5.4 KiB
Лабораторная №1. Вариант №21
Тема:
Работа с типовыми наборами данных и различными моделями
Задание:
Сгенерировать определённый тип данных, сравнить на нём разные модели и отобразить качество на графиках.
Данные: make_classification (n_samples=500, n_features=2, n_redundant=0, n_informative=2, random_state=rs, n_clusters_per_class=1)
Модели:
- Линейная регрессия
- Полиномиальная регрессия (со степенью 5)
- Гребневая полиномиальная регрессия (со степенью 5, alpha = 1.0)
Как запустить программу?
Необходимо запустить файл main.py
Использованные технологии
Этот код использует несколько библиотек и технологий для создания синтетических данных, обучения различных моделей регрессии и визуализации результатов. Вот краткое описание использованных технологий:
-
NumPy - это библиотека для работы с массивами и матрицами чисел. Она используется для создания и манипуляции данными.
-
Matplotlib - это библиотека для создания графиков и визуализации данных. Она используется для отображения данных на графиках.
-
Scikit-learn - это библиотека машинного обучения, которая предоставляет множество инструментов для обучения моделей и анализа данных. В этом коде используются следующие модули из этой библиотеки:
- make_classification - используется для генерации синтетических данных классификации.
- train_test_split - используется для разделения данных на обучающий и тестовый наборы.
- linearRegression - используется для создания и обучения линейной регрессии.
- polynomialFeatures - используется для создания полиномиальных признаков.
- ridge - используется для создания и обучения гребневой полиномиальной регрессии.
- r2_score - используется для вычисления коэффициента детерминации модели.
Описание работы
Сначала программа использует функцию make_classification для создания синтетических данных. Эти данные представляют собой два признака и являются результатом задачи классификации. Всего создается 500 точек данных.
Сгенерированные данные разделяются на обучающий и тестовый наборы с использованием функции train_test_split. Обучающий набор содержит 80% данных, а тестовый набор - 20%.
Далее прооисходит обучение моделей. Для каждой строятся графики, на которых отображаются тестовые данные и предсказанные значения для оценки, насколько хорошо модель соответствует данным.
Для каждой модели программа вычисляет коэффициент детерминации с использованием функции r2_score.
Программа создает, обучает и визуализирует три модели регрессии и позволяет оценить их производительность на сгенерированных данных.
Выходные данные
Была выведена следующая точность у моделей:
Линейная регрессия с точностью 0.52
Полиномиальная регрессия с точностью -0.20
Гребневая полиномиальная регрессия с точностью -0.09
Графики результатов построены следующим образом:
- Линейная регрессия

- Полиномиальная регрессия
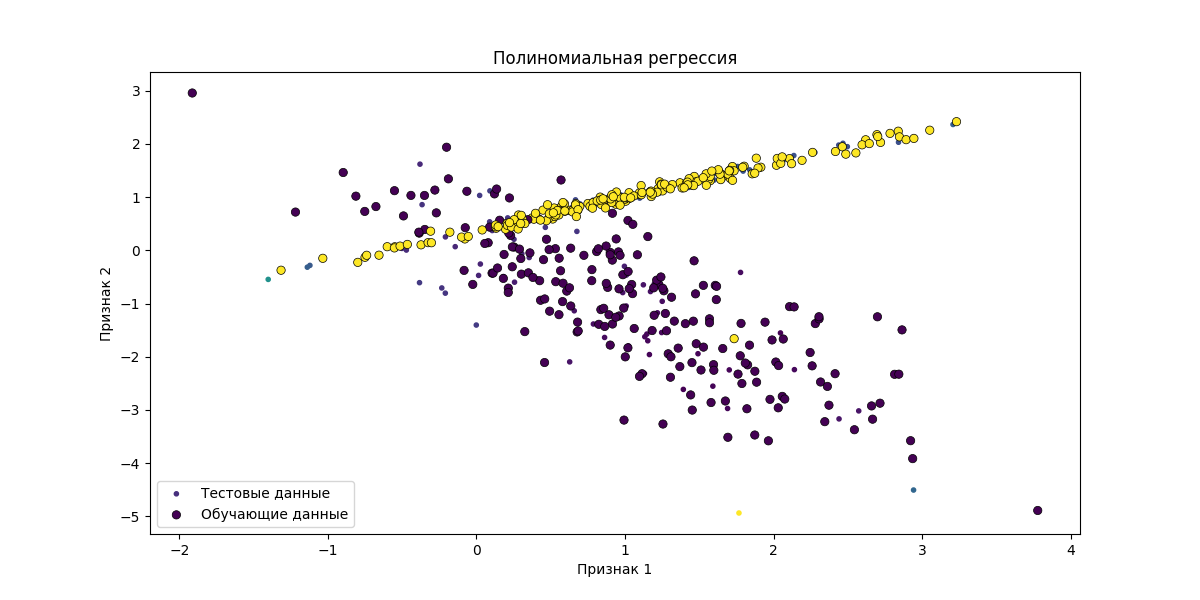
- Гребневая полиномиальная регрессия

Линейная регрессия показала наилучшую точность с точностью, равной 0.52, что указывает на приемлемую предсказательную способность модели. Полиномиальная и гребневая полиномиальная регрессии со значениями -0.20 и -0.09 соответственно, демонстрируют низкую точность.