| .. | ||
| .gitignore | ||
| img.png | ||
| README.md | ||
| senkin_alexander_lab_2.py | ||
{kind=link}
Лабораторная №2
Вариант №2
Задание на лабораторную:
выполните ранжирование признаков с помощью указанных по варианту моделей. Отобразите получившиеся значения\оценки каждого признака каждым методом\моделью и среднюю оценку. Проведите анализ получившихся результатов. Какие четыре признака оказались самыми важными по среднему значению? (Названия\индексы признаков и будут ответом на задание).
Модели:
- Линейная регрессия (LinearRegression)
- Рекурсивное сокращение признаков (Recursive Feature Elimination – RFE)
- Сокращение признаков Случайными деревьями (Random Forest Regressor)
Как запустить лабораторную работу:
Чтобы увидеть работу программы, нужно запустить исполняемый питон файл senkin_alexander_lab_2.py, после чего в консоли будут выведены все признаки, их ранжирование и топ 4 признака по среднему значению значимости.
Библиотеки
Numpy. иблиотека для работы с массивами и матрицами чисел. Она используется для создания и манипуляции данными.
Sklearn. Предоставляет инструменты и алгоритмы, которые упрощают задачи, связанные с машинным обучением.
Описание программы:
- Генерируем набор данных из 100 точек данных используя функцию make_circles
- С помощью функции train_test_split разделяем данные на тестовые и обучающие в соотношении 20 к 80
- Добавляем дополнительные признаки, чтобы в сумме было 20 признаков
- Создаем 3 модели:
- Линейную регрессию (LinearRegression)
- Рекурсивное сокращение признаков (Recursive Feature Elimination – RFE)
- Сокращение признаков Случайными деревьями (Random Forest Regressor)
- Обучаем модели и производим ранжирование
- Линейная регрессия дает ранжирование признаков на основе абсолютных коэффициентов.
- RFE (Рекурсивное сокращение признаков) ранжирует признаки на основе их значимости для модели.
- Random Forest Regressor оценивает важность признаков на основе их вклада в прогнозы модели.
- Посредством вычисления среднего ранжирования по всем трем методам мы определяем, какие признаки являются самыми важными с учетом всех трех методов.
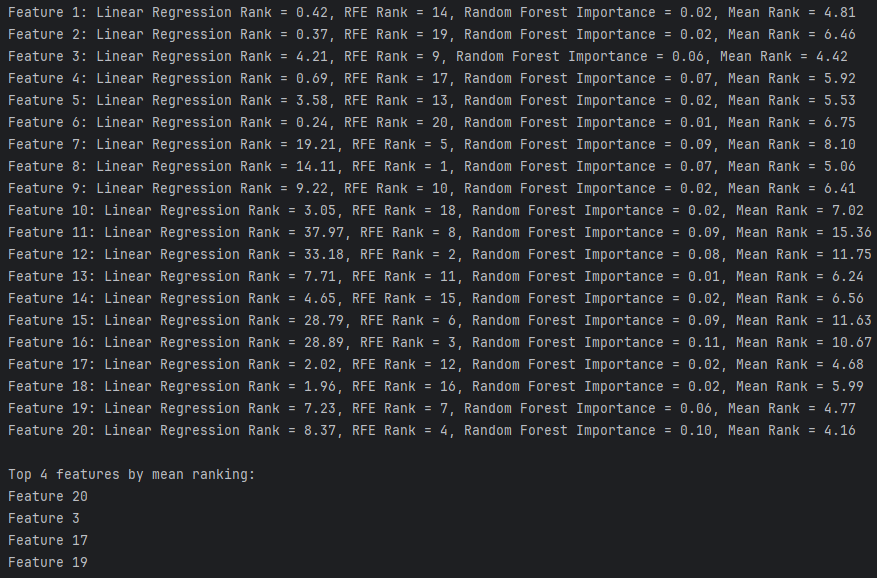
Делаем вывод, что по среднему значению самыми важными признаками являются 3, 17, 19 и 20 признаки