| .. | ||
| 1.png | ||
| 2.png | ||
| 3.png | ||
| main.py | ||
| README.md | ||
{kind=link}
{kind=link}
{kind=link}
Лабораторная работа №4. Вариант 21
Тема:
Кластеризация
Модель:
KMeans
Как запустить программу:
Установить python, numpy, matplotlib, sklearn
python main.py
Какие технологии использовались:
Язык программирования Python, библиотеки numpy, matplotlib, sklearn
Среда разработки VSCode
Что делает лабораторная работа:
Задача кластеризации заключается в разделении множества данных на группы, называемые кластерами, таким образом, чтобы объекты внутри одного кластера были более похожи друг на друга, чем на объекты из других кластеров. Это позволяет выявлять скрытые структуры данных, облегчая последующий анализ и принятие решений.
В данной работе была рассмотрена модель KMeans.
Описание:
KMeans разбивает данные на K кластеров, где K - заранее заданное число. Он минимизирует сумму квадратов расстояний между точками данных и центрами своих соответствующих кластеров. Этот алгоритм прост в реализации и хорошо работает для сферических кластеров.
Кластеризация данных - это мощный инструмент для выделения закономерностей в больших объемах информации, и выбор конкретного алгоритма зависит от характера данных и поставленных задач. В данной работе мы рассмотрим эти алгоритмы более подробно, выявим их преимущества и недостатки, и проиллюстрируем их применение на практике.
Процесс получения кластеров происходит по следующему алгоритму:
1. Получаемый исходные данные
2. Приводим их всех к численному формату
3. Обучение на подготовленных данных
def clustering_df(X, n, m, output_hist, title='clusters_by'):
X_columns = X.columns
scaler = StandardScaler()
scaler.fit(X)
X = pd.DataFrame(scaler.transform(X), columns = X_columns)
cl = generate_clustering_algorithms(X, n, m)
cl.fit(X)
if hasattr(cl, 'labels_'):
labels = cl.labels_.astype(np.uint8)
else:
labels = cl.predict(X)
clusters=pd.concat([X, pd.DataFrame({'cluster':labels})], axis=1)
Для кластеризации были выбраны все столбцы, часть кода представлена ниже:
print(data.select_dtypes(include='object').columns.tolist())
for column in data.select_dtypes(include='object').columns.tolist():
data[column] = pd.factorize(data[column])[0]
Программа генерирует диаграммы для каждого кластера относительно всех признаков. Для меня наиболее интересным показались признаки возраста и наличия заболевания человека.


Изучая графики выше, мы можем сделать вывод, что люди из кластера №3 почти все болеют и большинство имеет 2,3 и 4 стадии. А возраст этих людей от 45 до 70 лет.
Ниже приложен результат обучения алгоритма кластеризации:
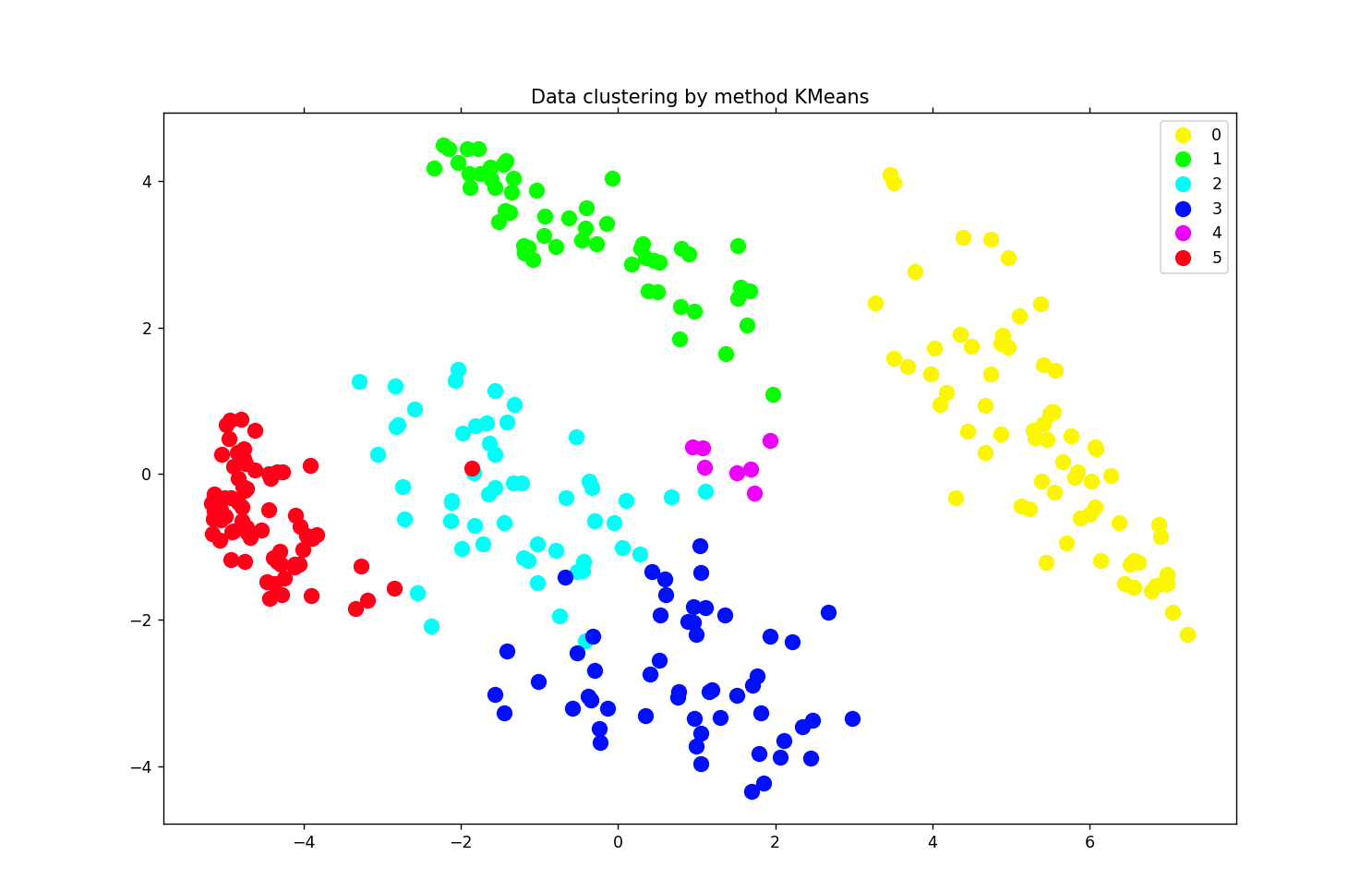
Вывод
Я думаю, что алгоритм KMeansсправился достаточно хорошо, т.к. в нем каждый кластер получился обособленным, то есть более отличным от других кластеров. Следовательно, это может означать, что именно этот алгоритм смог понять ключевые признаки для каждого кластера.