# Лабораторная работа №4 Вариант 25.
## Задание
Общее задание: Использовать алгоритм кластеризации `K-means`, самостоятельно сформулировав задачу. Интерпретировать результаты и оценить, насколько хорошо он подходит для решения сформулированной задачи.
Задача кластеризации: Можно ли выделить группы временных интервалов с разными уровнями активности аренды.
Ссылка на набор даных: [kaggle-bike-sharing-system](https://www.kaggle.com/datasets/itssuru/bike-sharing-system-washington-dc/?select=train_bikes.csv)
## Содержание
- [Лабораторная работа №4 Вариант 25.](#лабораторная-работа-4-вариант-25)
- [Задание](#задание)
- [Содержание](#содержание)
- [Введение](#введение)
- [Зависимости](#зависимости)
- [Запуск приложения](#запуск-приложения)
- [Описание кода](#описание-кода)
- [Заключение](#заключение)
- [Оценка работы моделей](#оценка-работы-моделей)
- [На основе предоставленных кластеров, мы можем сделать выводы:](#на-основе-предоставленных-кластеров-мы-можем-сделать--выводы)
## Введение
Данный код демонстрирует, кластеризацию временных интервалов аренды велосипедов с использованием алгоритма K-means. Целью является выделение групп временных интервалов с разными уровнями активности аренды. Скрипт использует набор данных train_bikes.csv, который включает информацию о прокате велосипедов в Вашингтоне, округ Колумбия.
## Зависимости
Для работы этого приложения необходимы следующие библиотеки Python:
- pandas
- scikit-learn
- NumPy
- Matplotlib
Вы можете установить их с помощью pip:
```bash
pip install numpy scikit-learn pandas matplotlib
```
## Запуск приложения
Чтобы запустить эту программу, выполните следующую команду:
```bash
python lab4.py
```
Откроется визуализация данных и в консоль выведется резудьтат.
## Описание кода
- Считывает данные о прокате велосипедов из CSV-файла `train_bikes.csv` и обрабатывает отсутствующие значения, удаляя соответствующие строки.
- Извлечение признаков: Извлекает необходимые признаки, включая дату и время, а также количество арендованных велосипедов. Создает копию DataFrame для избежания предупреждения `SettingWithCopyWarning`.
```python
X = data[['datetime', 'count']].copy()
```
- Преобразование времени: Преобразует признак даты и времени в часы дня, что является важным для кластеризации на основе временных интервалов.
```python
X['datetime'] = pd.to_datetime(X['datetime'])
X['hour'] = X['datetime'].dt.hour
```
- Предварительная обработка данных: Масштабирует признаки с использованием `StandardScaler` для обеспечения их схожести.
- Кластеризация: Использует алгоритм K-means для разделения временных интервалов на три группы на основе часа дня и количества аренды. Явно устанавливает параметр n_init, чтобы избежать предупреждения о будущих изменениях.
```python
X.loc[:, 'cluster'] = KMeans(n_clusters=3, random_state=42, n_init=10).fit_predict(X_scaled)
```
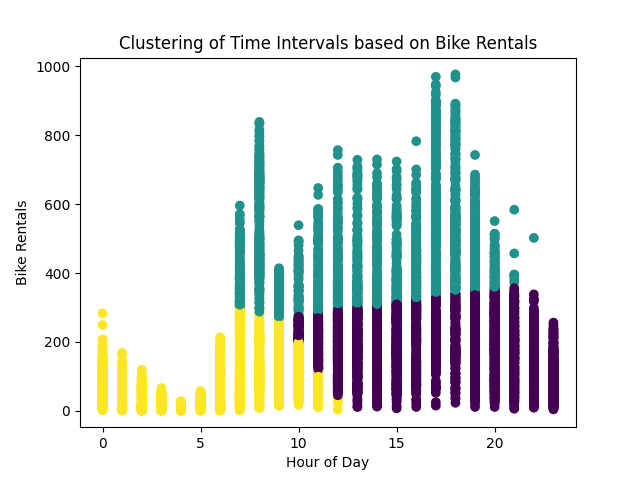
- Визуализация: Строит точечную диаграмму для визуализации результатов кластеризации. Каждая точка представляет временной интервал и окрашена в цвет, соответствующий присвоенному кластеру.
- Выводит в консоль сводку кластеров, вычисляя описательные статистики для количества аренды в каждом кластере.
## Заключение
### Оценка работы моделей
Точечная диаграмма и сводка кластеров предоставляют представление о различных паттернах активности аренды велосипедов в течение дня. Анализ этих кластеров может помочь выявить пиковые часы спроса и адаптировать стратегии распределения ресурсов или маркетинговые действия.
<table>
<thead>
<tr>
<th>Кластер</th>
<th>Количество наблюдений</th>
<th>Среднее кол-во аренд велосипедов</th>
<th>Стандартное отклонение</th>
<th>Минимум аренды</th>
<th>25-й перцентиль</th>
<th>Медиана</th>
<th>75-й перцентиль</th>
<th>Максимум аренды</th>
</tr>
</thead>
<tbody>
<tr>
<td>0</td>
<td>4193</td>
<td>171.52</td>
<td>81.48</td>
<td>4</td>
<td>106</td>
<td>171</td>
<td>235</td>
<td>356</td>
</tr>
<tr>
<td>1</td>
<td>2328</td>
<td>474.83</td>
<td>139.73</td>
<td>272</td>
<td>367</td>
<td>441</td>
<td>555</td>
<td>977</td>
</tr>
<tr>
<td>2</td>
<td>4365</td
><td>59.77</td>
<td>67.05</td>
<td>1</td>
<td>9</td>
<td>30</td>
<td>94</td>
<td>301</td>
</tr>
</tbody>
</table>
### На основе предоставленных кластеров, мы можем сделать выводы:
1. **Утренний период (Кластер 2):**
- Низкий уровень аренды: Утренний период (вероятно, от раннего утра до полудня) характеризуется низким уровнем аренды велосипедов. Это может быть связано с тем, что люди предпочитают другие виды транспорта или не активно пользуются велосипедами в этот период.
2. **Пиковый период (Кластер 1):**
- Высокий спрос в пиковый час: В это время наблюдается высокий уровень аренды велосипедов, вероятно, в часы пик, когда люди двигаются в/из работы или в другие места активности. Бизнес может сфокусироваться на предоставлении дополнительных услуг, улучшении инфраструктуры или рекламе в это время.
3. **Вечерний период (Кластер 0):**
- Умеренный уровень аренды: Вечерний период (возможно, с послеполуденной до вечера) характеризуется умеренным уровнем аренды велосипедов. В это время бизнес может продолжать предоставлять услуги велопроката, а также улучшать комфорт и безопасность пользователей.