6.2 KiB
IIS_2023_1
Задание
Использовать нейронную сеть (четные варианты –MLPRegressor, нечетные –MLPClassifier) для данных из таблицы 1 по варианту, самостоятельно сформулировав задачу. Интерпретировать результаты и оценить, насколько хорошо она подходит для решения сформулированной вами задачи.
29 Вариант. MLPClassifier.
Способ запуска лабораторной работы
Выполнить скрипт shadaev_anton_lab_6/main.py, после которого результат будет выведен в консоль.
Стек технологий
Python: v. 3.11Pandas- библиотека, которая позволяет работать с двумерными и многомерными таблицами, строить сводные таблицы, выделять колонки, использовать фильтры по параметрам, выполнять группировку по параметрам, запускать функции (сложение, нахождение медианы, среднего, минимального, максимального значений), объединять таблицы и многое другоеSklearn- библиотека, которая предоставляет ряд инструментов для моделирования данных, включая классификацию, регрессию, кластеризацию и уменьшение размерности.
Описание кода
-
Загрузка данных - Сначала загружаются данные из файла
'stroke_prediction_ds.csv'с помощью функцииpd.read_csv(). -
Выделение признаков и целевой переменной - Затем выбираются признаки
'hypertension','heart_disease'и'avg_glucose_level'в качестве входных данных, а'age'выбирается в качестве целевой переменной. -
Определение категорий для целевой переменной - Целевая переменная
'age'делится на категории с помощью функции'pd.qcut()'. Это делается для преобразования непрерывной переменной в категориальную. -
Разделение данных на обучающий и тестовый наборы - Данные затем разделяются на обучающий и тестовый наборы с использованием функции
train_test_split(). -
Нормализация данных - Нормализация данных выполняется с помощью класса
MinMaxScalerиз библиотекиsklearn. Это делается для того, чтобы все признаки были в одном масштабе, что может улучшить производительность модели. -
Обучение модели - Далее создается и обучается модель
MLPClassifier(многослойный перцептрон), которая применяется для классификации данных. -
Предсказание на тестовых данных - После обучения модели производятся предсказания на тестовых данных.
-
Оценка производительности модели - После предсказания модели оценивается с помощью метрик точности (
accuracy_score) и отчета классификации (classification_report). -
Вывод результатов - Наконец, результаты оценок модели выводятся на экран.
Результат:
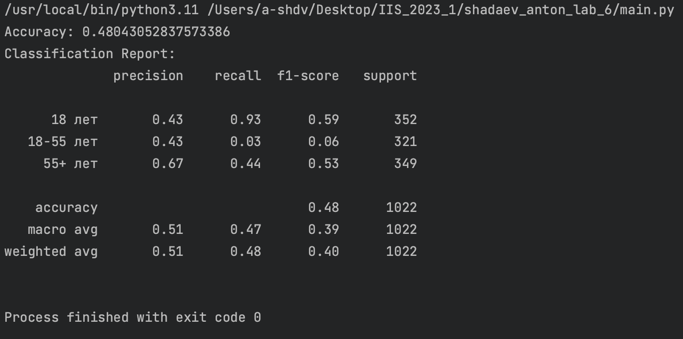
Вывод
- Точность (Accuracy) - это общая метрика, которая измеряет долю правильных прогнозов от общего количества прогнозов - в моем случае составляет ~0.48, что означает, что модель правильно предсказала 48% случаев
- Точность (Precision) - это доля правильных прогнозов среди всех прогнозов, сделанных моделью - в моем случае, например, точность для класса "18 лет" составляет 0.43, что означает, что из всех случаев, когда модель предсказывала "18 лет", на самом деле было "18 лет" в 43% случаев.
- Полнота (Recall) - это доля правильных прогнозов среди всех фактических положительных случаев - в моем случае, например, полнота для класса "18 лет" составляет 0.93, что означает, что из всех фактических случаев "18 лет", модель правильно предсказала в 93% случаях.
- F1-score - это среднее гармоническое точности и полноты, и оно дает общее представление о том, насколько хорошо модель работает на данном классе - в моем случае, например, F1-score для класса "18 лет" составляет 0.59.
- Поддержка (Support) - это количество наблюдений в каждом классе - в моем случае, например, поддержка для класса "18 лет" составляет 352.
Общая точность составляет 0.48, что указывает на то, что модель в целом работает не очень хорошо.