3.9 KiB
IIS_2023_1
Задание
Использовать метод кластеризации по варианту для данных из таблицы 1 по варианту(таблица 9),самостоятельно сформулировав задачу. Интерпретировать результаты и оценить, насколько хорошо он подходит для решения сформулированной вами задачи. 4. DBSCAN
Способ запуска лабораторной работы
Выполнить скрипт shadaev_anton_lab_4/main.py
Стек технологий
Python: v. 3.11Pandas- библиотека, которая позволяет работать с двумерными и многомерными таблицами, строить сводные таблицы, выделять колонки, использовать фильтры по параметрам, выполнять группировку по параметрам, запускать функции (сложение, нахождение медианы, среднего, минимального, максимального значений), объединять таблицы и многое другоеSklearn- предоставляет ряд инструментов для моделирования данных, включая классификацию, регрессию, кластеризацию и уменьшение размерности.Matplotlib- это библиотека для визуализации данных в Python, предоставляющая инструменты для создания статических, анимированных и интерактивных графиков и диаграмм.
Описание кода
- Загрузка данных из .csv-файла.
- Предварительная обработка данных от null-значений.
- Отбор признаков.
- Нормализация признаков.
- Применение алгоритма DBScan.
- Визуализация данных.
График:
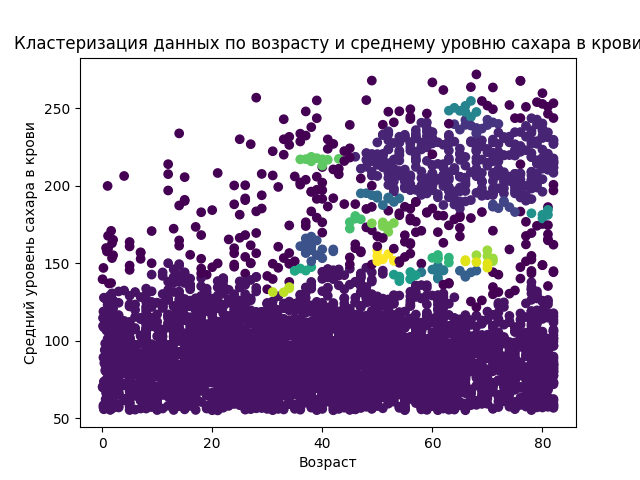
Вывод
Каждый цвет представляет собой отдельный кластер, и точки с одинаковым цветом принадлежат одному и тому же кластеру.
- Средний уровень сахара в крови варьируется (примерно) от 140 до 250. Возраст варьируется (примерно) от 30 до 80.
- На графике видно очень много фиолетовых точек, что говорит о том, что на нашем графике очень много шума. Но по другим точкам (более светлым) уже можем отобрать какие-то данные.
В целом, применение алгоритма DBScan к признакам (age, avg_glucose_level) из данного датасета не очень эффективно. Визуально можно оценить эффективность алгоритма на 5-10%. В моем случае этот алгоритм неэффективен, т.к. алгоритм лучше работает с данными с высокой плотностью, а разделить на группы среди признаков возраст и средний уровень сахара в крови может быть проблематично, т.к. получится выделить не так много характеристик среди групп с разным возрастом. По-сути все, что мы имеем, это низкий, средний, высокий уровень сахара в крови среди разных возрастных групп.