4.8 KiB
Лабораторная работа №3, ПИбд-42 Тепечин Кирилл
Датасет:
Ссылка:
Smoking and Drinking Dataset with body signal
Подробности датасета
| Столбец | Пояснение |
|---|---|
| sex | Пол(мужской, женский) |
| age | Возраст(округлён) |
| height | Рост(округлён) [см] |
| weight | [кг] |
| sight_left | зрение (левый) |
| sight_left | зрение (правый) |
| hear_left | слух (левое): 1 (нормальное), 2 (ненормальное) |
| hear_right | слух (правое): 1 (нормальное), 2 (ненормальное) |
| SBP | Систолическое артериальное давление [мм рт. ст.] |
| DBP | Диастолическое артериальное давление [мм рт. ст.] |
| BLDS | глюкоза в крови натощак [мг/дл] |
| tot_chole | общий холестерин [мг/дл] |
| HDL_chole | Холестерин ЛПВП [мг/дл] |
| LDL_chole | Холестерин ЛПНП [мг/дл] |
| triglyceride | триглицерид [мг/дл] |
| hemoglobin | гемоглобин [г/дл] |
| urine_protein | белок в моче, 1(-), 2(+/-), 3(+1), 4(+2), 5(+3), 6(+4) |
| serum_creatinine | креатинин сыворотки (крови) [мг/дл] |
| SGOT_AST | глутамат-оксалоацетат-трансаминаза / аспартат-трансаминаза [МЕ/л] |
| SGOT_ALT | аланиновая трансаминаза [МЕ/л] |
| gamma_GTP | γ-глутамилтранспептидаза [МЕ/л] |
| SMK_stat_type_cd | Степень курения: 1 (никогда), 2 (бросил), 3 (курю) |
| DRK_YN | Пьющий или нет |
Как запустить лабораторную работу:
Для запуска лабораторной работы необходимо запустить файл lab3.py
Используемые технологии:
- Python 3.12
- pandas
- scikit-learn
Что делает лабораторная работа:
Эта лабораторная программа загружает данные из csv файла, подготавливает их для обучения модели классификации дерева решений, обучает модель, выполняет прогнозы и оценивает ее точность, а затем выводит важность признаков.
Целевой признак - SMK_stat_type_cd - степень курения
Предварительная обработка данных:
Изначально датасет имеет несколько категориальных признаков : sex , DRK_YN
Преобразуем их в фиктивные переменные используя
data = pd.get_dummies(data, columns=['sex', 'DRK_YN'], drop_first=True)
Результат:
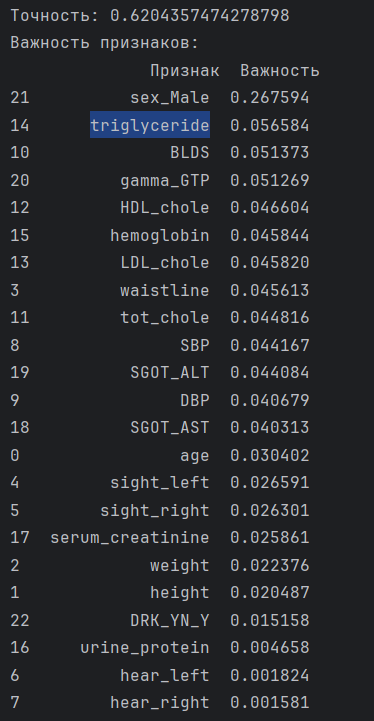
Вывод:
На основе этих результатов можно сделать выводы о том, что половой признак (sex_Male) оказывается наиболее влиятельным для классификации степени курения. Также можно выделить наименее важные признаки, это слух (hear_left, hear_right).
Точность модели составляет примерно 62%, говорит о том, что она классифицирует данные с относительно средней точностью.