{kind=link}
Лабораторная 3
Вариант 9
Задание
Использовать метод кластеризации t-SNE,самостоятельно сформулировав задачу. Интерпретировать результаты и оценить, насколько хорошо он подходит для решения сформулированной вамизадачи.
Задача:
- Можно использовать кластеризацию для группировки компаний на основе их местоположения (company_location) и размера (company_size). Это поможет выделить группы компаний с похожими характеристиками.
Описание Программы
Программа выполняет кластеризацию компаний на основе их местоположения (company_location) и размера (company_size) с использованием методов t-SNE и KMeans.
Используемые библиотеки
pandas:
Используется для загрузки данных из CSV-файла и работы с ними в виде датафрейма (pd.read_csv, pd.DataFrame).
LabelEncoder (из scikit-learn):
Применяется для преобразования категориальных переменных (company_location и company_size) в числовые значения (le.fit_transform).
TSNE (из scikit-learn):
Используется для выполнения уменьшения размерности данных с помощью метода t-SNE (TSNE(n_components=2, random_state=42)).
KMeans (из scikit-learn):
Применяется для кластеризации данных методом KMeans (KMeans(n_clusters=3, random_state=42)).
matplotlib и seaborn:
Используются для визуализации данных и построения графика, который отображает результаты кластеризации (plt.figure, sns.scatterplot, plt.title, plt.show).
Шаги программы
Загрузка данных:
Данные о компаниях загружаются из CSV-файла "ds_salaries.csv" с использованием pandas.
Преобразование категориальных переменных:
Местоположение компаний (company_location) и их размер (company_size) преобразуются из категориальных в числовые значения с помощью LabelEncoder.
Выбор признаков:
Выбираются признаки для анализа, в данном случае, местоположение и размер компаний.
Уменьшение размерности с использованием t-SNE:
Применяется метод t-SNE для уменьшения размерности данных до двух компонент.
Кластеризация данных с использованием KMeans:
Кластеризация данных выполняется с помощью метода KMeans с 3 кластерами, определенными на основе результата t-SNE.
Создание и визуализация нового датафрейма:
Создается новый датафрейм (data_tsne_df), содержащий новые координаты компаний после применения t-SNE, а также метки кластеров. Добавляется номер кластера к исходным данным.
Визуализация кластеров:
Выполняется визуализация результатов кластеризации с использованием библиотеки seaborn.
Запуск программы
- Склонировать или скачать код
main.py. - Запустите файл в среде, поддерживающей выполнение Python.
python main.py
Результаты
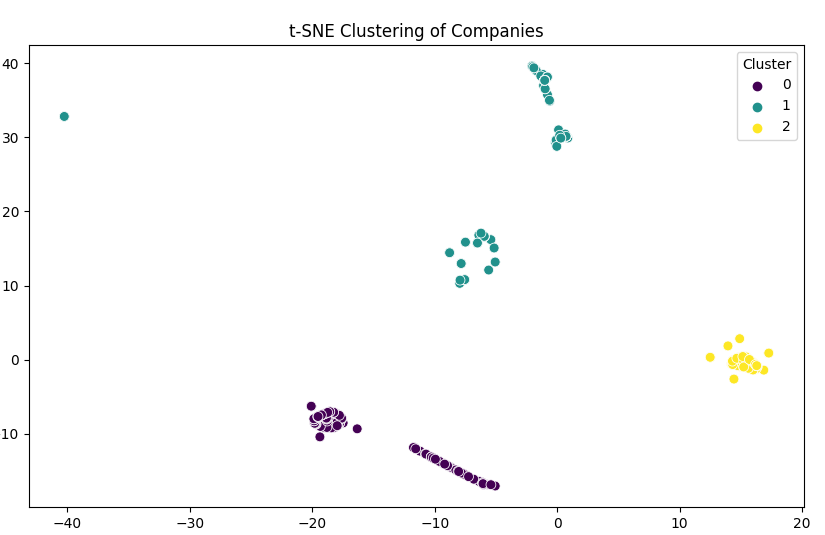
На графике представлены компании в двумерном пространстве, где каждая точка относится к конкретному кластеру. Различные цвета точек обозначают принадлежность к разным кластерам.
Кластеры можно рассматривать как группы компаний с схожими характеристиками местоположения и размера. Компании, находящиеся близко в двумерном пространстве, могут иметь схожие характеристики.