6.2 KiB
Лабораторная работа №3. Вариант 21
Тема:
Деревья решений
Модель:
Decision Tree Classifier
Как запустить программу:
Установить python, numpy, matplotlib, sklearn
python main.py
Какие технологии использовались:
Язык программирования Python, библиотеки numpy, matplotlib, sklearn
Среда разработки VSCode
Что делает лабораторная работа:
Использует данные из набора "UCI Heart Disease Data" и обучает модель: Decision Tree Classifier
Датасет UCI Heart Disease Data содержит информацию о различных клинических признаках, таких как возраст, пол, артериальное давление, холестерин, наличие электрокардиографических признаков и другие, а также целевую переменную, отражающую наличие или отсутствие заболевания сердца.
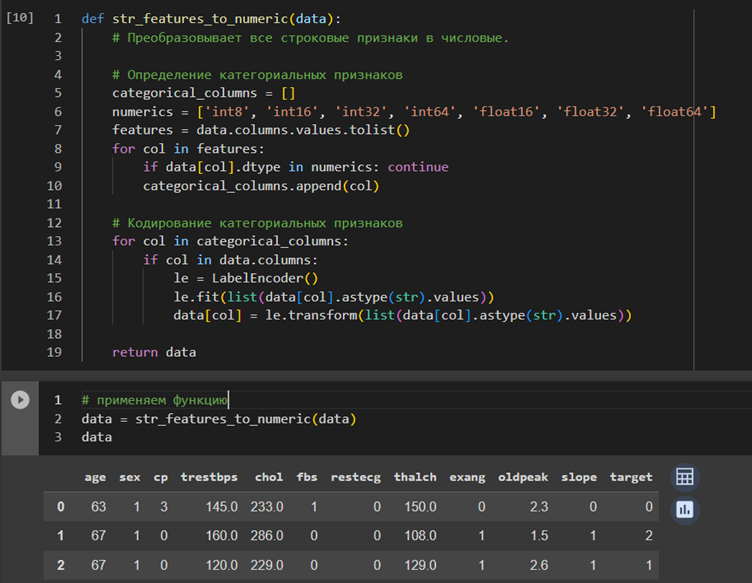
Для начала нужно предобработать данные, чтобы модель могла принимать их на вход. Изначально данный имеют следующий вид:

Так как модели машинного обучения умеют работать исключительно с числовыми значениями, то нужно свести все данных к данному формату и использовать только полные строки, значение признаков которых не являются пустыми значениями. Это происходит с использованием функции, представленной ниже:
Далее нужно привести целевое значение к бинарному виду, т.к изначально данное поле принимает 4 значения. После этого применить подход, называемый “feature engineering”, для получения большего количества признаков, которые возможно помогут модели при решении задачи, т.к. обычно в машинном и глубоком обучении действует следующая логика: Больше данных - лучше результат. Получение новых признаков происходит с помощью функции ниже и далее обновленный набор данных снова преобразовывается к численному формату.
def fe_creation(df):
# Feature engineering (FE)
df['age2'] = df['age']//10
df['trestbps2'] = df['trestbps']//10
df['chol2'] = df['chol']//60
df['thalch2'] = df['thalch']//40
df['oldpeak2'] = df['oldpeak']//0.4
for i in ['sex', 'age2', 'fbs', 'restecg', 'exang']:
for j in ['cp','trestbps2', 'chol2', 'thalch2', 'oldpeak2', 'slope']:
df[i + "_" + j] = df[i].astype('str') + "_" + df[j].astype('str')
return df
После применения данной функции количество признаков увеличилось с 12 до 47. Далее все признаки стандартизируются с помощью следующей формулы z = (x-mean)/std, где х - текущее значение признак, mean - математическое ожидание столбца с этим признаком, std - стандартное отклонение данного признака, а z - соответственно новое значение признака x. После всех описанных действий данные стали готовыми для их использования для обучения деревьев.
Decision Tree Classifier- это алгоритм машинного обучения, который использует структуру дерева для принятия решений. Каждый узел дерева представляет собой тест по какому-то признаку, а каждая ветвь представляет возможный результат этого теста. Цель - разделить данные на подгруппы так, чтобы в каждой подгруппе преобладал один класс.
decision_tree = DecisionTreeClassifier()
param_grid = {'min_samples_leaf': [i for i in range(2,12)]}
decision_tree_CV = GridSearchCV(decision_tree, param_grid=param_grid, cv=cv_train, verbose=False)
decision_tree_CV.fit(train, train_target)
print(decision_tree_CV.best_params_)
acc_all = acc_metrics_calc(0, acc_all, decision_tree_CV, train, valid, train_target, valid_target, title="Decision Tree Classifier")
plot_learning_curve(decision_tree_CV, "Decision Tree", train, train_target, cv=cv_train)
feature_importances_dt = decision_tree_CV.best_estimator_.feature_importances_
plot_feature_importance(feature_importances_dt, data.columns, "Decision Tree")
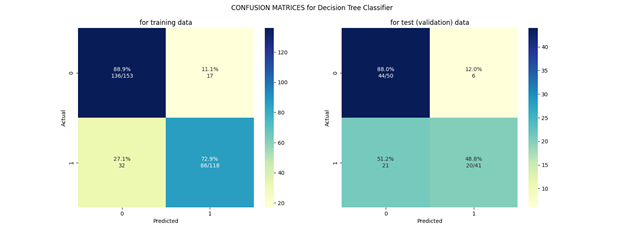
Первым был обучен Decision Tree Classifier, который с помощью алгоритма GridSearch нашел наилучшие гиперпараметры для решения задачи. Ниже приведены графики, отображающие качество и процесс обучения данного классификатора.
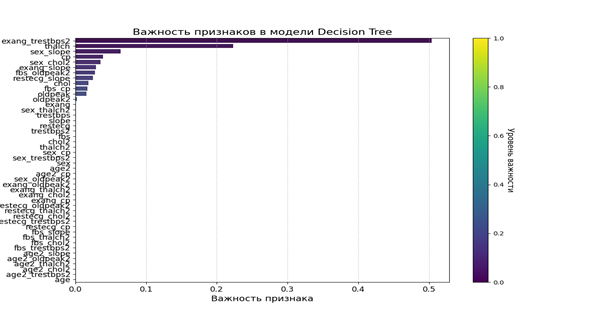
На следующем графике мы можем увидеть какие признаки модель посчитала наиболее важными:
Вывод
На обучающихся данных мы в большинстве случаев предсказываем правильно, а в валидационных появляется проблема с выявлением второго класса, которое отображает наличие заболеваний.