3.0 KiB
Задание по варианту
Лассо (Lasso),Сокращение признаков Случайными деревьями (Random Forest Regressor), Линейная корреляция (f_regression)
Как запустить лабораторную работу
ЛР запускается через файл zavrazhnova_svetlana_lab_2.py
Какие технологии использовали
импорт класса MinMaxScaler, выполняющего масштабирование данных до заданного диапазона (от 0 до 1).
Необходимость его использования объясняется следующим: каждая модель регрессии дает оценки
важности признаков в своем диапазоне. Для того чтобы найти признак с максимальной средней важностью по трем моделям, нам необходимо привести выданные ими оценки к одному виду.
Модели линейной регрессии, ридж-регрессии и лассо-регрессии из библиотеки scikit-learn
Что делает
Применение регрессионных моделей для определения важности признаков.
Результат работы программы показывает ранжирование признаков по их значимости для задачи. Чем больше значение ранга, тем более значимый признак. Полученные ранги можно использовать для отбора наиболее значимых признаков и сокращения размерности данных.
Примеры выходных значений
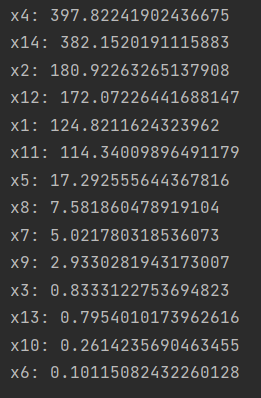
В данном случае, в соответствии с полученными результатами, можно сказать следующее:
- Признаки 'x4' и 'x14' имеют наивысшие ранги (больше 380), что указывает на их большую значимость в решении задачи.
- Признаки 'x2' и 'x12' имеют средние ранги (от 170 до 180), что означает их среднюю значимость.
- Признаки 'x1' и 'x11' имеют ранги около 120, что указывает на их относительную значимость.
- Признаки 'x5', 'x8' и 'x7' имеют низкие ранги (от 5 до 17), что говорит о их низкой значимости.
- Признаки 'x9', 'x3', 'x13', 'x10' и 'x6' имеют очень низкие ранги (меньше 3), что указывает на их минимальную значимость или наличие практически нулевых эффектов.