| .. | ||
| img.png | ||
| main.py | ||
| README.md | ||
{kind=link}
IIS_2023_1
Задание
Используя код из [1](пункт «Решение задачи ранжирования признаков», стр. 205), выполните ранжирование признаков с помощью указанных по варианту моделей. Отобразите получившиеся значения\оценки каждого признака каждым методом\моделью и среднюю оценку. Проведите анализ получившихся результатов. Какие четыре признака оказались самыми важными по среднему значению? (Названия\индексы признаков и будут ответом на задание).
9.
- Лассо (Lasso)
- Сокращение признаков случайными деревьями (Random Forest Regressor)
- Линейная корреляция (f-regression)
Способок запуска программы
Запустить скрипт shadaev_anton_lab_2/main.py, после чего в консоль будут выведены результаты выполнения программы.Стек технологий
- NumPy - это библиотека Python, предоставляющая поддержку для больших, многомерных массивов и матриц, а также набор функций для их манипуляции и обработки.
- Sklearn - предоставляет ряд инструментов для моделирования данных, включая классификацию, регрессию, кластеризацию и уменьшение размерности.
Описание кода
В этом коде мы генерируем 500 наблюдений с 15 признаками. Затем создается словарь для хранения рангов признаков для каждого метода (Lasso, Random Forest, f_regression).
Функция calculate_ranks() используется для вычисления рангов признаков для каждого метода. Для этого она обучает модель (Lasso или Random Forest) на данных и затем возвращает словарь, где ключами являются имена признаков, а значениями - коэффициенты признаков модели.
Если используется метод f_regression, функция возвращает словарь с f-статистиками признаков.
Затем функция create_normalized_rank_dict() используется для нормализации рангов признаков. Она принимает ранги и имена признаков, приводит ранги к абсолютному значению, нормализует их с использованием MinMaxScaler из sklearn.preprocessing и возвращает словарь, где ключами являются имена признаков, а значениями - нормализованные ранги.
Наконец, код вычисляет среднее значение рангов для каждого признака, сортирует признаки по средним значениям рангов в порядке убывания и выводит признаки и их ранги.
Результат:
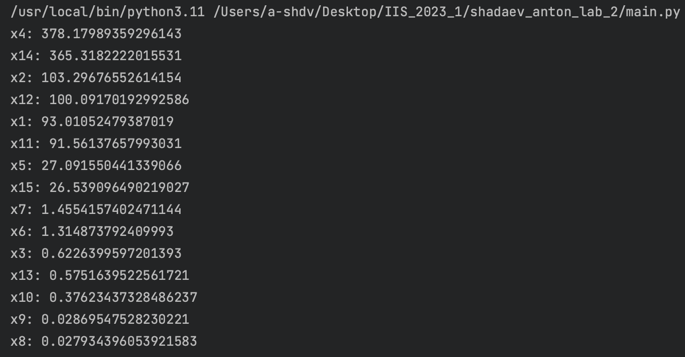
- x4, x14 - высшая значимость
- x2, x12 - средняя значимость
- x1, x11 - значимость ниже среднего
- x5, x15 - низкая значимость
- x3, x6, x7, x8, x9, x10, x13 - очень низкая значимость