3.1 KiB
Вариант 2
Задание: Используя код из [1](пункт «Решение задачи ранжирования признаков», стр. 205), выполните ранжирование признаков с помощью указанных по варианту моделей. Отобразите получившиеся значения\оценки каждого признака каждым методом\моделью и среднюю оценку. Проведите анализ получившихся результатов. Какие четыре признака оказались самыми важными по среднему значению? (Названия\индексы признаков и будут ответом на задание).
Данные: Линейная регрессия (LinearRegression) Рекурсивное сокращение признаков (Recursive Feature Elimination –RFE) Сокращение признаков Случайными деревьями (Random Forest Regressor)
Запуск: Запустите файл lab2.py
Описание программы:
- Генерирует случайные данные для задачи регрессии с помощью функции make_regression, создавая матрицу признаков X и вектор целевой переменной y.
- Создает DataFrame data, в котором столбцы представляют признаки, а последний столбец - целевую переменную.
- Разделяет данные на матрицу признаков X и вектор целевой переменной y.
- Создает список моделей для ранжирования признаков: линейной регрессии, рекурсивного сокращения признаков и сокращения признаков случайными деревьями.
- Создает словарь model_scores для хранения оценок каждой модели.
- Обучает и оценивает каждую модель на данных:
- Вычисляет ранги признаков и нормализует их в диапазоне от 0 до 1.
- Выводит оценки признаков каждой модели и их средние оценки.
- Находит четыре наиболее важных признака по средней оценке и выводит их индексы и значения.
Результаты:
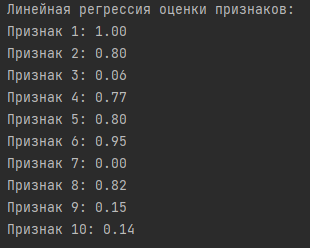
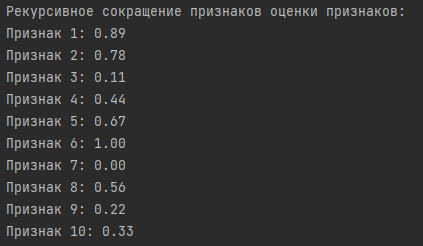
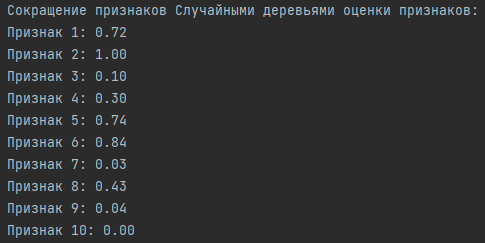
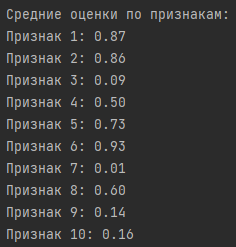
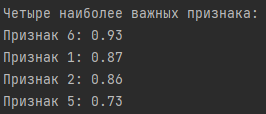
Выводы:
Четыре наиболее важных признака, определенных на основе средних оценок, включают Признак 6, Признак 1, Признак 2 и Признак 5. Эти признаки имеют наибольшую среднюю важность среди всех признаков.