| .. | ||
| accuracy.png | ||
| classificationReport.png | ||
| Current_Pub_Meta.csv | ||
| main.py | ||
| positions.png | ||
| README.md | ||
{kind=link}
{kind=link}
{kind=link}
Задание
Использовать нейронную сеть MLPClassifier для данных из таблицы 1 по
варианту, самостоятельно сформулировав задачу. Интерпретировать результаты и оценить, насколько хорошо она подходит для решения сформулированной вами задачи
Как запустить лабораторную
Запустить файл main.py
Используемые технологии
Библиотеки pandas, scikit-learn, их компоненты
Описание лабораторной (программы)
Данный код берет данные из датасета о персонажах Dota 2, где описаны атрибуты персонажей, их роли, название, и как часто их пикают и какой у них винрейт на каждом звании в Доте, от реркута до титана.
В моем случае была поставлена задача понять, можно ли определить позицию персонажа (всего в игре есть 5 позиций - carry, mid, offlane, support, full support), по его главному атрибуту и по тому, какие роли он выполняет в игре. Учитывая то, что Dota 2 имеет 124 персонажа, все они очень разные, поэтому была вероятность, что модель не установит зависимость и не будет работать в принципе. Именно поэтому я посчитала данную задачу довольно интересной. В моем датасете присутствует информация о главном атрибуте персонажа и его ролях, но нет информации о том, на каких позициях он играется. Поэтому для выяснения этого списка я обратилась к внешним ресурсам и занесла информацию об этом в программу вручную. Это можно увидеть в коде в месте, где определяются роли.
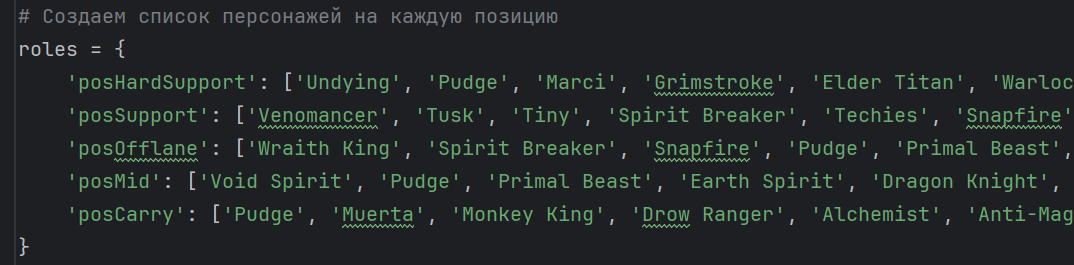
Программа берет столбцы Name, Roles, PrimaryAttribute из датасета. Так как в столбце Roles есть 9 значений, которые прописаны в разном количестве и разные у каждого персонажа, нужно было создать 9 дополнительных столбцов, где для каждого персонажа выставлялось 1, если такая роль присутствует в его описании и 0, если ее нет.
Пример: data['IsDurable'] = data['Roles'].apply(lambda x: 1 if 'Durable' in x else 0)
Далее столбец Roles был удален.
Так как PrimaryAttribute указан в строковом значении, он так же был переведен в числовое значение.
После этого нужно было заполнить столбцы posCarry, posMid, posOfflane, posSupport, posFullSupport. Если персонаж есть в списке персонажей с этой позицией, там проставлялась 1, 0 - если нет.
В итоге получился датасет, где есть имя персонажа, его главный атрибут в виде числа, его роли (1 - если есть, 0 - если нет) и то же самое с позициями.
Далее датафрейм делится на признаки (все столбцы, кроме столбцов с позициями) и метки (столбцы с позициями). Метки переводятся в числовой формат с помощью LabelEncoder(), иначе программа не может с ними работать. Данные делятся на обучающую и тестовую выборку.
Модель создается таким образом потому, что если ставить меньшее число итераций или скрытых слоев, то она не успевала обучаться. model = MLPClassifier(hidden_layer_sizes=(128, 128, 128), activation='relu', max_iter=1000, random_state=42)
Затем происходит предсказание позиций для тестовой выборки и оценка работы модели с помощью accuracy_score и classification_report
Результат
В результате получаем следующее:

Оценка модели имеет относительно низкое значение. Однако, как было сказано ранее, она могла не работать в принципе, поэтому я считаю это достаточно неплохим результатом и поставленная цель была выполнена - было выяснено, что позиция персонажа все-таки зависит от его атрибута и ролей, которые он выполняет по игре, хоть эта зависимость и не 100% явная. Если бы она была явная, например, все персонажи с атрибутом "сила" - это позиция offlane, тогда работа модели была бы значительно лучше.
Далее мы получаем classification report:
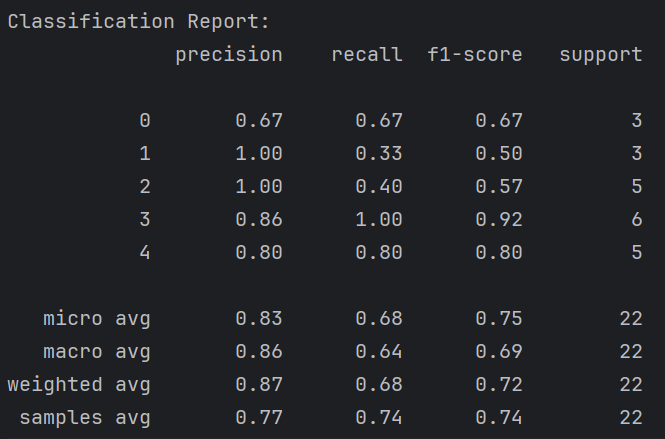
В данном отчете представлены 5 классов, то есть позиции (0, 1, 2, 3, 4). Для каждого класса представлены значения точности, полноты и F1-оценки, вычисленные с использованием соответствующих метрик. Также показана поддержка класса, которая представляет собой количество образцов, принадлежащих этому классу.
Precision (точность) - это метрика, которая оценивает долю правильно классифицированных объектов из всех объектов, которые модель отнесла к данному классу. Она измеряет, насколько точно модель предсказывает положительные классы.
Recall (полнота) - это метрика, которая оценивает долю правильно классифицированных объектов, отнесенных моделью к данному классу, относительно всех объектов, принадлежащих к данному классу. Она измеряет, насколько полно модель находит положительные классы.
F1-мера (F1-score) - это гармоническое среднее между precision и recall. Она используется для объединения оценок точности и полноты в единую метрику. F1-мера принимает значение между 0 и 1, где 1 - это идеальное значение, означающее, что модель идеально находит и точно классифицирует объекты положительного класса
micro avg - средневзвешенное значение точности, полноты и F1-оценки во всех классах, подсчитанное по общему количеству образцов.
macro avg - среднее значение точности, полноты и F1-оценки по всем классам, без учета количества образцов.
weighted avg - средневзвешенное значение точности, полноты и F1-оценки по всем классам, учитывая количество образцов.
samples avg - средневзвешенное значение точности, полноты и F1-оценки по всем классам, учитывая количество образцов класса (если образец может принадлежать нескольким классам).
Из данного отчета можно сделать вывод о том, что по атрибутам и ролям в игре модель точно выявила персонажей для позиции mid и offlane, но при этом, при работе с объектами, модель пропустила больше всего объектов, относящихся к этим классам, и занесла их в другие классы, из-за чего снизилась precision других классов. Мы сами должны выбирать, что важнее - точность или полнота, и в моем случае важнее точность, ведь изначально стоял вопрос о том, сможет ли модель определить, что к чему относится. Но низкие значения полноты говорят о том, что низкое значение accuracy вполне оправдано, и хоть модель и может выявить, какие объекты к каким классам относятся, делает она это не совсем "пОлно" и пропускает некоторые объекты.
Что касается признаков micro avg, macro avg, weighted avg, samples avg - все они показывают неплохие результаты относительно ожиданий по поводу работы модели. Я думаю, что для поставленной задачи значения этих показателей довольно высоки.
Вывод: точность и показатели из отчета вышли достаточно хорошими относительно поставленной задачи, также был получен ответ на вопрос зависит ли позиция персонажа от его атрибута и роли. Следовательно, с задачей разработанная модель справилась.