7.1 KiB
Задание
Выбрать художественный текст (четные варианты – русскоязычный, нечетные – англоязычный) и обучить на нем рекуррентную нейронную сеть для решения задачи генерации. Подобрать архитектуру и параметры так, чтобы приблизиться к максимально осмысленному результату.Далее разбиться на пары четный-нечетный вариант, обменяться разработанными сетями и проверить, как архитектура товарища справляется с вашим текстом.
Как запустить лабораторную
Запустить файл main.py
Используемые технологии
Библиотеки tensorflow, numpy, их компоненты
Описание лабораторной (программы)
Данная лабораторная работа обучает модели для обработки русского и английского текста и решает задачу генерации. Ниже будет описан алгоритм работы одной из моделей (вторая работает аналогично):
- Читается текст из файла
- Создается экземпляр Tokenizer для токенизации текста
- С помощью метода fit_on_texts токенизатор анализирует текст и строит словарь уникальных слов
- rus_vocab_size - длина словаря
- C помощью метода text_to_sequences текст преобразуется в последовательность чисел
- Создаются последовательности для обучения модели
- Рассчитывается максимальная длина последовательности
- Входные последовательности выравниваются до максимальной длины
- С помощью функции to_categorical последовательности преобразуются в one-hot представление
- Переменные x_rus_train, y_rus_train инициализируются соответствующими значениями
- Такая же обработка текста происходит и для текста на английском языке
- Происходит создание модели на русском языке:
- создается экземпляр модели Sequential
- добавляется слой Embedding, отображающий слова в векторы фиксированной длины
- добавляется слой LSTM с 512 нейронами
- добавляется слой Dense с функцией softmax для получения вероятности каждого слова в словаре
- модель компилируется
- Происходит обучение модели через model.fit()
- Все то же самое происходит для модели с английским языком
- Определяется функция generate_text для генерации текста на основе всех заданных параметров
- Выводятся результаты работы моделей и сгенерированные тексты
Результат
Результат сгенерированного текста на русском языке: Помню просторный грязный двор и низкие домики обнесённые забором двор стоял у самой реки и по вёснам когда спадала полая вода он был усеян щепой и ракушками а иногда и другими куда более интересными вещами так однажды мы нашли туго набитую письмами сумку а потом вода принесла и осторожно положила на берег и самого почтальона он лежал на спине закинув руки как будто заслонясь от солнца ещё совсем молодой белокурый в форменной тужурке с блестящими пуговицами должно быть отправляясь в свой последний рейс почтальон начистил их мелом мелом мелом спадала щепой мелом мелом мелом мелом мелом спадала полая вода он ракушками а
Результат сгенерированного текста на английском языке: The old man was thin and gaunt with deep wrinkles in the back of his neck the brown blotches of the benevolent skin cancer the sun brings from its reflection on the tropic sea were on his cheeks the blotches ran well down the sides of his face and his hands had the deep creased scars from handling heavy fish on the cords but none of these scars were fresh they were as old as erosions in a fishless desert fishless desert desert desert desert desert desert desert desert desert desert desert desert desert desert desert desert desert desert desert desert desert fishless
Результат потерь на тренировочных данных:
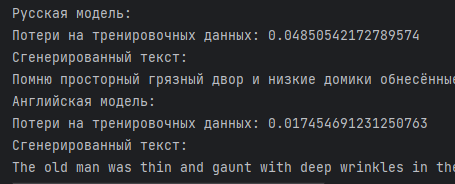
Вывод: можно заметить, что в сгенерированных текстах в конце слова повторяются. Это происходит потому, что в параметрах модели указано сгенерировать 100 слов, хотя в тексте, по которому модель обучается, меньше слов. Поэтому сгенерированный текст сначала соответствует тексту для обучения, а затем начинает выдавать рандомные слова. Но нужно отметить, что это слова, а не просто набор букв и пробелы, которые получались при иных настройках моделей.
Так как у английской модели меньше потерь на тренировочных данных, чем у русской, то получается, что выполненная модель обрабатывает английский текст чуть лучше, чем русский, но в результате обе модели выдали осмысленный текст, что связано с большим числом нейронов и эпох, при помощи которых обучалась модель. Ведь когда было 20 эпох, а не 200, модель выдавала очень слабо осмысленный результат.