{kind=link}
{kind=link}
Лабораторная работа 4
Вариант 10
Задание:
- Используя данные из "F1DriversDataset.csv" сформулировать задачу, решаемую кластеризацией: Выделить 3 группы гонщиков ("условно" легендарные, выдающиеся, обыкновенные) с похожими достижениями в гонках и определить характеристики каждой группы
Алгоритм кластеризации:
- K-means (по варианту)
Запуск
- Запустить файл lab4.py
Технологии
- Язык - 'Python'
- Библиотеки sklearn, numpy, pandas, matplotlib
Что делает
- Программа реализовывает кластеризацию алгоритмом k-means, в результате чего мы получаем 3 кластера гонщиков (с определенными характеристиками для каждого кластера)
- Программа также оценивает качество кластеризации, используя Индекс силуэта (Метрика, которая измеряет, насколько каждый объект в кластере похож на свой собственный кластер по сравнению с другими кластерами. Вычисление индекса силуэта включает в себя вычисление среднего значения коэффициента силуэта для всех объектов. Чем ближе значение индекса силуэта к 1, тем лучше кластеризация.)
- Программа выводит график, позволяющий визуально понять, как прошла кластеризация
Пример работы
Пример работы представлен в виде скриншотов:
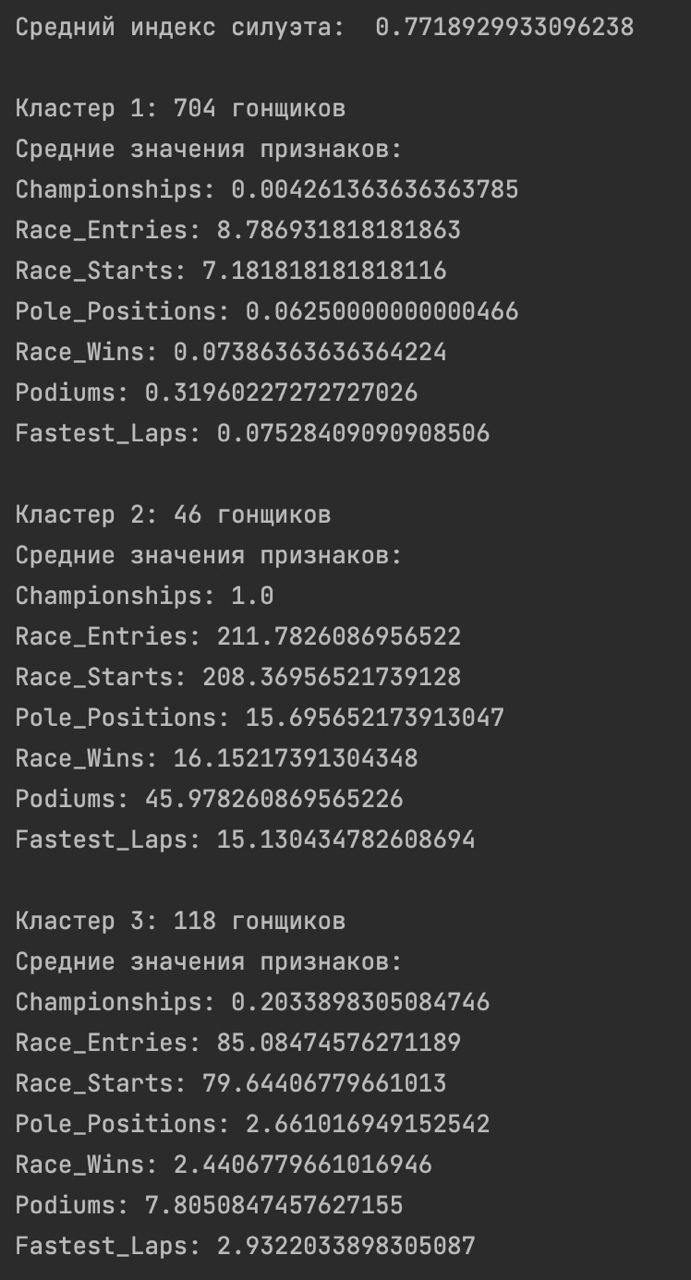
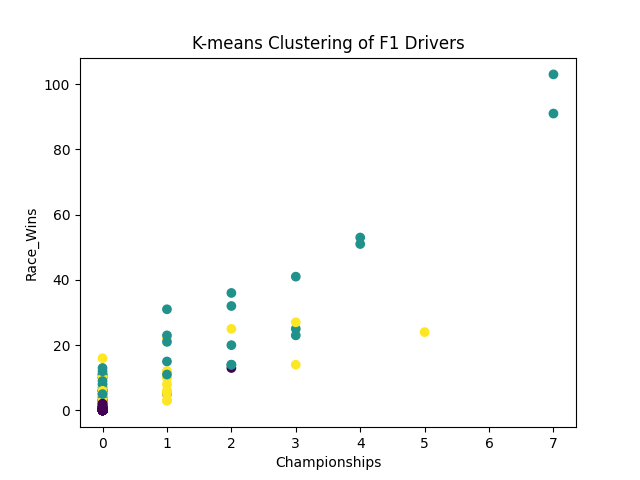
Как мы видим кластеризация помолга нам распределить гонщиков на 3 группы и определить характеристики групп, оценка качества кластеризации - 0.77, что довольно хороший показатель, значит алгоритм K-means справился со своей задачей