добычи нефтепродуктов на основе выбранных признаков. Низкая точность указывает на необходимость улучшения модели или выбора других методов для решения задачи классификации.
Анализ важности признаков для задачи регрессии показал, что наибольший вклад в предсказание объёма выбросов страной за год вносит признак 'hashcode' или 'Country'. Наименование страны оказывает наибольшее влияние на результаты модели. Из этого можно сделать вывод, что количество выбросов CO2 определённой страной не сильно изменяется с течением времени и каждая страна ежегодно производит примерно одинаковый объём выбросов CO2, что может быть связано с наличием месторождений ископаемых.
Для задачи классификации наибольший вклад в предсказание стоимости жилья вносят признаки 'Year' и 'Total'. Эти признаки имеют наибольшее значение при определении классов по объёму выбросов от добычи нефтепродуктов.