{kind=link}
{kind=link}
Лабораторная работа №4, ПИбд-42 Тепечин Кирилл
Датасет:
Ссылка:
Smoking and Drinking Dataset with body signal
Подробности датасета
| Столбец | Пояснение |
|---|---|
| sex | Пол(мужской, женский) |
| age | Возраст(округлён) |
| height | Рост(округлён) [см] |
| weight | [кг] |
| sight_left | зрение (левый) |
| sight_left | зрение (правый) |
| hear_left | слух (левое): 1 (нормальное), 2 (ненормальное) |
| hear_right | слух (правое): 1 (нормальное), 2 (ненормальное) |
| SBP | Систолическое артериальное давление [мм рт. ст.] |
| DBP | Диастолическое артериальное давление [мм рт. ст.] |
| BLDS | глюкоза в крови натощак [мг/дл] |
| tot_chole | общий холестерин [мг/дл] |
| HDL_chole | Холестерин ЛПВП [мг/дл] |
| LDL_chole | Холестерин ЛПНП [мг/дл] |
| triglyceride | триглицерид [мг/дл] |
| hemoglobin | гемоглобин [г/дл] |
| urine_protein | белок в моче, 1(-), 2(+/-), 3(+1), 4(+2), 5(+3), 6(+4) |
| serum_creatinine | креатинин сыворотки (крови) [мг/дл] |
| SGOT_AST | глутамат-оксалоацетат-трансаминаза / аспартат-трансаминаза [МЕ/л] |
| SGOT_ALT | аланиновая трансаминаза [МЕ/л] |
| gamma_GTP | γ-глутамилтранспептидаза [МЕ/л] |
| SMK_stat_type_cd | Степень курения: 1 (никогда), 2 (бросил), 3 (курю) |
| DRK_YN | Пьющий или нет |
Как запустить лабораторную работу:
Для запуска лабораторной работы необходимо запустить файл lab4.py
Используемые технологии:
- Python 3.12
- pandas
- scikit-learn
- matplotlib
Что делает лабораторная работа:
Эта лабораторная программа загружает данные из csv файла, выбирает признаки, нормализует данные, строит дендрограмму и оценивает качество кластеризации с помощью silhouette score.
Предварительная обработка данных:
Т.к датасет содержит слишком большое количество данных следует уменшить их размер
data = data.sample(frac=0.01, random_state=42)
Результат:
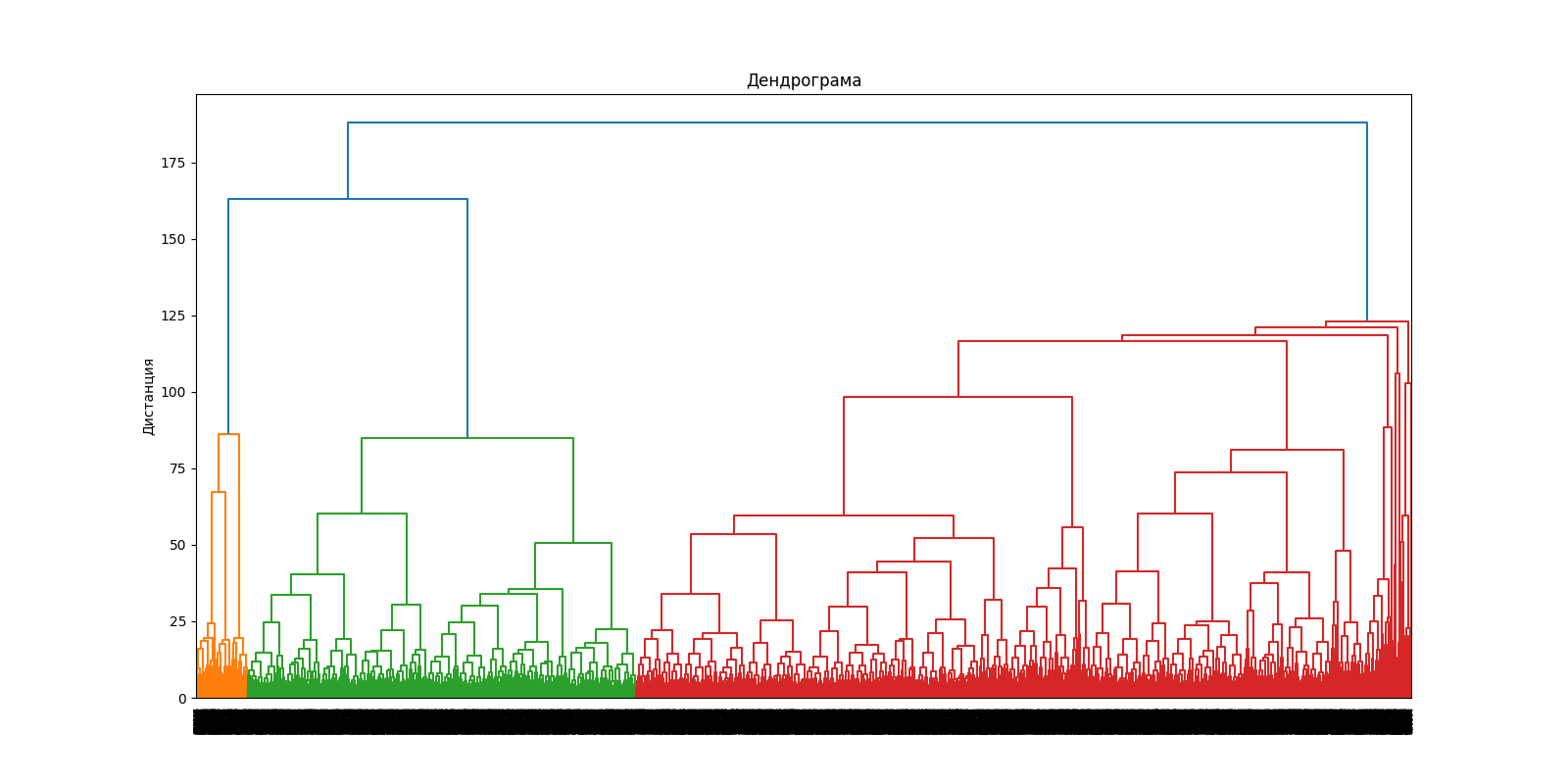 На основании этой дендрограмы можно выбрать количество кластеров, на которое разумно поделить данные (4)
На основании этой дендрограмы можно выбрать количество кластеров, на которое разумно поделить данные (4)
Теперь используем метод иерархической кластеризации (AgglomerativeClustering) с 4 кластерами. Метки кластеров присваиваются данным, а затем вычисляется показатель silhouette score, который оценивает качество кластеризации.

Вывод:
Значение в районе 0.094 может быть интерпретировано как относительно низкое, что может указывать на то, что данные не разделены очень четко в кластеры, поэтому можно сделать вывод, что метод плохо подходит для решения задачи.