30 KiB
30 KiB
Загрузка данных в DataFrame
In [1]:
import pandas as pd
df = pd.read_csv("data/titanic.csv", index_col="PassengerId")
df.info()
display(df.shape)
df.head()
Out[1]:
Получение сведений о пропущенных данных
Типы пропущенных данных:
- None - представление пустых данных в Python
- NaN - представление пустых данных в Pandas
- '' - пустая строка
In [2]:
# Количество пустых значений признаков
display(df.isnull().sum())
display()
# Есть ли пустые значения признаков
display(df.isnull().any())
display()
# Процент пустых значений признаков
for i in df.columns:
null_rate = df[i].isnull().sum() / len(df) * 100
if null_rate > 0:
display(f"{i} процент пустых значений: %{null_rate:.2f}")
In [3]:
fillna_df = df.fillna(0)
display(fillna_df.shape)
display(fillna_df.isnull().any())
# Замена пустых данных на 0
df["AgeFillNA"] = df["Age"].fillna(0)
# Замена пустых данных на медиану
df["AgeFillMedian"] = df["Age"].fillna(df["Age"].median())
df.tail()
Out[3]:
In [4]:
df["AgeCopy"] = df["Age"]
# Замена данных сразу в DataFrame без копирования
df.fillna({"AgeCopy": 0}, inplace=True)
df.tail()
Out[4]:
Удаление наблюдений с пропусками
In [5]:
dropna_df = df.dropna()
display(dropna_df.shape)
display(fillna_df.isnull().any())
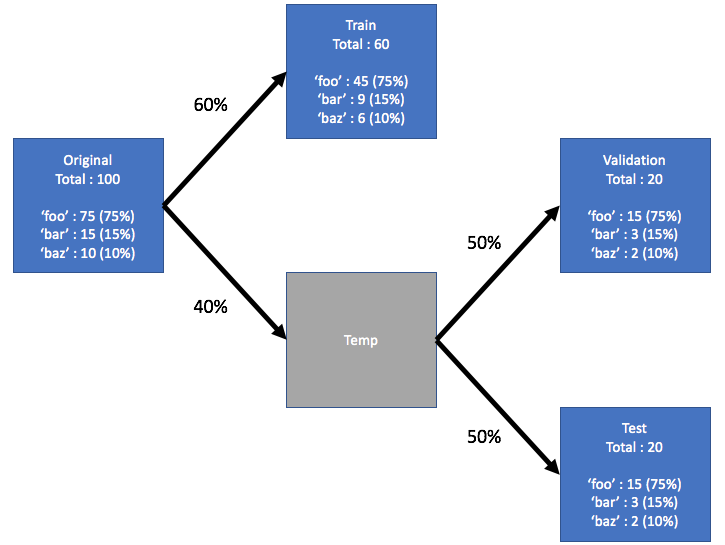
In [6]:
# Вывод распределения количества наблюдений по меткам (классам)
from src.utils import split_stratified_into_train_val_test
display(df.Pclass.value_counts())
display()
data = df[["Pclass", "Survived", "AgeFillMedian"]].copy()
df_train, df_val, df_test, y_train, y_val, y_test = split_stratified_into_train_val_test(
data, stratify_colname="Pclass", frac_train=0.60, frac_val=0.20, frac_test=0.20
)
display("Обучающая выборка: ", df_train.shape)
display(df_train.Pclass.value_counts())
display("Контрольная выборка: ", df_val.shape)
display(df_val.Pclass.value_counts())
display("Тестовая выборка: ", df_test.shape)
display(df_test.Pclass.value_counts())
Выборка с избытком (oversampling)
https://www.blog.trainindata.com/oversampling-techniques-for-imbalanced-data/
https://datacrayon.com/machine-learning/class-imbalance-and-oversampling/
Выборка с недостатком (undersampling)
Библиотека imbalanced-learn
In [1]:
from imblearn.over_sampling import ADASYN
ada = ADASYN()
display("Обучающая выборка: ", df_train.shape)
display(df_train.Pclass.value_counts())
X_resampled, y_resampled = ada.fit_resample(df_train, df_train["Pclass"]) # type: ignore
df_train_adasyn = pd.DataFrame(X_resampled)
display("Обучающая выборка после oversampling: ", df_train_adasyn.shape)
display(df_train_adasyn.Pclass.value_counts())
df_train_adasyn