| .. | ||
| .gitignore | ||
| img_1.png | ||
| img.png | ||
| README.md | ||
| senkin_alexander_lab_3.py | ||
| us_tornado_dataset_1950_2021.csv | ||
{kind=link}
{kind=link}
Лабораторная №3
Вариант №2
Задание на лабораторную:
Решите с помощью библиотечной реализации дерева решений задачу: Запрограммировать дерево решений как минимум на 99% ваших данных для задачи: Количество жертв(inj) от года(yr), магнитуды(mag) и фатальных исходов(fat) от торнадо. Проверить работу модели на оставшемся проценте, сделать вывод.
Как запустить лабораторную работу:
Чтобы увидеть работу программы, нужно запустить исполняемый питон файл senkin_alexander_lab_3.py, после чего в консоли будут выведены первые 5 строк данных, показатель score насколько хорошо модель соответсвует данным, все признаки, их ранжирование, а также среднюю ошибку.
Библиотеки
Sklearn. Предоставляет инструменты и алгоритмы, которые упрощают задачи, связанные с машинным обучением.
Описание программы:
- Загружаем данные из csv файла
- С помощью функции train_test_split разделяем данные на тестовые и обучающие в соотношении 1 к 99
- Добавляем две модели для сравнения их работы:
- Дерево решений(по заданию)
- Линейная регрессия(более подходящая модель)
- Обучаем модели
- вывод ранжированные признаки, производительность модели и среднюю ошибку
Программа выдает следующие результаты:
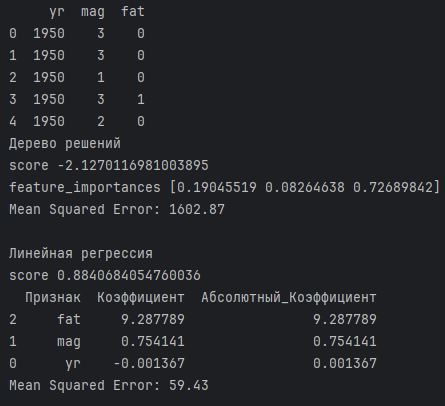
По этим результатам можно сделать вывод, что дерево решений не подходит для указанных данных, так как оценка производительности уходит в минус, а средняя квадратичная ошибка очень большая. Для данной модели больше подходит линейная регрессия, которая имеет неплохую производительность 0.88, хотя для этих данных имеет все же немаленькую ошибку. Поэтому было решено ранжировать признаки по модели линейной регрессии, и из 3 признаков самым бесполезным оказался признак года, а самым полезным - признак смертности.