7.2 KiB
Лабораторная работа №6
ПИбд-42 Машкова Маргарита (Вариант 19)
Задание
Выбрать англоязычный и русскоязычный художественные тексты и обучить на нем рекуррентную нейронную сеть для решения задачи генерации. Подобрать архитектуру и параметры так, чтобы приблизиться к максимально осмысленному результату.
Данные:
Художественные тексты в файлах english_text.txt и russian_text.txt.
Запуск программы
Для запуска программы необходимо запустить файл main.py
Используемые технологии
Язык программирования: python
Библиотеки:
keras- библиотека для глубокого обучения. Она предоставляет простой и интуитивно понятный интерфейс для создания и обучения различных моделей машинного обучения, включая нейронные сети.numpy- предоставляет мощные инструменты для работы с многомерными массивами и выполнения математических операций над ними.
Описание работы программы
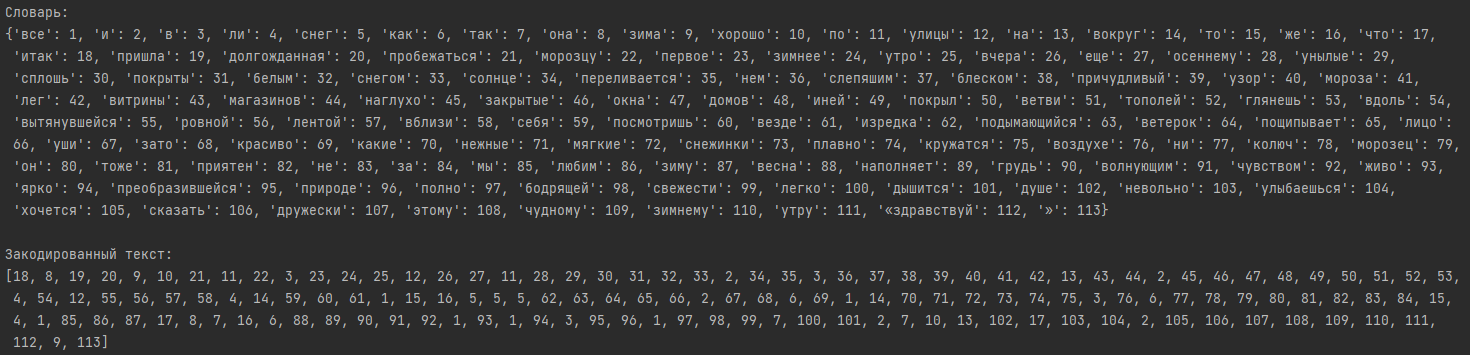
Т.к. нейронная сеть принимает на вход числа, необходимо закодировать исходные тексты.
Сделать это можно с помощью Tokenizer. Метод fit_on_texts() создает словарь вида (слово - индекс)
на основе частоты использования слов. Чем меньше индекс, тем чаще встречается слово.
Метод texts_to_sequences() преобразовывает текст в последовательность чисел.
Таким образом каждое слово принимает целочисленное значение.
Затем создаются входные и выходные последовательности, инициализируется, настраивается и компилируется модель. Модель обучается на данных и генерирует текст на основе начальной фразы.
Тесты
Варьирование количества слоев и эпох обучения для русскоязычного текста:
1 слой и 50 эпох обучения:
 Присутствуют осмысленные словосочетания, например,
Присутствуют осмысленные словосочетания, например, преобразившейся природе, бодрящей свежести,
ветерок поднимающийся изредка пощипывает лицо уши (хоть это должен быть и морозец, но все же)
2 слоя и 50 эпох обучения (1 вариант):
 Присутствуют осмысленные словосочетания, например,
Присутствуют осмысленные словосочетания, например, снежинки кружатся, наполняет чувством,
в воздухе кружатся, невольно наполняет, морозец он колюч приятен
2 слоя и 50 эпох обучения (2 вариант):
 Помимо некоторых осмысленных словосочетаний, если исключить повторы слов, можно прочесть вполне осмысленную фразу:
Помимо некоторых осмысленных словосочетаний, если исключить повторы слов, можно прочесть вполне осмысленную фразу:
невольно улыбаешься, хочется сказать дружески этому зимнему утру "здравствуй зима"
2 слоя и 100 эпох обучения:
 В данном случае присутствуют осмысленные словосочетания, и при этом эпитеты стоят рядом с нужными существительными
(подходящим по тематике),
т.е., например, снежинки -
В данном случае присутствуют осмысленные словосочетания, и при этом эпитеты стоят рядом с нужными существительными
(подходящим по тематике),
т.е., например, снежинки - мягкие, нежные, кружатся, морозец - колюч, магазины - окна,
солнце - переливается слепящим блеском и т.д.
2 слоя и 500 эпох обучения:
 Увеличение количества эпох снизило качество генерации текста.
Увеличение количества эпох снизило качество генерации текста.
Варьирование количества слоев и эпох обучения для англоязычного текста:
1 слой и 50 эпох обучения:

2 слоя и 50 эпох обучения:

2 слоя и 100 эпох обучения:

2 слоя и 500 эпох обучения:

В данном случае видно, что увеличение количество слоев и эпох положительно влияет на генерацию текста.
Вывод: т.к. кодировались в числа не буквы, а слово, для оценки работы модели нужно обращать внимание на осмысленность условных предложений, а не самих слов. Увелечение количества слоев привело к более хорошему результату для обоих текстов.
Для русскоязычного текста увеличение количества эпох обучения не сильно улучшает результат, а иногда даже ухудшает. Скорее всего, потому что данных не так много и они разнообразные, и размер потерь не сильно уменьшается в каждой эпохе обучения.
Для англоязычного текста увеличение количества эпох привело к сильному улучшению результата
(как минимум, сократились повторения одних и тех же слов подряд).
Скорее всего, потому что частота встречаемости слов, таких как, например, gingerbread, cookies, слишком большая,
и поэтому малообученная модель их часто использует.
Для русскоязычного текста генерация текста выполнилась сильно лучше, чем для англоязычного.