mashkova_margarita_lab_7 ready #217
BIN
mashkova_margarita_lab_7/1lstm50ep.png
Normal file
BIN
mashkova_margarita_lab_7/1lstm50ep.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 25 KiB |
BIN
mashkova_margarita_lab_7/1lstm50ep_eng.png
Normal file
BIN
mashkova_margarita_lab_7/1lstm50ep_eng.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 21 KiB |
BIN
mashkova_margarita_lab_7/2lstm100ep.png
Normal file
BIN
mashkova_margarita_lab_7/2lstm100ep.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 24 KiB |
BIN
mashkova_margarita_lab_7/2lstm100ep_eng.png
Normal file
BIN
mashkova_margarita_lab_7/2lstm100ep_eng.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 24 KiB |
BIN
mashkova_margarita_lab_7/2lstm500ep.png
Normal file
BIN
mashkova_margarita_lab_7/2lstm500ep.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 26 KiB |
BIN
mashkova_margarita_lab_7/2lstm500ep_eng.png
Normal file
BIN
mashkova_margarita_lab_7/2lstm500ep_eng.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 23 KiB |
BIN
mashkova_margarita_lab_7/2lstm50ep_eng.png
Normal file
BIN
mashkova_margarita_lab_7/2lstm50ep_eng.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 25 KiB |
BIN
mashkova_margarita_lab_7/2lstm50ep_v1.png
Normal file
BIN
mashkova_margarita_lab_7/2lstm50ep_v1.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 26 KiB |
BIN
mashkova_margarita_lab_7/2lstm50ep_v2.png
Normal file
BIN
mashkova_margarita_lab_7/2lstm50ep_v2.png
Normal file
Binary file not shown.
|
After 
(image error) Size: 27 KiB |
95
mashkova_margarita_lab_7/README.md
Normal file
95
mashkova_margarita_lab_7/README.md
Normal file
@ -0,0 +1,95 @@
|
||||
# Лабораторная работа №6
|
||||
## ПИбд-42 Машкова Маргарита (Вариант 19)
|
||||
## Задание
|
||||
|
||||
Выбрать англоязычный и русскоязычный художественные тексты и обучить на нем рекуррентную нейронную сеть для решения задачи генерации.
|
||||
Подобрать архитектуру и параметры так, чтобы приблизиться к максимально осмысленному результату.
|
||||
|
||||
### Данные:
|
||||
|
||||
Художественные тексты в файлах `english_text.txt` и `russian_text.txt`.
|
||||
|
||||
## Запуск программы
|
||||
Для запуска программы необходимо запустить файл main.py
|
||||
|
||||
## Используемые технологии
|
||||
> **Язык программирования:** python
|
||||
>
|
||||
> **Библиотеки:**
|
||||
> - `keras` - библиотека для глубокого обучения. Она предоставляет простой и интуитивно понятный интерфейс для создания
|
||||
и обучения различных моделей машинного обучения, включая нейронные сети.
|
||||
> - `numpy` - предоставляет мощные инструменты для работы с многомерными массивами и выполнения математических операций над ними.
|
||||
|
||||
## Описание работы программы
|
||||
|
||||
Т.к. нейронная сеть принимает на вход числа, необходимо закодировать исходные тексты.
|
||||
Сделать это можно с помощью Tokenizer. Метод `fit_on_texts()` создает словарь вида (слово - индекс)
|
||||
на основе частоты использования слов. Чем меньше индекс, тем чаще встречается слово.
|
||||
Метод `texts_to_sequences()` преобразовывает текст в последовательность чисел.
|
||||
Таким образом каждое слово принимает целочисленное значение.
|
||||
|
||||

|
||||
|
||||
Затем создаются входные и выходные последовательности, инициализируется, настраивается и компилируется модель.
|
||||
Модель обучается на данных и генерирует текст на основе начальной фразы.
|
||||
|
||||
## Тесты
|
||||
|
||||
### Варьирование количества слоев и эпох обучения для русскоязычного текста:
|
||||
|
||||
1 слой и 50 эпох обучения:
|
||||

|
||||
Присутствуют осмысленные словосочетания, например, `преобразившейся природе`, `бодрящей свежести`,
|
||||
`ветерок поднимающийся изредка пощипывает лицо уши` (хоть это должен быть и морозец, но все же)
|
||||
|
||||
2 слоя и 50 эпох обучения (1 вариант):
|
||||

|
||||
Присутствуют осмысленные словосочетания, например, `снежинки кружатся`, `наполняет чувством`,
|
||||
`в воздухе кружатся`, `невольно наполняет`, `морозец он колюч приятен`
|
||||
|
||||
2 слоя и 50 эпох обучения (2 вариант):
|
||||

|
||||
Помимо некоторых осмысленных словосочетаний, если исключить повторы слов, можно прочесть вполне осмысленную фразу:
|
||||
`невольно улыбаешься, хочется сказать дружески этому зимнему утру "здравствуй зима"`
|
||||
|
||||
2 слоя и 100 эпох обучения:
|
||||

|
||||
В данном случае присутствуют осмысленные словосочетания, и при этом эпитеты стоят рядом с нужными существительными
|
||||
(подходящим по тематике),
|
||||
т.е., например, снежинки - `мягкие`, `нежные`, `кружатся`, морозец - `колюч`, магазины - `окна`,
|
||||
солнце - `переливается слепящим блеском` и т.д.
|
||||
|
||||
2 слоя и 500 эпох обучения:
|
||||

|
||||
Увеличение количества эпох снизило качество генерации текста.
|
||||
|
||||
### Варьирование количества слоев и эпох обучения для англоязычного текста:
|
||||
|
||||
1 слой и 50 эпох обучения:
|
||||

|
||||
|
||||
2 слоя и 50 эпох обучения:
|
||||

|
||||
|
||||
2 слоя и 100 эпох обучения:
|
||||

|
||||
|
||||
2 слоя и 500 эпох обучения:
|
||||

|
||||
|
||||
В данном случае видно, что увеличение количество слоев и эпох положительно влияет на генерацию текста.
|
||||
|
||||
**Вывод:** т.к. кодировались в числа не буквы, а слово, для оценки работы модели нужно обращать внимание
|
||||
на осмысленность условных предложений, а не самих слов. Увелечение количества слоев привело к более хорошему результату
|
||||
для обоих текстов.
|
||||
|
||||
Для русскоязычного текста увеличение количества эпох обучения не сильно улучшает результат, а иногда даже ухудшает.
|
||||
Скорее всего, потому что данных не так много и они разнообразные, и размер потерь не сильно уменьшается в каждой
|
||||
эпохе обучения.
|
||||
|
||||
Для англоязычного текста увеличение количества эпох привело к сильному улучшению результата
|
||||
(как минимум, сократились повторения одних и тех же слов подряд).
|
||||
Скорее всего, потому что частота встречаемости слов, таких как, например, `gingerbread`, `cookies`, слишком большая,
|
||||
и поэтому малообученная модель их часто использует.
|
||||
|
||||
Для русскоязычного текста генерация текста выполнилась сильно лучше, чем для англоязычного.
|
||||
1
mashkova_margarita_lab_7/english_text.txt
Normal file
1
mashkova_margarita_lab_7/english_text.txt
Normal file
@ -0,0 +1 @@
|
||||
Once upon a time there was an old woman who loved baking gingerbread. She would bake gingerbread cookies, cakes, houses and gingerbread people, all decorated with chocolate and peppermint, caramel candies and coloured frosting. She lived with her husband on a farm at the edge of town. The sweet spicy smell of gingerbread brought children skipping and running to see what would be offered that day. Unfortunately the children gobbled up the treats so fast that the old woman had a hard time keeping her supply of flour and spices to continue making the batches of gingerbread. Sometimes she suspected little hands of having reached through her kitchen window because gingerbread pieces and cookies would disappear. One time a whole gingerbread house vanished mysteriously.
|
||||
80
mashkova_margarita_lab_7/main.py
Normal file
80
mashkova_margarita_lab_7/main.py
Normal file
@ -0,0 +1,80 @@
|
||||
import numpy as np
|
||||
from keras.models import Sequential
|
||||
from keras.layers import LSTM, Dense, Embedding
|
||||
from keras.preprocessing.text import Tokenizer
|
||||
from keras.preprocessing.sequence import pad_sequences
|
||||
|
||||
|
||||
# filename = "russian_text.txt"
|
||||
filename = "english_text.txt"
|
||||
# Чтение текста из файла
|
||||
with open(filename, "r", encoding="utf-8") as f:
|
||||
text = f.read()
|
||||
|
||||
# Создание токенизатора
|
||||
tokenizer = Tokenizer()
|
||||
# Создает словарь вида (слово - индекс) на основе частоты использования слов
|
||||
# чем меньше индекс, тем чаще встречается слово
|
||||
# т.е. каждое слово принимает целочисленное значение
|
||||
tokenizer.fit_on_texts([text])
|
||||
|
||||
# print("Словарь:")
|
||||
# print(tokenizer.word_index)
|
||||
|
||||
# Преобразование текста в последовательность чисел
|
||||
sequences = tokenizer.texts_to_sequences([text])[0]
|
||||
vocab_size = len(tokenizer.word_index) + 1
|
||||
# print("\nЗакодированный текст:")
|
||||
# print(sequences)
|
||||
|
||||
# Длина входных последовательностей
|
||||
seq_length = 5
|
||||
|
||||
# Создание входных и выходных последовательностей
|
||||
X_data = []
|
||||
y_data = []
|
||||
for i in range(seq_length, len(sequences)):
|
||||
sequence = sequences[i - seq_length:i]
|
||||
target = sequences[i]
|
||||
X_data.append(sequence)
|
||||
y_data.append(target)
|
||||
|
||||
X = np.array(X_data)
|
||||
y = np.array(y_data)
|
||||
|
||||
# Создание модели
|
||||
model = Sequential()
|
||||
model.add(Embedding(input_dim=vocab_size, output_dim=128, input_length=seq_length))
|
||||
model.add(LSTM(256, return_sequences=True))
|
||||
model.add(LSTM(256))
|
||||
model.add(Dense(vocab_size, activation='softmax'))
|
||||
|
||||
# Компиляция модели
|
||||
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
|
||||
|
||||
# Обучение модели
|
||||
model.fit(X, y, epochs=500, batch_size=64, verbose=1)
|
||||
|
||||
# Начальная фраза для генерации
|
||||
seed_text = "an old woman"
|
||||
# Длина генерируемого текста
|
||||
gen_length = 100
|
||||
|
||||
|
||||
# Функция для генерации текста
|
||||
def generate_text(seed_text, gen_length):
|
||||
generated_text = seed_text
|
||||
for _ in range(gen_length):
|
||||
sequence = tokenizer.texts_to_sequences([seed_text])[0]
|
||||
sequence = pad_sequences([sequence], maxlen=seq_length)
|
||||
prediction = model.predict(sequence, verbose=0)
|
||||
predicted_index = np.argmax(prediction)
|
||||
predicted_word = [word for word, index in tokenizer.word_index.items() if index == predicted_index][0]
|
||||
generated_text += " " + predicted_word
|
||||
seed_text += " " + predicted_word
|
||||
return generated_text
|
||||
|
||||
|
||||
# Генерация текста
|
||||
generated_text = generate_text(seed_text, gen_length)
|
||||
print(generated_text)
|
||||
1
mashkova_margarita_lab_7/russian_text.txt
Normal file
1
mashkova_margarita_lab_7/russian_text.txt
Normal file
@ -0,0 +1 @@
|
||||
Итак, она пришла, долгожданная зима! Хорошо пробежаться по морозцу в первое зимнее утро! Улицы, вчера еще по-осеннему унылые, сплошь покрыты белым снегом, и солнце переливается в нем слепяшим блеском. Причудливый узор мороза лег на витрины магазинов и наглухо закрытые окна домов, иней покрыл ветви тополей. Глянешь ли вдоль улицы, вытянувшейся ровной лентой, вблизи ли вокруг себя посмотришь, везде все то же: снег, снег, снег. Изредка подымающийся ветерок пощипывает лицо и уши, зато как красиво все вокруг! Какие нежные, мягкие снежинки плавно кружатся в воздухе. Как ни колюч морозец, он тоже приятен. Не за то ли все мы любим зиму, что она так же, как весна, наполняет грудь волнующим чувством. Все живо, все ярко в преобразившейся природе, все полно бодрящей свежести. Так легко дышится и так хорошо на душе, что невольно улыбаешься и хочется сказать дружески этому чудному зимнему утру: «Здравствуй, зима!»
|
||||
BIN
mashkova_margarita_lab_7/tokenize.png
Normal file
BIN
mashkova_margarita_lab_7/tokenize.png
Normal file
Binary file not shown.
|
After 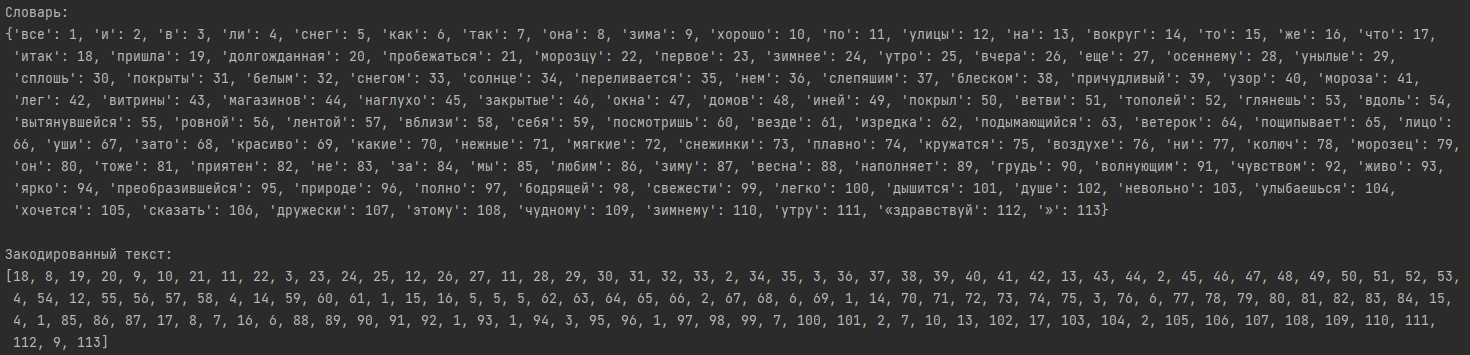
(image error) Size: 78 KiB |
Loading…
x
Reference in New Issue
Block a user