{kind=link}
Вариант 9
Задание на лабораторную работу:
Решите с помощью библиотечной реализации дерева решений задачу: Запрограммировать дерево решений как минимум на 99% ваших данных для задачи: Зависимость глубины алмаза (depth) от длины (x), ширины (y) и высоты алмаза (z) . Проверить работу модели на оставшемся проценте, сделать вывод.
Как запустить лабораторную работу:
Выполняем файл gusev_vladislav_lab_3.py, решение будет в консоли.
Технологии
Sklearn - библиотека с большим количеством алгоритмов машинного обучения. Нам понадобится библиотека для дерева решения регрессии sklearn.tree.DecisionTreeRegressor.
По коду
- Для начала загружаем данные из csv файла
- Разделеям данные на признаки (X) и целевую переменную (y)
- Разделяем данные на обучающее и тестовые
- Обучаем дерево регрессией (model)
- Выводим важность признаков, предсказание значений на тестовой выборке и оценку производительности модели
Пример:
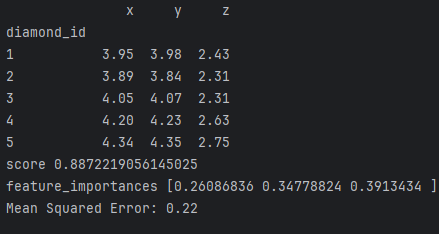
Вывод
- score: ~0.88. Это мера того, насколько хорошо модель соответствует данным. По значению 88% можно сказать, что модель хорошо соответствует данным.
- feature_importances: ~0.26, ~0.34, ~0,39. Это говорит о важности признаков для нашей модели. Можно сказать, что высота (z) имеет наибольшую важность.
- Mean Squared Error: 0.22. Это ошибка модели. Это говорит о том, что модель в среднем ошибается в 22% случаев.
По итогу можно сказать, что модель отработала хорошо, из-за score ~0.88.