{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Лабораторная работа №3
ПИбд-42 Машкова Маргарита (Вариант 19)
Задание
Решить с помощью библиотечной реализации дерева решений на 99% данных задачу: Выявить зависимость стоимости телефона от других его признаков. Проверить работу модели на оставшемся проценте, сделать вывод.
Данные:
Датасет о характеристиках мобильных телефонов и их ценах
Ссылка на датасет в kaggle: Mobile Phone Specifications and Prices
Модели:
- DecisionTreeClassifier
Запуск программы
Для запуска программы необходимо запустить файл main.py
Используемые технологии
Язык программирования: python
Библиотеки:
pandas- предоставляет функциональность для обработки и анализа набора данных.sklearn- предоставляет широкий спектр инструментов для машинного обучения, статистики и анализа данных.
Описание работы программы
Описание набора данных
Данный набор содержит характеристики различных телефонов, в том числе их цену.
Названия столбцов набора данных и их описание:
- Id - идентификатор строки (int)
- Name - наименование телефона (string)
- Brand - наименование бренда телефона (string)
- Model - модель телефона (string)
- Battery capacity (mAh) - емкость аккумулятора в мАч (int)
- Screen size (inches) - размер экрана в дюймах по противоположным углам (float)
- Touchscreen - имеет телефон сенсорный экран или нет (string - Yes/No)
- Resolution x - разрешение телефона по ширине экрана (int)
- Resolution y - разрешение телефона по высоте экрана (int)
- Processor - количество ядер процессора (int)
- RAM (MB) - доступная оперативная память телефона в МБ (int)
- Internal storage (GB) - внутренняя память телефона в ГБ (float)
- Rear camera - разрешение задней камеры в МП (0, если недоступно) (float)
- Front camera - разрешение фронтальной камеры в МП (0, если недоступно) (float)
- Operating system - ОС, используемая в телефоне (string)
- Wi-Fi - имеет ли телефон функция Wi-Fi (string - Yes/No)
- Bluetooth - имеет ли телефон функцию Bluetooth (string - Yes/No)
- GPS - имеет ли телефон функцию GPS (string - Yes/No)
- Number of SIMs - количество слотов для SIM-карт в телефоне (int)
- 3G - имеет ли телефон сетевую функкцию 3G (string - Yes/No)
- 4G/ LTE - имеет ли телефон сетевую функкцию 4G/LTE (string - Yes/No)
- Price - цена телефона в индийских рупиях (int)
Обработка данных
Выведем информацию о данных при помощи функции DataFrame data.info():
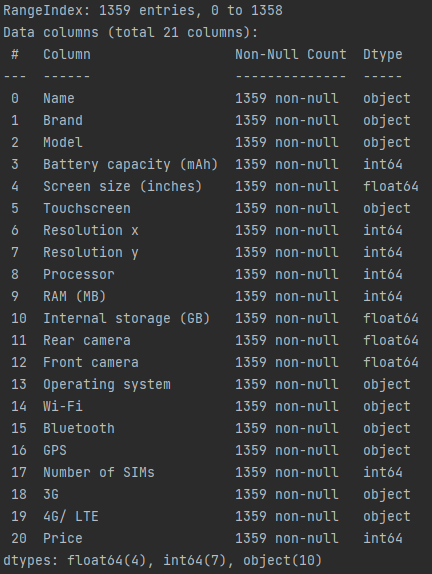
Данные не содержат пустых строк. Все значения в столбцах необходимо привести к численным значениям.
Для преобразования полей, содержащих значения Yes/No воспользуемся числовым кодированием LabelEncoder.
Значение "Yes" станет равным 1, значение "No" - 0.
Остальные строковых поля будем преобразовывать при помощи векторайзер с суммированием TfidfVectorizer.
Данные после обработки:
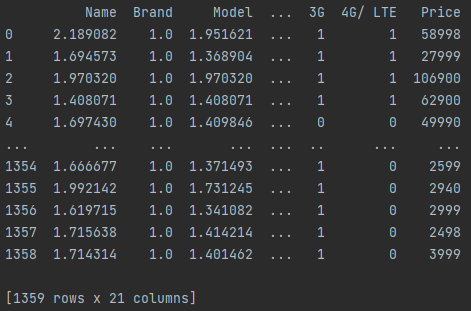
Далее создается Y - массив значений целового признака (цены). Задача классификации решается дважды: сначала на всех признаках, затем на выявленных четырех важных. Сначала в X передаются все признаки, выборка разделяется на тестовые (1%) и обучающие данные (99%), модель дерева решений обучается, отображаются список важности признаков (по убыванию) и оценка модели. Затем из списка берутся первые 4 признаки и задача решается повторно.
Тесты
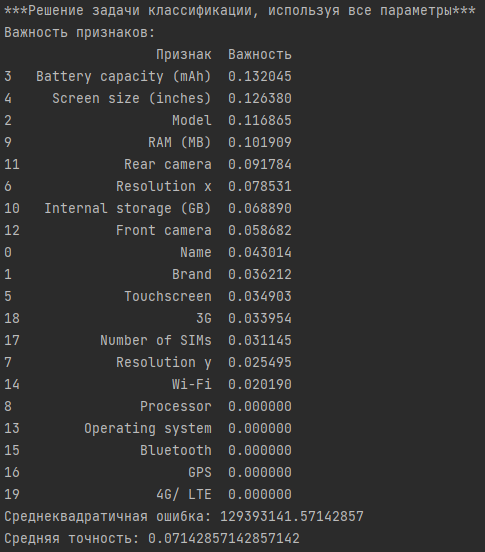
Результат решения задачи классификации на всех признаках:
Результат решения задачи классификации на выявленных четырех важных признаках:
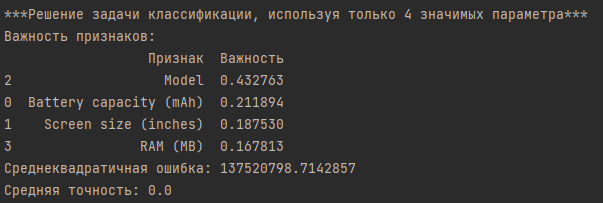
Вывод: исходя из полученных результатов, средняя точность работы модели на всех признаках составляет 7%, т.е. модель работает слишком плохо на данных. При выборе только важных признаков средняя точность падает до 0. Большое значение среднеквадратичной ошибки подтверждает тот факт, что модель имеет низкое качество.