2.5 KiB
Вариант 9
Задание на лабораторную работу:
Выполнить ранжирование признаков с помощью указанных по варианту моделей:
- Лассо (Lasso)
- Сокращение признаков Случайными деревьями (Random Forest Regressor)
- Линейная корреляция (f_regression)
Как запустить лабораторную работу:
Выполняем файл gusev_vladislav_lab_2.py, в консоль будут выведены результаты.
Технологии
NumPy - библиотека для работы с многомерными массивами. Sklearn - библиотека с большим количеством алгоритмов машинного обучения.
По коду
В начале генерируем исходные данные: 750 строк-наблюдений и 14 столбцов-признаков, задаем функцию-выход: регрессионную проблему Фридмана, добавляем зависимость признаков
Далее создаем пустой словарь для хранения рангов признаков, используем методы из библиотеки Sklearn: Lasso, RandomForestRegressor и f_regression для задания по варианту.
Далее необходимо объявить функцию def rank_to_dict(ranks, names): для соотнесения нашего списка рангов и списка оценок по признакам. Возвращает он словарь типа (имя_признака: оценка_признака) и оценки приведены к единому диапазону от 0 до 1 и округлены до сотых.
В конце формируем среднее по каждому признаку, сортируем по убыванию и выводим на экран.
Пример:
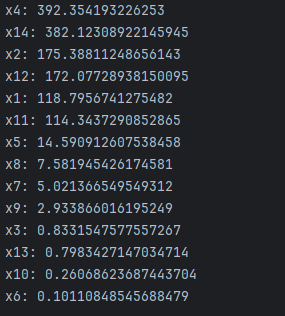
Признаки х4 и х14 имеют наивысшие ранги, что говорит об их наибольшей значимости для решения задачи
Далее x2 и x12 занимают второе место по значимости (средняя значимость)
х1, х11 ниже среднего
х5, х8, х7 низкая значимость
х9, х3, х13, х10, х6 очень низкая значимость