Отчет по лабораторной работе №5
Выполнила студентка гр. ИСЭбд-41 Плаксина А.В.
Описание работы приложения
Приложение реализовнао на языке питон, использована среда PyCharm для разработки. Было развернуто два приложения:
- Веб приложение для умножения матриц
- Консольное приложение для бенчмаркинга
Последовательно запускаем две программы: сначала simple_app.py, затем benchmark.py. Веб - приложение позволяет указать размеры матрицы и используемый алгоритм, и на основании этого получить результат перемножения матриц в интерактивном режиме
Развернули два приложения
- Приложение 1 - веб приложение для умножения матриц
- Приложение 2 - консольное приложение для сравнения эффективности работы алгоритмов.
Первое приложение дает нам возможность умножить матрицы, получить результат в интерактивном режиме с указанием используемого алгоритма и с указанием размера матрицы.
При запуске веб приложения с выбором последовательного умножения:

Результат последовательного умножения:

Код реализующий последовательное умножение матриц:
def multiply_matrices(matrix_a, matrix_b):
if len(matrix_a[0]) != len(matrix_b):
raise ValueError("матрицы имеют разную длину")
result = [[0 for _ in range(len(matrix_b[0]))] for _ in range(len(matrix_a))]
for i in range(len(matrix_a)):
for j in range(len(matrix_b[0])):
for k in range(len(matrix_b)):
result[i][j] += matrix_a[i][k] * matrix_b[k][j]
return result
При запуске веб приложения с выбором параллельного умножения:

Результат параллельного умножения:

Код реализующий параллельное умножение матриц:
def multiply_matrices_parallel(matrix_a, matrix_b, threads):
if len(matrix_a[0]) != len(matrix_b):
raise ValueError("матрицы имеют разную длину")
result = [[0 for _ in range(len(matrix_b[0]))] for _ in range(len(matrix_a))]
with multiprocessing.Pool(processes=threads) as pool:
args_list = [(matrix_a, matrix_b, i) for i in range(len(matrix_a))]
rows_results = pool.map(multiply_row, args_list)
for row_result, row_index in rows_results:
result[row_index] = row_result
return result
Бенчмаркинг
Для сравнения времени работы двух алгоритмов умножения, проведем несколько бенчмарков
Для матриц размерностью 100x100, 300x300, 500x500, для параллельного алгоритма дополнительно для каждого введенного количества потоков (4, 16, 32)
Результаты бенчмаркинга для последовательного способа матриц различной размерности:

Результаты бенчмаркинга для параллельного способа матриц различной размерности с количеством потоков равном 4:
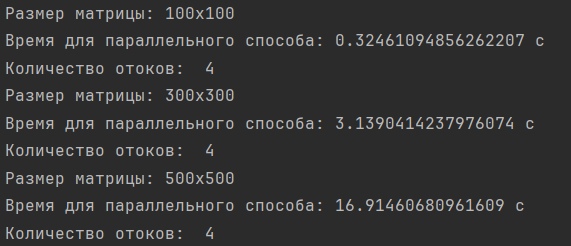
Результаты бенчмаркинга для параллельного способа матриц различной размерности с количеством потоков равном 16:
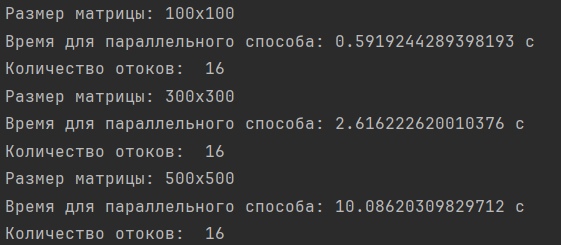
Результаты бенчмаркинга для параллельного способа матриц различной размерности с количеством потоков равном 32:
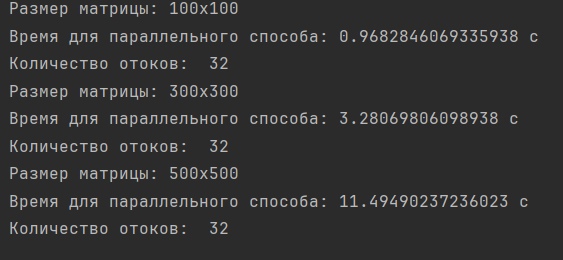
Вывод
С использованием параллельного алгоритма скорость обработки существенно увеличивается, особенно при большой размерности матрицы. В данном примере оптимальная скорость достигается при количестве потоков равном 16.