{kind=link}
{kind=link}
Лабораторная работа №4
ПИбд-42 Машкова Маргарита (Вариант 19)
Задание
C помощью метод кластеризации DBSCAN решить задачу: Сгруппировать телефоны по объему аккумулятора, размеру экрана, RAM и прочим показателям. Интерпретировать результаты и оценить, насколько хорошо он подходит для решения сформулированной задачи.
Данные:
Датасет о характеристиках мобильных телефонов и их ценах
Ссылка на датасет в kaggle: Mobile Phone Specifications and Prices
Модели:
- DBSCAN
Note
Метод DBSCAN позволяет получить оптимальное разбиение точек на оптимальное количество кластеров, а также выявить атипичные объекты (шум). Оценивается при помощи метрики
Силуэт (Silhouette Score)- насколько плотно объекты прилегают к центру кластера. Данная метрика оценивает качество кластеризации путем измерения среднего значения силуэта для каждой точки данных. Значение Silhouette Score находится в диапазоне от -1 до 1, где ближе к 1 означает лучшую кластеризацию. Высокое значение Silhouette Score указывает на хорошую разделимость кластеров, а низкое значение может указывать на перекрывающиеся кластеры.
Запуск программы
Для запуска программы необходимо запустить файл main.py
Используемые технологии
Язык программирования: python
Библиотеки:
pandas- предоставляет функциональность для обработки и анализа набора данных.sklearn- предоставляет широкий спектр инструментов для машинного обучения, статистики и анализа данных.
Описание работы программы
Описание набора данных
Данный набор содержит характеристики различных телефонов, в том числе их цену.
Названия столбцов набора данных и их описание:
- Id - идентификатор строки (int)
- Name - наименование телефона (string)
- Brand - наименование бренда телефона (string)
- Model - модель телефона (string)
- Battery capacity (mAh) - емкость аккумулятора в мАч (int)
- Screen size (inches) - размер экрана в дюймах по противоположным углам (float)
- Touchscreen - имеет телефон сенсорный экран или нет (string - Yes/No)
- Resolution x - разрешение телефона по ширине экрана (int)
- Resolution y - разрешение телефона по высоте экрана (int)
- Processor - количество ядер процессора (int)
- RAM (MB) - доступная оперативная память телефона в МБ (int)
- Internal storage (GB) - внутренняя память телефона в ГБ (float)
- Rear camera - разрешение задней камеры в МП (0, если недоступно) (float)
- Front camera - разрешение фронтальной камеры в МП (0, если недоступно) (float)
- Operating system - ОС, используемая в телефоне (string)
- Wi-Fi - имеет ли телефон функция Wi-Fi (string - Yes/No)
- Bluetooth - имеет ли телефон функцию Bluetooth (string - Yes/No)
- GPS - имеет ли телефон функцию GPS (string - Yes/No)
- Number of SIMs - количество слотов для SIM-карт в телефоне (int)
- 3G - имеет ли телефон сетевую функкцию 3G (string - Yes/No)
- 4G/ LTE - имеет ли телефон сетевую функкцию 4G/LTE (string - Yes/No)
- Price - цена телефона в индийских рупиях (int)
Первоначально данные обрабатываются: все строковые значения признаков необходимо привести к численным.
Метод не требует предварительных предположений о числе кластеров,
но нужно настроить два других параметра: eps и min_samples.
Данные параметры – это соответственно максимальное расстояние между соседними точками и минимальное число точек
в окрестности (количество соседей), когда можно говорить, что эти экземпляры данных образуют один кластер.
Далее выполняется два этапа предобработки данных:
- Масшатабирование: Создается экземпляр класса
StandardScaler(). Методfit_transform(data)этого класса применяется к данным, чтобы выполнить масштабирование. Результат масштабирования сохраняется в переменнойX_scaled. - Нормализация: Метод
normalize(X_scaled)применяется к масштабированным даннымX_scaled, чтобы выполнить нормализацию. Результат нормализации сохраняется в переменнойX_normalized.
Затем выполняется анализ главных компонент (PCA) на нормализованных данных и преобразование их в двумерное пространство.
Это позволяет снизить размерность данных и выделить наиболее информативные признаки.
Результат преобразования сохраняется в переменной X_principal.
Создается и обучается модель dbscan на нормализованных и масштабированных данных.
На основе всех признаков данные разбиваются на кластеры. В поле labels в алгоритме DBSCAN хранятся метки кластеров,
к которым были присвоены точки данных.
Каждая точка данных будет иметь свою метку, указывающую на принадлежность к определенному кластеру или на то,
что она не принадлежит ни одному кластеру и считается выбросом (кластер -1).
Вычисляется и выводятся в консоль количество кластеров и шумовых точек.
Качество кластеризации оценивается с помощью silhouette_score и выводится в консоль.
Отображается график кластеризации.
Тесты
Получившиеся кластеры и оценка качества кластеризации:
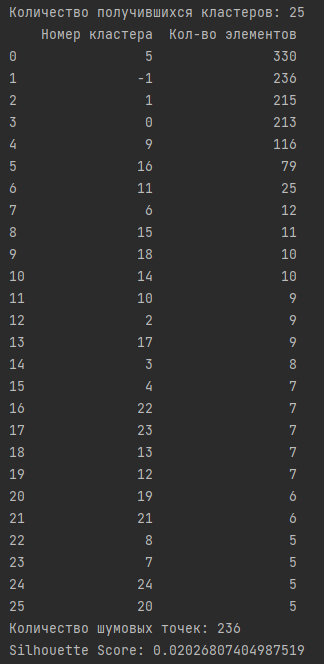
График кластеризации:
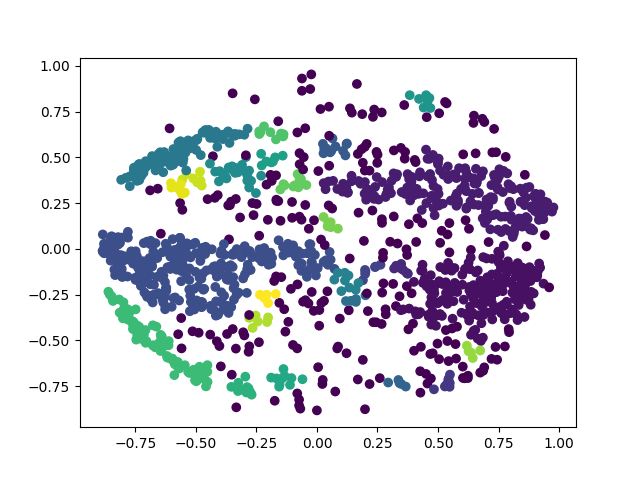
Шумовые точки изображены фиолетовым цветом.
Вывод: исходя из полученных результатов, значение метрики "силуэт" составляет всего 2%, что указывает на низкое
качество кластеризации и перекрывающиеся кластеры. Метод кластеризации DBSCAN плохо работает на этих данных.