{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Лабораторная работа №5. Регрессия
12 вариант
Задание:
Использовать регрессию по варианту для своих данных по варианту, самостоятельно сформулировав задачу. Оценить, насколько хорошо она подходит для решения сформулированной вами задачи.
Вариант:
- Тип регрессии: Логистическая регрессия
Вариант набора данных по курсовой работе:
- Прогнозирование музыкальных жанров ("Prediction of music genre")
Запуск
- Запустить файл lab5.py
Используемые технологии
- Язык программирования Python
- Среда разработки PyCharm
- Библиотеки:
- pandas
- sklearn
- matplotlib
- warnings
Описание программы
Набор данных (Kaggle): Полный список жанров, включенных в CSV: «Электронная музыка», «Аниме», «Джаз», «Альтернатива», «Кантри», «Рэп», «Блюз», «Рок», «Классика», «Хип-хоп».
Задача, решаемая регрессией: Предсказание популярности нового музыкального трека на основе его определённых характеристик. Регрессионная модель может предсказывать числовую оценку популярности трека, что может быть полезно для музыкальных платформ по типу Spotify.
Задача оценки:
- Вычисление 5 важных признаков и удаление из классификации ненужных
- Прогноз на тестовом на наборе и расчёт точности.
- Формирование матрицы путаницы для большего понимания.
- Формирование отчёта классификации
Пример работы
Датасет, сформированный из случайных строк csv-файла.
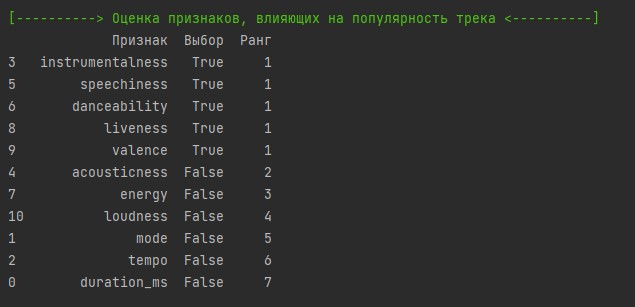
Вычисленные характеристики признаков. Меткой True и рангом №1 указаны 5 важных для популярности музыкального трека признаков.
Например, danceability (танцевальность) трека оказалось важным признаком, а duration_ms (длительность в милисекундах) — самый незначительный признак.
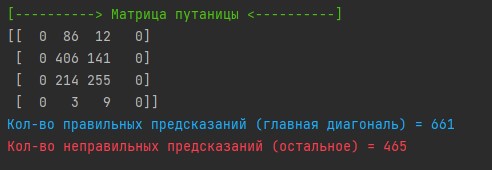
Матрица путаницы — это табличное представление прогнозов, сделанных моделью классификации, показывающее количество правильных и неправильных прогнозов для каждого класса. На пересечениях n-строки и n-столба показаны верные прогнозы признака с индексом i. На данной матрице видно, что на популярности уровня 0 и 3 не было ни одного верного предсказания.
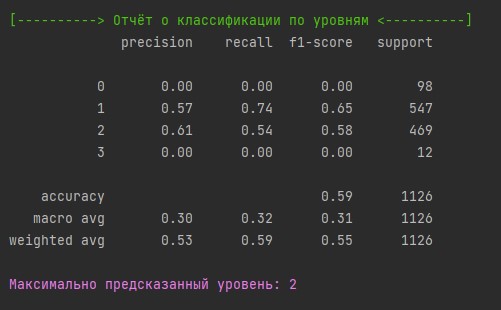
Оценка точности модели. По матрице путаницы можно было заметить, что оценка по значению чуть больше 50%, так как количество верных и неверных прогнозов не сильно отличается.

На отчёте также можно заметить по нулям у уровней популярности 0 и 3, что там ни одно значение не было верно предсказано.
Вывод
Итак, можно сказать, что с поставленной задачей логистическая регрессия больше справилась, чем не справилась. Но в то же время популярность трека — неоднозначный признак. Нельзя по характеристикам музыкального трека точно сказать, насколько он взлетит в чартах. Считаю, что именно поэтому программа не смогла предсказать нулевую и высшую популярность, а назначила тестовой выборке лишь средние значения популярности.
Логистическая регрессия выполняется быстро и относительно несложно, в ней удобно интерпретировать результаты. Хотя по сути это метод бинарной классификации, его также можно применять к задачам мультиклассов, что я и сделал (было бы нелогично обозначать популярность лишь метками True и False, когда можно её разделить на уровни).
Также логистическая регрессия не готова обрабатывать избыточное количество категорических признаков. Она подвержена переподбору, что и было сделано в данной лабораторной работе. Логистическая регрессия не будет хорошо работать с независимыми признаки трека, которые не коррелируют с популярностью трека.