forked from Alexey/DAS_2024_1
Отчет по лабораторной работе №5
Описание задачи
В лабораторной работе необходимо реализовать два алгоритма для умножения квадратных матриц: последовательный и параллельный. Параллельный алгоритм должен поддерживать настройку количества потоков, что позволит гибко распределять нагрузку. Бенчмарки проводились на матрицах размером 100x100, 300x300 и 500x500 для анализа производительности каждого алгоритма.
Структура проекта
Проект состоит из двух файлов с реализацией алгоритмов:
- regular.go — реализация последовательного умножения матриц.
- parallel.go — реализация параллельного умножения матриц с заданным количеством потоков.
- matrix.go (в папке util) — вспомогательные функции для создания матриц.
Результаты
Последовательное умножение
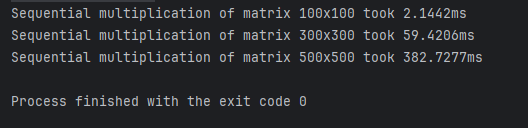
| Размер матрицы | Время выполнения |
|---|---|
| 100x100 | 2.1442ms |
| 300x300 | 59.4206ms |
| 500x500 | 382.7277ms |
Параллельное умножение
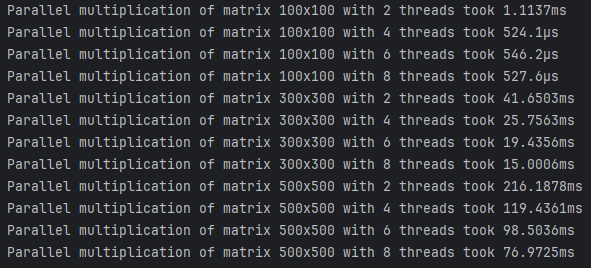
| Размер матрицы | Количество потоков | Время выполнения |
|---|---|---|
| 100x100 | 2 | 1.1137ms |
| 100x100 | 4 | 524.1µs |
| 100x100 | 6 | 546.2µs |
| 100x100 | 8 | 527.6µs |
| 300x300 | 2 | 41.6503ms |
| 300x300 | 4 | 25.7563ms |
| 300x300 | 6 | 19.4356ms |
| 300x300 | 8 | 15.0006ms |
| 500x500 | 2 | 216.1878ms |
| 500x500 | 4 | 119.4361ms |
| 500x500 | 6 | 98.5036ms |
| 500x500 | 8 | 76.9725ms |
Анализ полученных данных
- Последовательное умножение:
- Время выполнения линейно увеличивается с ростом размера матрицы. Это связано с тем, что алгоритм работает с комплексностью O(n³), где n — размер матрицы.
- Для больших матриц (500x500) время выполнения становится заметно больше, что подчеркивает ограниченность этого метода при работе с большими объемами данных.
- Параллельное умножение:
- Параллельный алгоритм показал значительное улучшение времени выполнения по сравнению с последовательным, особенно при увеличении количества потоков.
- Например, для матриц 100x100 время выполнения снизилось с 1.6ms до 524.1µs при использовании 4 потоков.
- Для матриц большего размера (500x500) прирост производительности также существенный: с 393.65ms (последовательное умножение) до 76.97ms при 8 потоках.
- Однако, начиная с 6 потоков, улучшения становятся менее значительными. Это связано с накладными расходами на синхронизацию потоков и передачу данных между ними. При небольших размерах матриц такие накладные расходы могут нивелировать прирост производительности.
- Заключение:
- Параллельный алгоритм значительно превосходит последовательный при увеличении размера матриц и количества потоков. Однако для небольших матриц с увеличением количества потоков, прирост производительности не всегда оправдан из-за накладных расходов на управление потоками.
- Оптимальное количество потоков зависит от размера матриц: для небольших матриц 4 потока дают значительное улучшение, а для матриц большего размера (500x500) лучше использовать 8 потоков для максимальной эффективности.
Демонстрационное видео
Видеозапись доступна по адресу: https://vk.com/video193898050_456240873