{kind=link}
{kind=link}
Лабораторная работа 3. Деревья решений
Задание на лабораторную:
Часть 1. По данным о пассажирах Титаника решите задачу классификации (с помощью дерева решений), в которой по различным характеристикам пассажиров требуется найти у выживших пассажиров два наиболее важных признака из трех рассматриваемых (по варианту).
Вариант 7. Ticket,Fare,Cabin
Часть 2. Решите с помощью библиотечной реализации дерева решений задачу из лабораторной работы «Веб-сервис «Дерево решений» по предмету «Методы искусственного интеллекта» на 99% ваших данных. Проверьте работу модели на оставшемся проценте, сделайте вывод.
Как запустить лабораторную работу:
Для запуска первой части лабораторной работы необходимо открыть файл laba3_titanic.py, нажать на ПКМ и в выпадающем списке выбрать опцию "Run". Для запуска второй части - то же самое, но файл "laba3_economica"
Технологии:
NumPy (Numerical Python) - это библиотека для научных вычислений в Python, которая обеспечивает эффективные вычисления и манипуляции с данными.
Pandas - это библиотека на языке Python, которая предоставляет удобные и эффективные инструменты для обработки и анализа данных. Она предоставляет высокоуровневые структуры данных, такие как DataFrame, которые позволяют легко и гибко работать с табличными данными.
Scikit-learn (Sklearn) - это библиотека для языка программирования Python, которая предоставляет инструменты для разработки и применения различных алгоритмов машинного обучения, включая классификацию, регрессию, кластеризацию, снижение размерности и многое другое. Scikit-learn также предлагает функции для предобработки данных, оценки моделей и выбора наилучших параметров.
Что делает лабораторная работа:
Часть 1:
- Загружается выборка из файла titanic_data.csv с помощью пакета Pandas
- Отбирается в выборку 3 признака: Ticket,Fare,Cabin
- Определяется целевая переменная (Survived)
- Обучается решающее дерево
- Выводятся важности признаков
Часть 2: Код использует дерево решений для прогнозирования цены на нефть на основе страны и года. Данные разделены на тренировочный (99%) и тестовый (1%) наборы. Модель обучается на тренировочных данных и оценивается на тестовых данных. Затем модель применяется к оставшимся 1% данных для дополнительной оценки. Результаты выражены в процентах ошибки относительно среднего значения цены на нефть.
Пример выходных данных:
Часть 1:

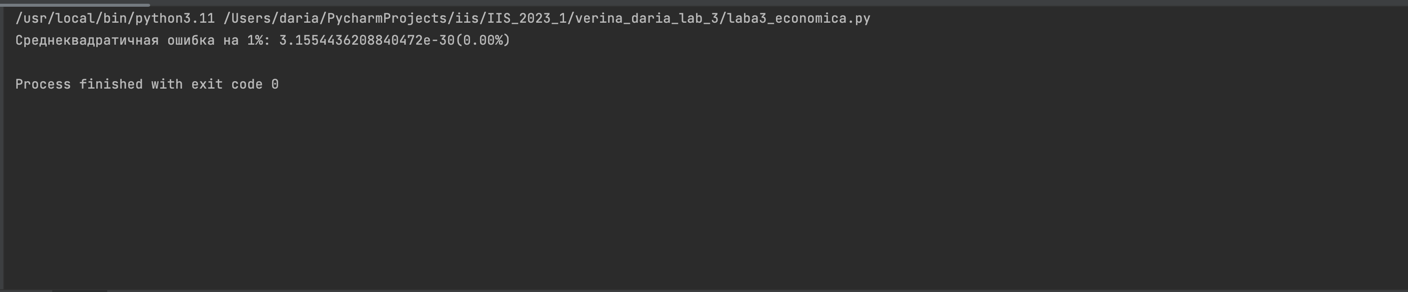
Часть 2:
Вывод: результаты первой части лабораторной работы показали, что у выживших пассажиров наиболее важными признаками являются Fare и Ticket.
Во второй части лаб. работы ошибка составила 3.1554436208840472e-30 (очень близка к нулю), это означает, что модель идеально соответствует тестовым данным. Она абсолютно точно предсказывает цены на нефть на тестовом наборе.