4.1 KiB
Задание
Использовать регрессию по варианту для данных из таблицы 1 по варианту(таблица 10),самостоятельно сформулировав задачу. Оценить, насколько хорошо она подходит для решения сформулированной вами задачи
Вариант 6 - полиномиальная регрессия
Как запустить лабораторную
Запустить файл main.py
Используемые технологии
Библиотеки pandas, matplotlib, scikit-learn, их компоненты
Описание лабораторной (программы)
Данный код берет данные из датасета о персонажах Dota 2, где описаны атрибуты персонажей, их роли, название, и как часто их пикают и какой у них винрейт на каждом звании в Доте, от реркута до титана.
В моем случае была поставлена задача предсказать винрейт персонажа по тому, как часто его берут и по его винрейту на смежных рангах (просто предсказать винрейт по тому, как часто его берут, нельзя, потому что винрейт зависит от текущей меты)
Программа берет столбцы Name, Archon Picks, Archon Win Rate, Legend Picks, Legend Win Rate, Ancient Picks, Ancient Win Rate. Все столбцы, кроме Name и Legend Win Rate, нужны для того чтобы обучить модель. Legend Win Rate - данные, которые нужно предсказать. Name - столбец для вывода результатов.
Дальше все по дефолту - программа делит данные на обучающую и тестовые выборки, просиходит применение данных для обучения, затем обучаем модель. После этого происходит то же самое с тестовыми данными и затем выводится оценка качества модели.
В конце программа строит график, где показывает точки обучающей и тестовой выборки, но к тестовой выборки я решила добавить названия персонажей, чтобы график был более наглядным, но в то же время не перегруженным.
Результат
В результате получаем график, который показывает результаты обучающей и тестовой выборок.
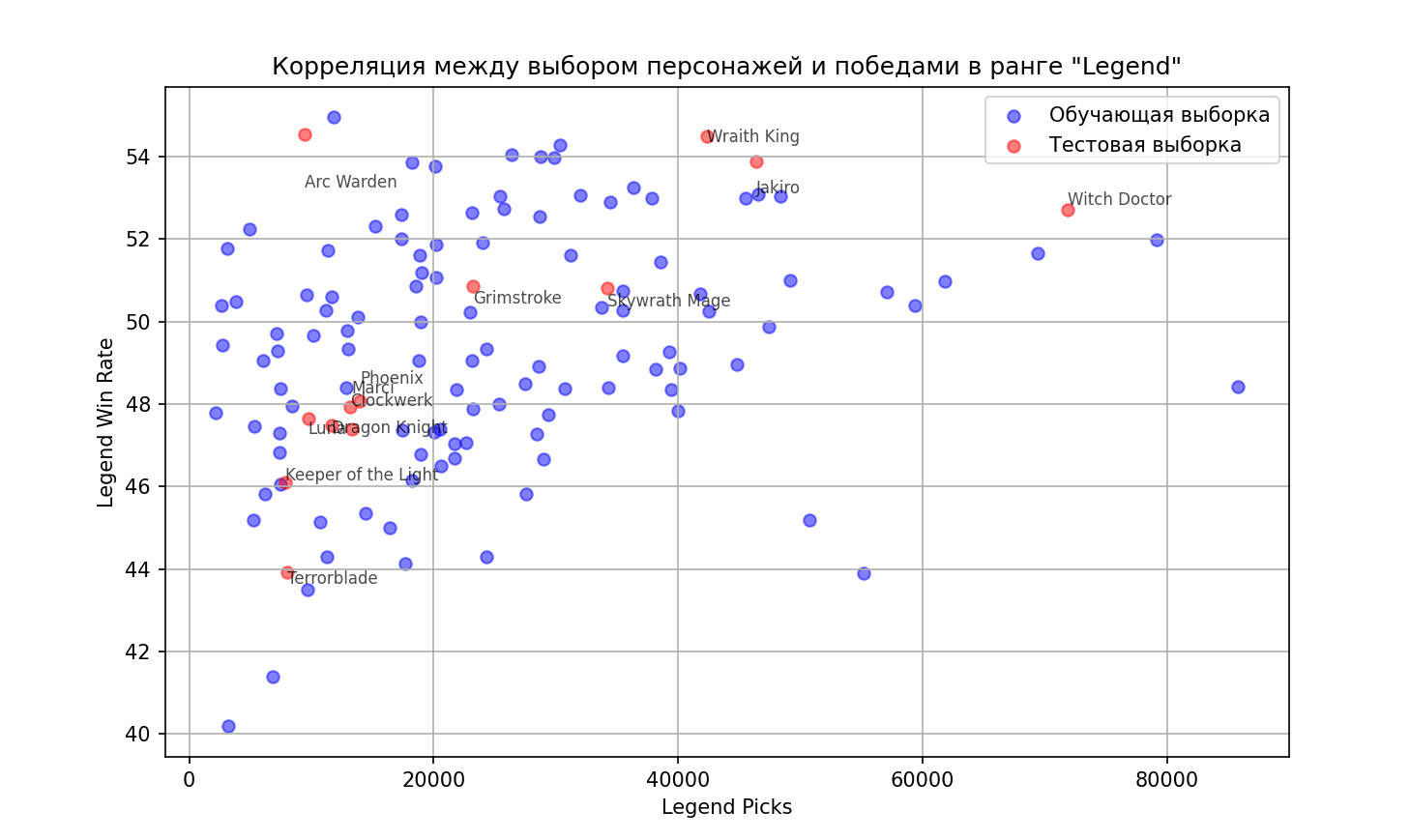
Помимо этого, программа вводит оценку качества модели:

Из чего можно сделать вывод, что модель работает очень хорошо и успешно решает поставленную задачу.
Это объясняется тем, что модели было предоставлено достаточно большое количество признаков, по которым можно предсказать интересующие нас данные. Кроме того, винрейт персонажей взят со смежных рангов.
Если взять винрейт персонажей на рангах, которые находятся далеко от целевого, модель будет работать хуже, потому что чем больше разница в рангах, тем более разный винрейт у персонажей. Также, если бы было взято меньше признаков, оценка качества модели так же была бы ниже.