5.1 KiB
5.1 KiB
IIS_2023_1
Задание
Используя код из пункта «Регуляризация и сеть прямого распространения» из [1] (стр. 228), сгенерируйте определенный тип данных и сравните на нем 3 модели (по варианту). Постройте графики, отобразите качество моделей, объясните полученные результаты.
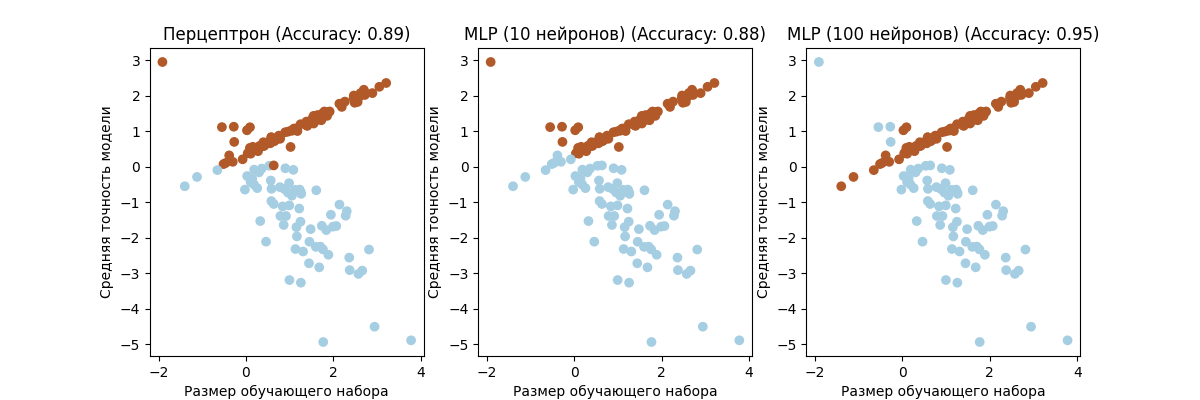
9. Данные: make_classification (n_samples=500, n_features=2, n_redundant=0, n_informative=2, random_state=rs, n_clusters_per_class=1) Модели: - Персептрон · Многослойный персептрон с 10-ю нейронами в скрытом слое (alpha = 0.01) · Многослойный персептрон со 100-а нейронами в скрытом слое (alpha = 0.01)
Способок запуска программы
Выполнить скрипт shadaev_anton_lab_1/main.py (перед этим установить импортированные библиотеки) после которого будут нарисованы 3 графика
Стек технологий
- NumPy - это библиотека Python, предоставляющая поддержку для больших, многомерных массивов и матриц, а также набор функций для их манипуляции и обработки.
- Matplotlib - это библиотека для визуализации данных в Python, предоставляющая инструменты для создания статических, анимированных и интерактивных графиков и диаграмм.
- Scikit-learn - это библиотека Python, предназначенная для машинного обучения, которая содержит функции и алгоритмы для классификации, прогнозирования и разбиения данных на группы.
Описание кода
- Импортирование необходимых библиотек
- Создание искусственных данных с помощью функции make_classification() из sklearn. Данные состоят из 500 образцов.
- Данные разделяются на обучающие и тестовые наборы данных с использованием функции train_test_split().
- Создается список моделей для обучения (Перцептрон и многослойные перцептроны).
- Выполняется обучение для каждой модели, предсказание на тестовых данных и вычисление точности предсказания.
- Строится кривая обучения для каждой модели и кросс-валидации с использованием функции learning_curve() из sklearn. Данная функция позволяет визуализировать, как производительность модели изменяется в зависимости от количества обучающих примеров.
- Наконец, plt.show() отображает все графики.
Полученные графики
Графики показывают производительность моделей при обучении на разных размерах обучающего набора данных.- Оценка обучения - кривая, показывающая среднюю точность модели на обучающем наборе данных для различных размеров обучающего набора. Это позволяет увидеть, как точность модели меняется с увеличением размера обучающего набора.
- Оценка кросс-валидации - кривая, показывающая среднюю точность модели на валидационном наборе данных для различных размеров обучающего набора. Это позволяет увидеть, как точность модели меняется с увеличением размера обучающего набора, но с использованием кросс-валидации для оценки производительности модели.
- Оси графика: Ось X представляет размер обучающего набора, а ось Y представляет среднюю точность модели.