5.9 KiB
Лабораторная работа №5. Регрессия
12 вариант
Задание:
Использовать регрессию по варианту для своих данных по варианту, самостоятельно сформулировав задачу. Оценить, насколько хорошо она подходит для решения сформулированной вами задачи.
Вариант:
- Модель нейронной сети: MLPRegressor
Вариант набора данных по курсовой работе:
- Прогнозирование музыкальных жанров ("Prediction of music genre")
Запуск
- Запустить файл lab6.py
Используемые технологии
- Язык программирования Python
- Среда разработки PyCharm
- Библиотеки:
- pandas
- sklearn
- matplotlib
Описание программы
Набор данных (Kaggle): Полный список жанров, включенных в CSV: «Электронная музыка», «Аниме», «Джаз», «Альтернатива», «Кантри», «Рэп», «Блюз», «Рок», «Классика», «Хип-хоп».
Задача, решаемая нейронной сетью: Предсказание популярности нового музыкального трека на основе его определённых характеристик.
Задача оценки: Анализ с помощью коэффициента детерминации и потери регрессии среднеквадратичной логарифмической ошибке, плюсом к ним график сравнения реальных и предсказанных значений.
Пример работы
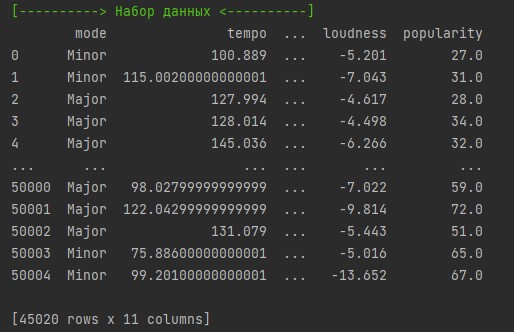
Датасет, сформированный из случайных строк csv-файла.
Коэффициент детерминации используется для оценки эффективности модели линейной регрессии. Он показывает, насколько хорошо наблюдаемые результаты воспроизводятся моделью, в зависимости от соотношения суммарных отклонений результатов, описываемых моделью. По выводу можно отметить, что 33,4% изменчивости зависимого выходного атрибута можно объяснить с помощью модели, в то время как остальные 66,6% изменчивости все ещё не учтены.
Потери регрессии среднеквадратичной логарифмической ошибки (MSLE) использует тот же подход, что и MSE, но использует логарифм для компенсации больших выбросов в наборе данных и обрабатывает их так, как если бы они были в одном масштабе. Это наиболее ценно в стремлении к сбалансированной модели с одинаковым процентом ошибок.

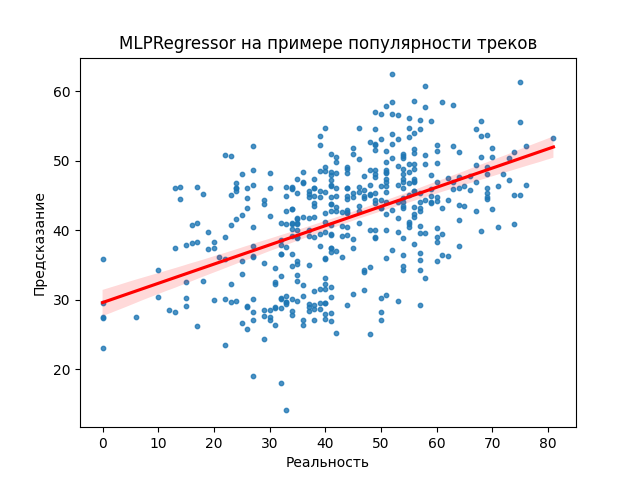
График нейронной сети MLPRegressor, показывающий сравнение реальных (ось абсцисс) и предсказанных (ось ординат) данных.
Вывод
Итак, нейронная сеть с поставленной задачей по сути не справилась. Работа со скрытыми слоями смогла улучшить результат, но лишь на значение, равное 0,100.
Использование слишком малого количества нейронов в скрытых слоях приведет к недообучению. Недообучение происходит, когда в скрытых слоях слишком мало нейронов для адекватного обнаружения сигналов в сложном наборе данных. Использование же слишком большого количества нейронов в скрытых слоях может привести к переобучению. Очевидно, должен быть достигнут некоторый компромисс между слишком большим и слишком малым количеством нейронов в скрытых слоях. Я пришёл к тому, что использовал 4 скрытых слоя с 50 нейронов в каждом.
Можно сделать заключение, что целевая переменная (процент популярности музыкального трека) выбрана неудачно, либо же требуется более детальная обработка данных и другой подход к оцениваемым признакам. Как вариант, можно рассмотреть StandardScaler или MinMaxScaler на этапе предварительной обработки данных. Но как упоминалось в прошлой лабораторной работе, популярность музыкального трека слишком неоднозначная величина, которую саму по себе предсказать не просто, так как нет точной формулы песни, которая взлетит в чартах. Искусство само по себе коварное :)