{kind=link}
{kind=link}
{kind=link}
Вариант 2
Задание: Использовать метод кластеризации по варианту для данных из таблицы 1 по варианту(таблица 9), самостоятельно сформулировав задачу. Интерпретировать результаты и оценить, насколько хорошо он подходит для решения сформулированной вами задачи.
Данные: Данный набор данных использовался во второй главе недавней книги Аурелиена Жерона "Практическое машинное обучение с помощью Scikit-Learn и TensorFlow". Он служит отличным введением в реализацию алгоритмов машинного обучения, потому что требует минимальной предварительной обработки данных, содержит легко понимаемый список переменных и находится в оптимальном размере, который не слишком мал и не слишком большой.
Данные содержат информацию о домах в определенном районе Калифорнии и некоторую сводную статистику на основе данных переписи 1990 года. Следует отметить, что данные не прошли предварительную очистку, и для них требуются некоторые этапы предварительной обработки. Столбцы включают в себя следующие переменные, их названия весьма наглядно описывают их суть:
долгота longitude
широта latitude
средний возраст жилья median_house_value
общее количество комнат total_rooms
общее количество спален total_bedrooms
население population
домохозяйства households
медианный доход median_income
Запуск: Запустите файл lab4.py
Описание программы:
-
Загружает набор данных из файла 'housing.csv', который содержит информацию о домах в Калифорнии, включая их координаты, возраст, количество комнат, население, доход и другие характеристики.
-
Предобработка данных: Производится заполнение пропущенных значений медианными значениями и стандартизация данных для более точных результатов кластеризации.
-
Выбор метода кластеризации: Программа использует метод linkage и евклидовой метрикой для объединения домов в кластеры.
-
Определение числа кластеров: В данном случае, выбрано 5 кластеров для группировки домов.
-
Применение кластеризации: Программа выполняет кластеризацию, присваивая каждому дому метку кластера на основе его характеристик.
-
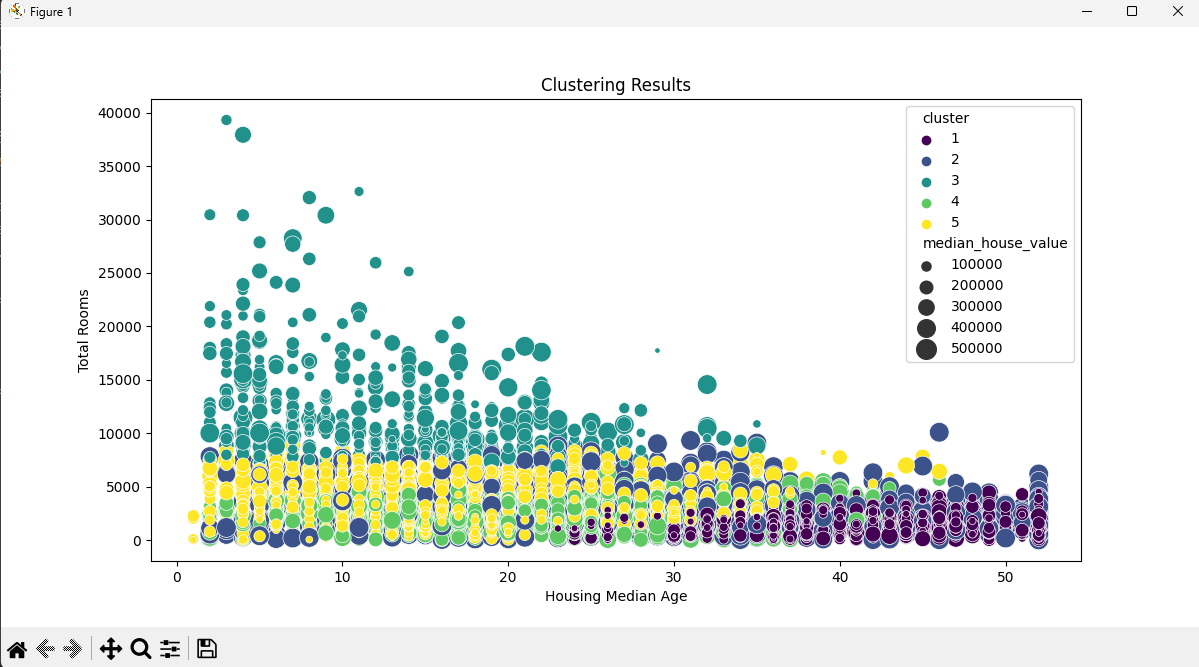
Визуализация результатов: Результаты кластеризации визуализируются на графике, используя библиотеку seaborn. Каждый дом представлен точкой, где координаты - это возраст дома и общее количество комнат, а размер точки соответствует стоимости жилья.
-
Добавление информации о кластерах: Дополнительная информация о принадлежности кластерам добавляется к исходным данным.
-
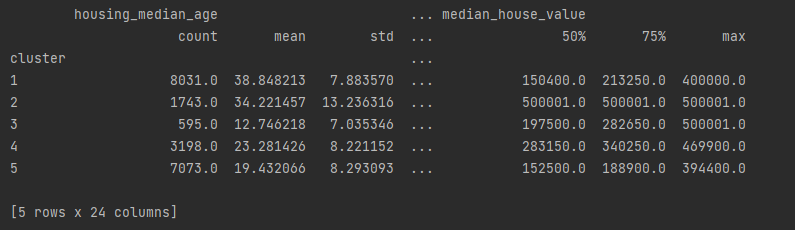
Программа предоставляет статистический анализ для каждого кластера, включая средние значения, стандартное отклонение и квартили характеристик домов.
Результаты:
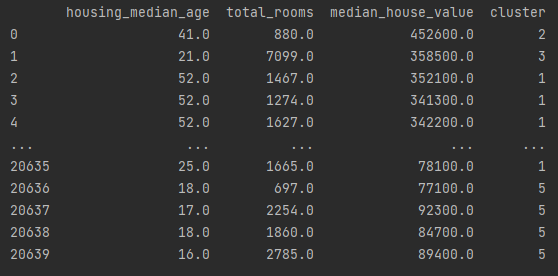
Выводы:
Количество кластеров: В данной кластеризации использовано 5 кластеров для группировки домов в Калифорнии на основе их характеристик.
Характеристики кластеров:
Кластер 1: Включает дома с высоким средним возрастом жилья и относительно низкой стоимостью жилья. Это могут быть старые дома в более старых районах. Кластер 2: Содержит дома с высокой стоимостью жилья и высокими доходами. Возможно, это элитные районы с дорогим жильем. Кластер 3: Группирует дома с низким средним возрастом жилья и средней стоимостью жилья. Возможно, это новые постройки в развивающихся районах. Кластер 4: Включает дома с разнообразными характеристиками и средней стоимостью жилья. Этот кластер может представлять смешанные районы. Кластер 5: В этот кластер входят дома с низкими доходами и средним возрастом жилья. Возможно, это районы с более доступным жильем.