5.3 KiB
Лабораторная работа №5. Вариант 21
Тема:
Регрессия
Модель:
LinearRegression
Как запустить программу:
Установить python, numpy, matplotlib, sklearn
python lab.py
Какие технологии использовались:
Язык программирования Python, библиотеки numpy, matplotlib, sklearn
Среда разработки VSCode
Что делает лабораторная работа:
Поскольку артериальное давление пациента в состоянии покоя является важным медицинским показателем, оно было выбрано для предсказания на основе доступных признаков, таких как возраст, пол и других.
Внедрение линейной регрессии в решение задачи прогнозирования артериального давления в состоянии покоя приносит несколько ключевых преимуществ.
Линейная регрессия является мощным инструментом в области статистики и машинного обучения, широко применяемым для анализа и моделирования связей между зависимыми и независимыми переменными. Ее основная цель — построить линейную функцию, наилучшим образом приближающую отношение между входными данными и целевой переменной. Это позволяет предсказывать значения целевой переменной на основе новых входных данных.
Описание:
LinearRegression - метод наименьших квадратов (MSE) – это основной принцип LinearRegression. Он стремится минимизировать сумму квадратов разностей между фактическими и предсказанными значениями. Этот алгоритм предоставляет аналитическое решение для определения коэффициентов линейной модели, что делает его эффективным и простым для понимания.
Процесс обучения линейной регрессии требует выполнения следующих шагов:
1. Получить исходные данные
2. Выбрать целевое значение, которые нужно предсказывать
3. Обработать данные таким образом, чтобы все признаки имели только числовой формат, и добавить нормализацию, или иначе, стандартизацию данных
4. 4. Провести обучение выбранной модели на подготовленных данных
Обработка данных происходит с помощью функции str_features_to_numeric:
def str_features_to_numeric(data):
# Преобразовывает все строковые признаки в числовые.
# Определение категориальных признаков
categorical_columns = []
numerics = ['int8', 'int16', 'int32', 'int64', 'float16', 'float32', 'float64']
features = data.columns.values.tolist()
for col in features:
if data[col].dtype in numerics: continue
categorical_columns.append(col)
# Кодирование категориальных признаков
for col in categorical_columns:
if col in data.columns:
le = LabelEncoder()
le.fit(list(data[col].astype(str).values))
data[col] = le.transform(list(data[col].astype(str).values))
return data
Далее происходит нормализация с помощью StandardScaler.
В качестве целевого признака был выбран артериальное давление в состоянии покоя trestbps- артериальное давление в состоянии покоя (в мм рт. ст. при поступлении в больницу). Обработанные данные поступают на вход обучения модели линейной регресии:
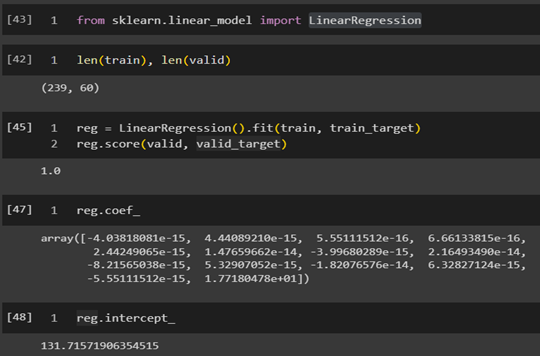
- reg.score_ - отображает точность работы модели
- reg.coef_ - отображает коэффициенты при признаках расположенных по порядку
- reg.intercept_ - показывает параметр смещения (в английской литературе bias)
Вывод
На основе полученных результатов, можно сказать, что классическая модель линейной регрессии является более чем подходящей для решения именно этой конкретной задачи