{kind=link}
{kind=link}
Лабораторная 5
Вариант 9
Задание
Использовать Ласо-регрессию, самостоятельно сформулировав задачу. Оценить, насколько хорошо она подходит для решения сформулированной вами задачи.
Задача:
Можно использовать регрессию для прогнозирования заработной платы на основе опыта работы (experience_level), типа занятости (employment_type), местоположения компании (company_location) и размера компании (company_size).
Описание Программы
Программа представляет собой пример использования Lasso регрессии для прогнозирования заработной платы на основе различных признаков.
Используемые библиотеки
pandas: Библиотека для обработки и анализа данных, используется для загрузки и предобработки данных.scikit-learn:
train_test_split: Используется для разделения данных на обучающий и тестовый наборы.
StandardScaler: Применяется для нормализации числовых признаков.
OneHotEncoder: Используется для кодирования категориальных признаков.
Lasso: Линейная модель Lasso для обучения регрессии.
Pipeline: Позволяет объединять шаги предварительной обработки данных и обучения модели в пайплайн.
matplotlib: Используется для визуализации коэффициентов модели в виде горизонтальной столбчатой диаграммы.numpy: Использована для работы с числовыми данными.
Шаги программы
Загрузка данных:
Используется библиотека pandas для загрузки данных из файла ds_salaries.csv.
Предварительная обработка данных:
Категориальные признаки ('experience_level', 'employment_type', 'company_location', 'company_size') обрабатываются с использованием OneHotEncoder, а числовые признаки ('work_year') нормализуются с помощью StandardScaler. Эти шаги объединены в ColumnTransformer и используются в качестве предварительного обработчика данных.
Выбор признаков:
Определены признаки, которые будут использоваться для обучения модели.
Разделение данных:
Данные разделены на обучающий и тестовый наборы в соотношении 80/20 с использованием train_test_split.
Обучение модели:
Используется линейная модель Лассо-регрессия, объединенная с предварительным обработчиком данных в рамках Pipeline.
Оценка точности модели:
Вычисляется коэффициент детерминации (R^2 Score) и среднеквадратичная ошибка (Mean Squared Error) для оценки точности модели.
Вывод предсказанных и фактических значений:
Создается DataFrame с фактическими и предсказанными значениями и выводится в консоль.
Визуализация весов (коэффициентов) модели:
Строится горизонтальная столбчатая диаграмма для визуализации весов (коэффициентов) модели.
Запуск программы
- Склонировать или скачать код
main.py. - Запустите файл в среде, поддерживающей выполнение Python.
python main.py
Результаты

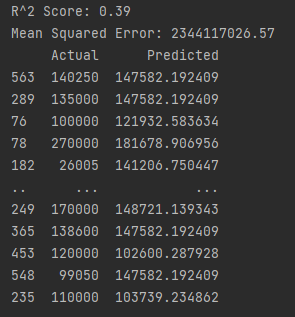
Точность модели составляет всего 39%, что является довольно низким показателем
MSE довольно высок, что указывает на то, что модель не слишком хорошо соответствует данным и допускает ошибки в предсказаниях
Фактические и предсказанные значения: видно, что модель часто недооценивает или переоценивает заработную плату. Например, для индексов 563 и 289 фактическая заработная плата выше, чем предсказанная.
Изменение alfa не особо улучшает общую картину, поэтому, можно сделать вывод, что следует выбрать другой алгоритм.