{kind=link}
Лабораторная работа №5. Регрессия
14 вариант
Задание:
Использовать метод гребневой регрессиии, самостоятельно сформулировав задачу. Интерпретировать результаты и оценить, насколько хорошо он подходит для решения сформулированной вами задачи.
Описание используемого набора данных:
Объектом исследования является набор данных, который размещен на платформе Kaggle (https://www.kaggle.com/datasets/nelgiriyewithana/top-spotify-songs-2023/data). Он представляет собой полный список самых известных песен 2023 года, перечисленных на Spotify. Данный набор представлен в виде файла spotify.csv
Столбцами являются:
- track_name – Название композиции
- artist(s)_name – Имя исполнителя/имена исполнителей песни.
- artist_count – Количество исполнителей, участвовавших в со-здании песни
- released_year – Год, когда песня была выпущена
- released_month – Месяц, когда песня была выпущена
- released_day – День месяца, когда песня была выпущена.
- in_spotify_playlists – Количество плейлистов Spotify, в которые песня включена
- in_spotify_charts – Присутствие и рейтинг песни в чартах Spotify.
- streams – Общее количество прослушиваний в Spotify.
- in_apple_playlists – Количество плейлистов Apple Music, в которые песня включена.
- in_apple_charts – Присутствие и рейтинг песни в чартах Apple Music.
- in_deezer_playlists – Количество плейлистов Deezer, в ко-торые песня включена.
- in_deezer_charts – Присутствие и рейтинг песни в чартах Deezer
- in_shazam_charts – Присутствие и рейтинг песни в чартах Shazam.
- bpm – Количество ударов в минуту, показатель темпа песни.
- key – Тональность песни.
- mode – Режим песни (мажорный или минорный).
- danceability_% – Процент, указывающий, насколько песня подходит для танцев.
- valence_% - Позитивность музыкального содержания пес-ни
- energy_% - Воспринимаемый уровень энергии песни
- acousticness_% - Количество акустического звука в песне
- instrumentalness_% - Количество инструментального кон-тента в песне
- liveness_% - Наличие элементов живого исполнения
- speechiness_% - Количество произнесенных слов в песне
Задачей регрессии на данном наборе данных является прогнозирование значения столбца «in_spotify_playlists» по столбцам «streams», «in_apple_playlists», «in_deezer_playlists» и «bpm».
Запуск
- Запустить файл lab5.py
Используемые технологии
- Язык программирования Python
- Среда разработки PyCharm
- Библиотеки:
- sklearn
- matplotlib
- numpy
- pandas
Описание программы
Код программы выполняет следующие действия:
-
Импортирует необходимые библиотеки: pandas, numpy, Ridge из sklearn.linear_model, mean_absolute_error и mean_squared_error из sklearn.metrics, train_test_split из sklearn.model_selection, StandardScaler из sklearn.preprocessing.
-
Загружает данные из файла "spotify.csv" в объект DataFrame.
-
Удаляет строки с пропущенными значениями из DataFrame.
-
Удаляет столбец 'artist(s)_name' из DataFrame.
-
Удаляет запятые из значений в столбце 'in_deezer_playlists'.
-
Приводит столбец 'in_deezer_playlists' к числовому типу данных (int64).
-
Удаляет запятые из значений в столбце 'in_shazam_charts'.
-
Приводит столбец 'in_shazam_charts' к числовому типу данных (int64).
-
Создает словарь соответствия числовых значений и названий трека.
-
Заменяет значения в столбце 'track_name' на числовые, используя словарь.
-
Создает словарь соответствия числовых значений и названий тональности.
-
Заменяет значения в столбце 'key' на числовые, используя словарь.
-
Создает словарь соответствия числовых значений и режимов песни.
-
Заменяет значения в столбце 'mode' на числовые, используя словарь.
-
Создает список regrData содержащий имена столбцов для обучения модели.
-
Разделяет данные на обучающую и тестовую выборки с помощью функции train_test_split.
-
Создает объект StandardScaler и выполняет масштабирование данных обучающей и тестовой выборок.
-
Создает объект Ridge регрессора с параметром alpha=1.0.
-
Обучает регрессор на масштабированных обучающих данных.
-
Прогнозирует значения для тестовой выборки.
-
Вычисляет среднюю абсолютную ошибку (MAE) и среднеквадратичную ошибку (MSE) между фактическими и прогнозируемыми значениями.
-
Вычисляет коэффициент детерминации модели (Score).
-
Выводит значения MAE, MSE и Score на экран.
Пример работы
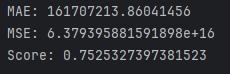
Значение метрик ошибки (MAE и MSE) и коэффициент детерминации (Score)
Вывод
Значение MAE равно 1491.2695835796214, это означает, что в среднем модель ошибается на примерно 1491 единицу при прогнозировании значений целевой переменной. Чем меньше значение MAE, тем более точные предсказания даёт модель.
Значение MSE (среднеквадратическая ошибка) равно 7440679.027329878. Оно вычисляется как среднее значение квадратов разницы между предсказанными и наблюдаемыми значениями. Чем меньше значение MSE, тем ближе предсказанные значения к наблюдаемым.
Score (оценка модели) равен 0.853940909276013. Это означает, что модель объясняет около 85.39% дисперсии в данных. Чем ближе значение score к 1, тем более точная модель.
В целом, значения MSE и score указывают на достаточно низкую точность модели. Возможно, стоит использовать другие алгоритмы или настраивать параметры текущей модели для получения более точных прогнозов.