{kind=link}
{kind=link}
Вариант 2
Задание: Использовать регрессию по варианту для данных из таблицы 1 по варианту(таблица 10), самостоятельно сформулировав задачу. Оценить, насколько хорошо она подходит для решения сформулированной вами задачи
Вариант 2 Логистическая регрессия
Предсказание медианной стоимости жилья на основе всех доступных признаков.
Данные: Данный набор данных использовался во второй главе недавней книги Аурелиена Жерона "Практическое машинное обучение с помощью Scikit-Learn и TensorFlow". Он служит отличным введением в реализацию алгоритмов машинного обучения, потому что требует минимальной предварительной обработки данных, содержит легко понимаемый список переменных и находится в оптимальном размере, который не слишком мал и не слишком большой.
Данные содержат информацию о домах в определенном районе Калифорнии и некоторую сводную статистику на основе данных переписи 1990 года. Следует отметить, что данные не прошли предварительную очистку, и для них требуются некоторые этапы предварительной обработки. Столбцы включают в себя следующие переменные, их названия весьма наглядно описывают их суть:
долгота longitude
широта latitude
средний возраст жилья median_house_value
общее количество комнат total_rooms
общее количество спален total_bedrooms
население population
домохозяйства households
медианный доход median_income
Запуск: Запустите файл lab5.py
Описание программы:
Загрузка данных:
-
Используется библиотека pandas для чтения данных из CSV-файла "housing.csv" и создания DataFrame. Выбор признаков и целевой переменной:
-
Определяются признаки (X) и целевая переменная (y), где целевой переменной является "median_house_value", а признаками — все столбцы, за исключением "longitude", "latitude" и "ocean_proximity". Обработка пропущенных значений:
-
Применяется SimpleImputer с стратегией 'mean' для заполнения пропущенных значений средними значениями в признаках.
-
Применяется train_test_split для разбиения данных на обучающий, валидационный и тестовый наборы. Создание и обучение модели линейной регрессии:
-
Инициализируется и обучается модель LinearRegression на обучающем наборе. Вывод коэффициентов и пересечения:
-
Выводятся коэффициенты и пересечение линейной регрессии, найденные моделью в процессе обучения. Предсказание значений на тестовом наборе:
-
Производится предсказание значений целевой переменной на тестовом наборе с использованием обученной модели.
Оценка модели:
-
Рассчитываются значения R^2 для обучающего, валидационного и тестового наборов для оценки соответствия модели данным. Оценка качества предсказаний:
-
Рассчитываются среднеквадратичная ошибка (MSE) и корень из среднеквадратичной ошибки (RMSE) для оценки точности предсказаний. Визуализация предсказаний:
-
Строится график рассеяния для визуального сравнения фактических и предсказанных значений на тестовом наборе.
Результаты:
Выводы:
Оценка результатов:
-
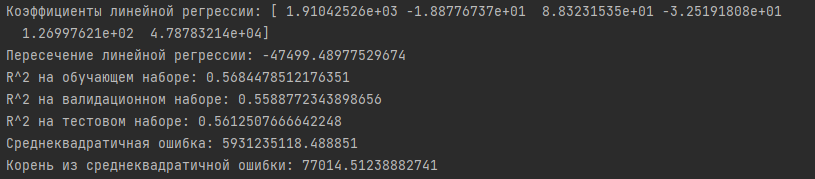
Коэффициенты линейной регрессии:
- Полученные коэффициенты для каждого признака показывают, как сильно он влияет на целевую переменную (медианную стоимость жилья). Например, положительные коэффициенты, такие как 1.91e+03 и 1.27e+02, указывают на положительную корреляцию с целевой переменной, тогда как отрицательные, например, -1.89e+01 и -3.25e+01, указывают на отрицательную корреляцию.
-
Пересечение линейной регрессии:
- Значение пересечения (-47499.49) представляет оценку целевой переменной, когда все признаки равны нулю.
-
R^2 (коэффициент детерминации):
- R^2 измеряет, насколько хорошо модель соответствует данным. Значения около 0.56 для обучающего, валидационного и тестового наборов говорят о том, что модель объясняет примерно 56% дисперсии в данных. Это приемлемый результат, но есть пространство для улучшений.
-
Среднеквадратичная ошибка (MSE) и корень из среднеквадратичной ошибки (RMSE):
- MSE составляет 5,931,235,118.49, что является среднеквадратичной разницей между фактическими и предсказанными значениями. RMSE (77014.51) представляет собой среднюю ошибку в предсказаниях в единицах целевой переменной.
Общий вывод: Результаты говорят о том, что модель демонстрирует неплохое соответствие данным, но есть возможность для улучшений.