{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Лабораторная работа №4
Кластеризация
Как запустить лабораторную работу
- Установить python, numpy, sklearn, matplotlib, plotly
- Запустить команду
python tnse.pyв корне проекта
Использованные технологии
- Язык программирования
python - Библиотеки
numpy, sklearn, matplotlib, plotly - Среда разработки
PyCharm
Что делает программа?
Цель программы: кластеризовать ценовые диапазоны автомобилей на вторичном рынке. Используя метод кластеризации t-SNE, происходит обучение, оценка и вывод результатов кластеризации в виде графика.
Так как метод визуальный, то оценка будет проводится субъективно по критериям общего цвета и отдалённости кластеров друг от друга.
Эксперимент
Текущие параметры:
- mileage
- year
- price
TSNE(learning_rate=100)
На размере данных в 1000 строк
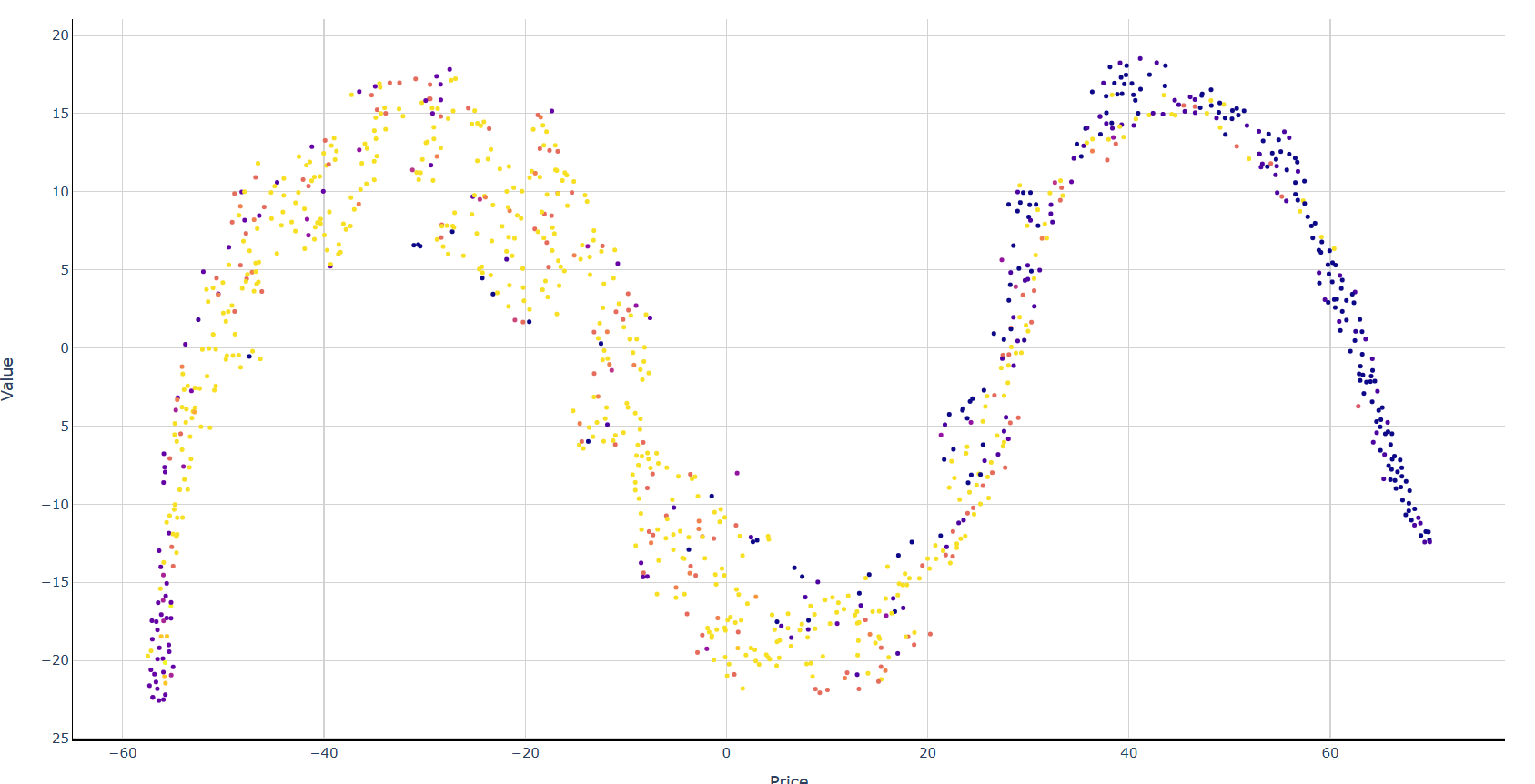
На размере данных в 15000 строк
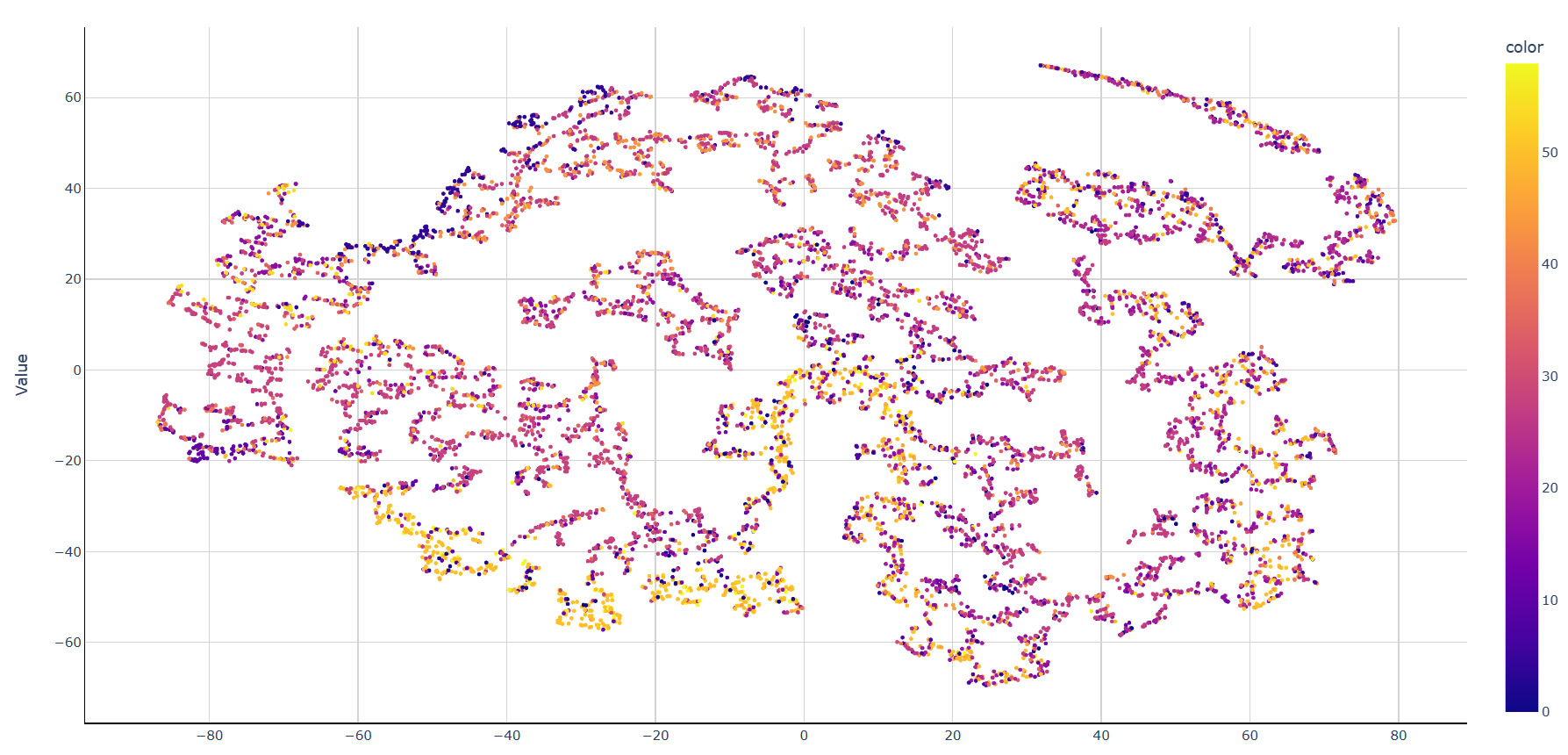
TSNE(learning_rate=200, perplexity=50, early_exaggeration=6)
early_exaggeration - определяет, насколько плотными будут естественные кластеры исходного пространстве во вложенном пространстве и сколько места будет между ними. (12 по умолчанию)
На размере данных в 1000 строк
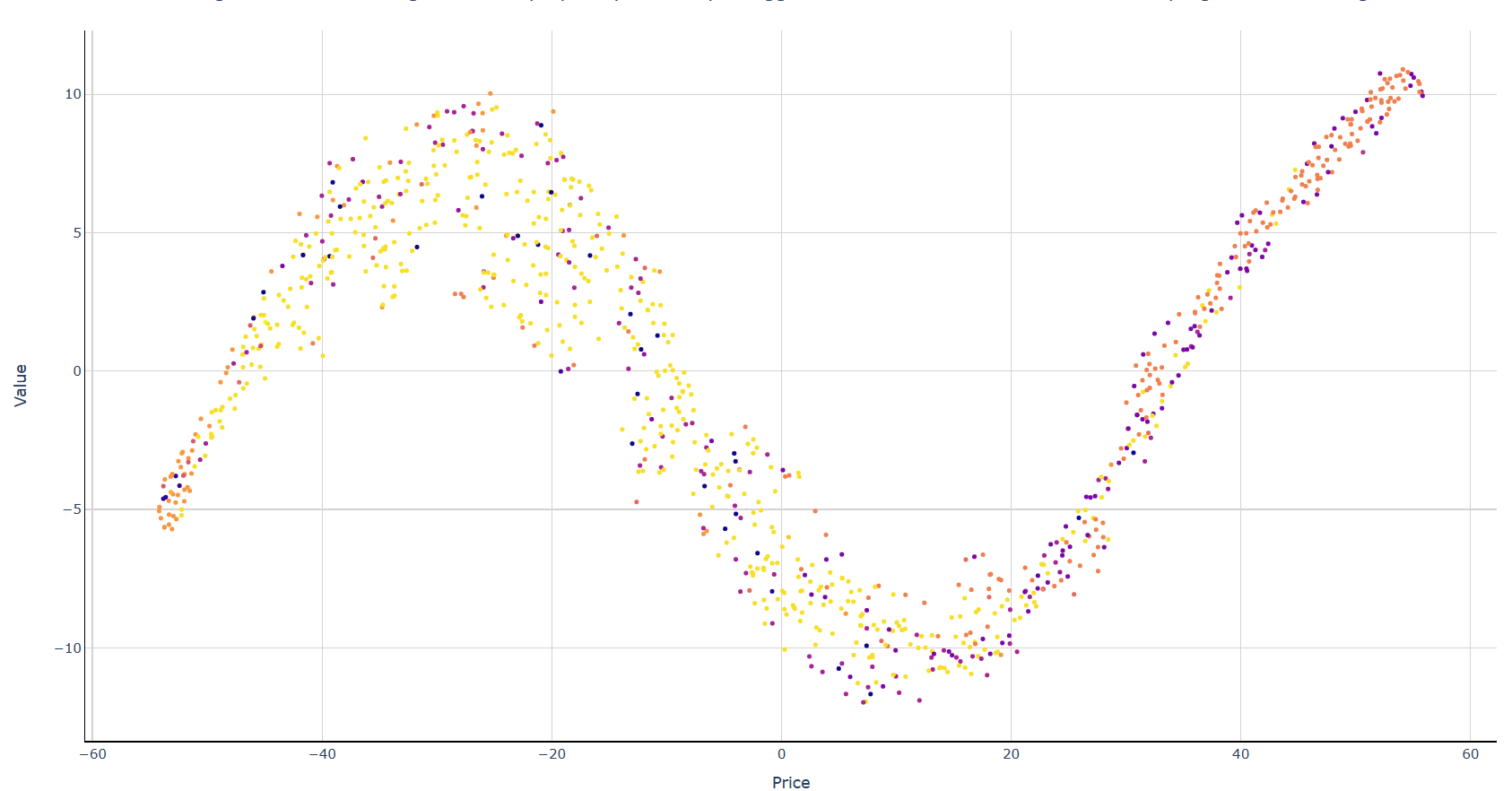
На размере данных в 15000 строк
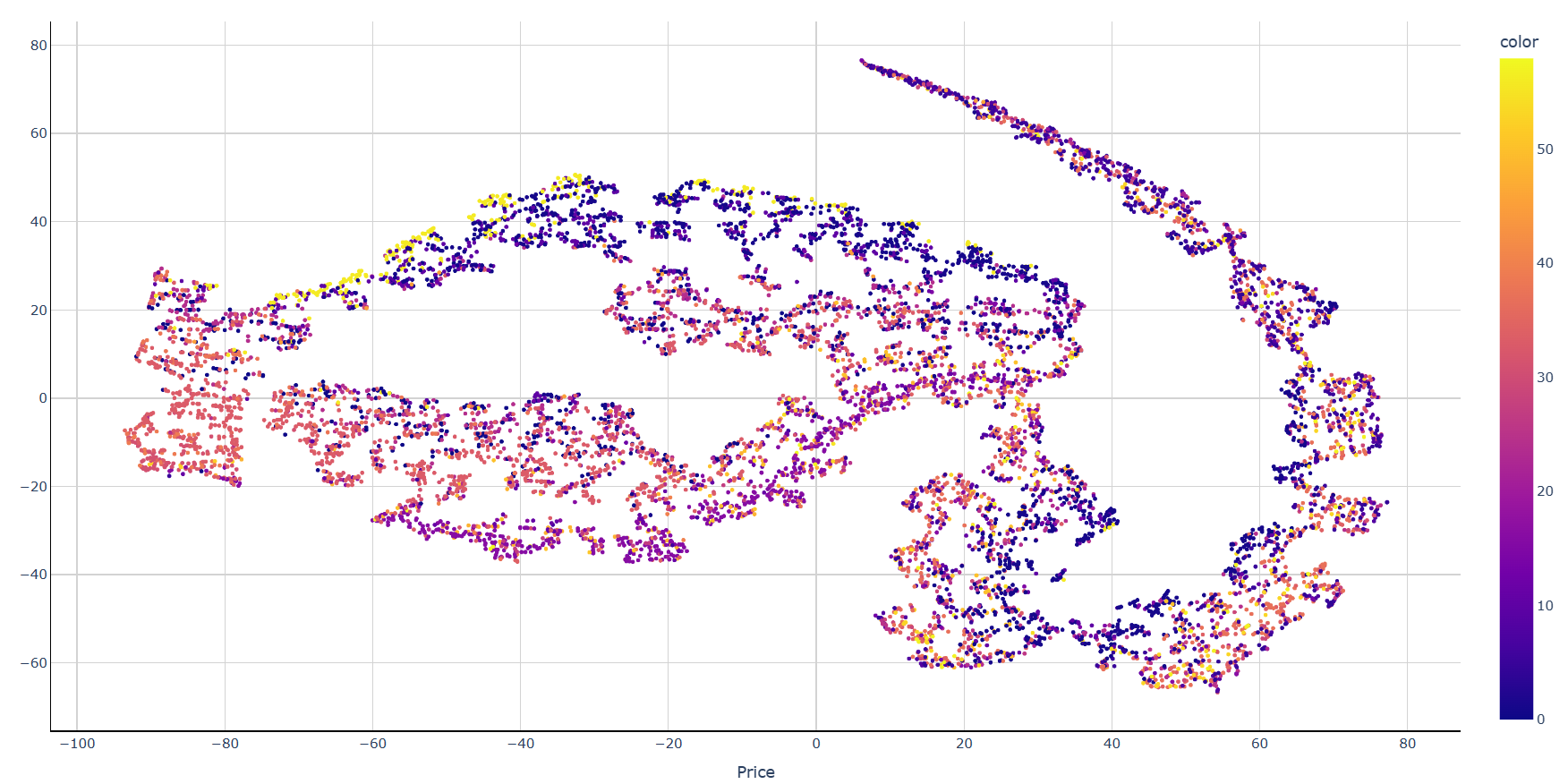
TSNE(learning_rate=200, perplexity=50, early_exaggeration=6, angle=0.1)
angle - Используется только если метод='barnes_hut' Это компромисс между скоростью и точностью в случае T-SNE с применением алгоритма Барнса-Хата. (0.5 по умолчанию)
На размере данных в 1000 строк
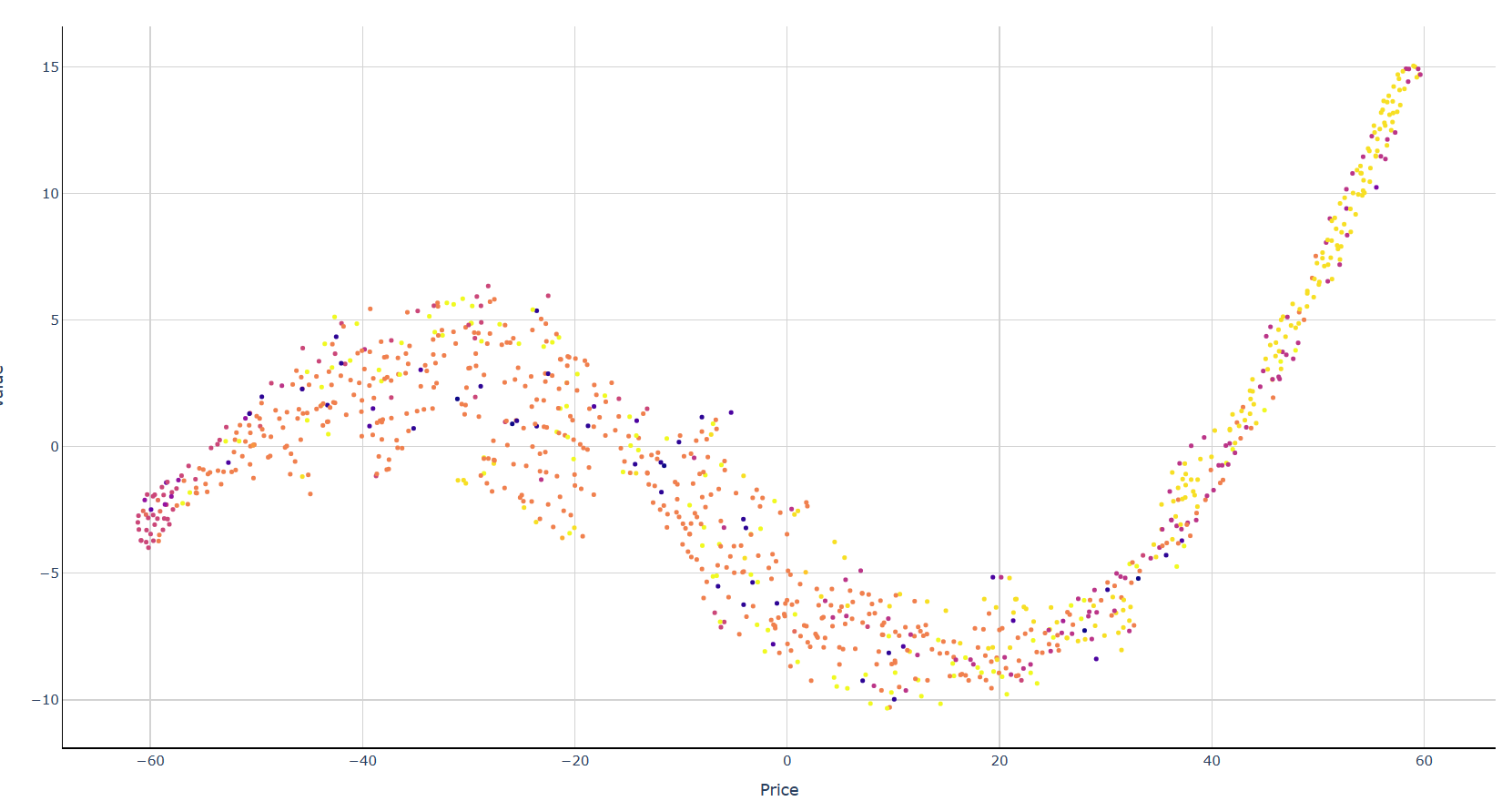
На размере данных в 15000 строк
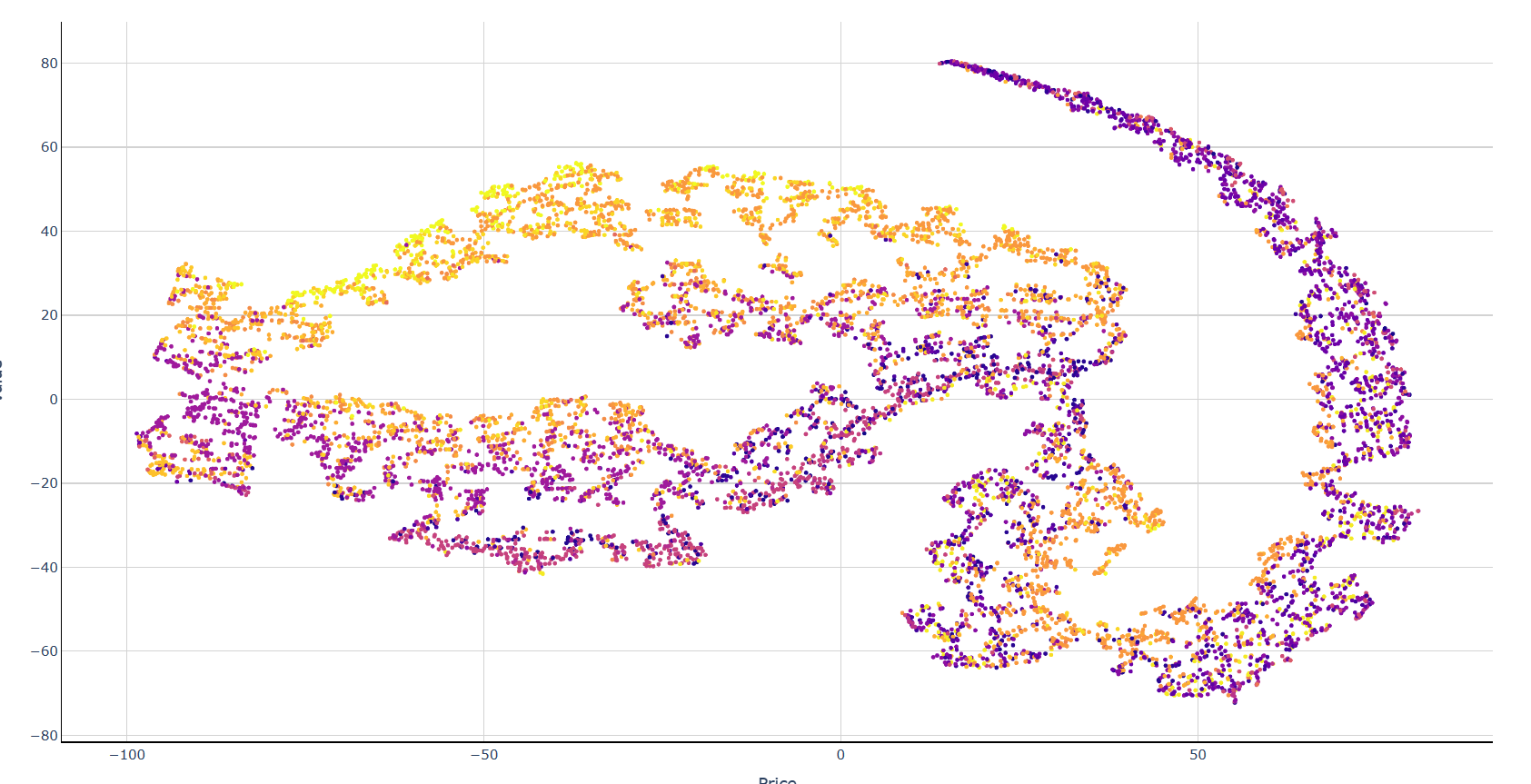
Выводы: Чем больше данных, тем лучше алгоритм выделяет кластеры. Настроив параметры алгоритма удалось достичь улучшения результата, но качество все равно можно считать неполностью удовлетворительным, так как кластеры выделяются с заметным уровнем шума. Другие методы кластеризации справляются лучше, если провести дополнительный эксперимент, то можно четко выделить ценовые диапазоны, например:
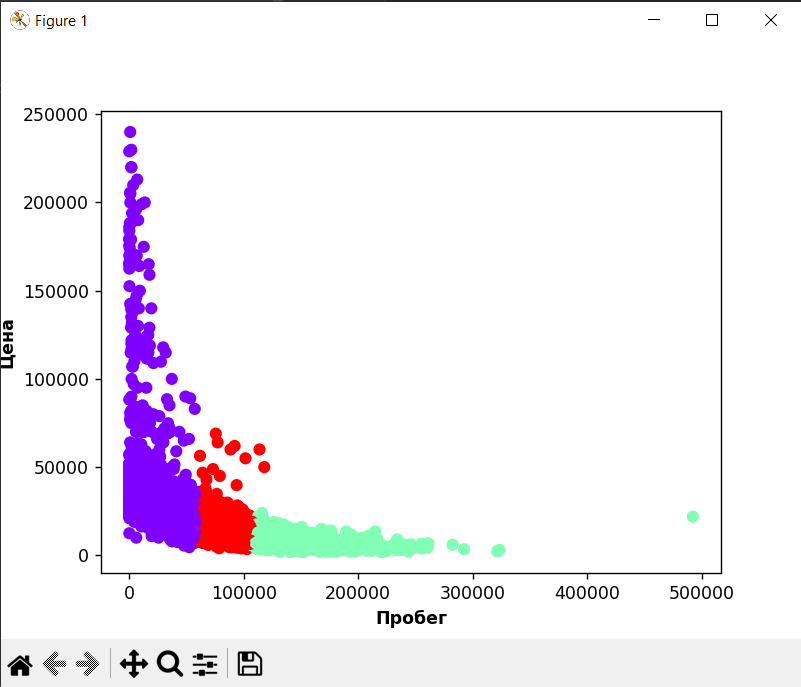
Ценовые диапазоны по пробегу
Ценовые диапазоны по году выпуска
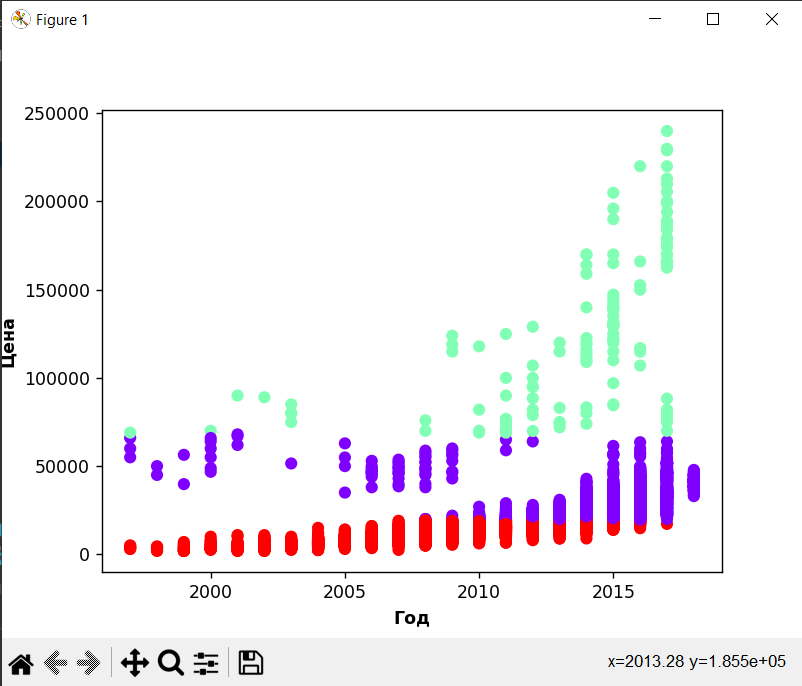
В данных примерах можно особенно точно проследить зависимость между параметрами
Итоговые выводы
Алгоритм t-SNE визуальный и точность определяется восприятием графика. Поэтому использовать его лучше только в целях визуализации. Для данной задачи алгоритм не подходит, так как решает её недостаточно качественно.